
- 12023到2024年:前端发展趋势展望_前端工作发展
- 2揭秘【Cloud Native】安全:当灵活性与安全性碰撞时,我们该如何应对?_云原生安全
- 3音视频开发-ffmpeg介绍-系列一_ffmpeg开发
- 4内网渗透DC-2靶场通关(CTF)_ctf内网渗透题
- 5安防行业成巨头必争之地 一文梳理安防AI芯片产品与主要企业_安防芯片
- 6TSN(Temporal Segment Networks)和TSM(Temporal Shift Module)SlowFast对比
- 7c# 调用文心一言API_c# 文心一言
- 8内核添加对FT232芯片支持_kernel imx ft232r rule
- 9为什么大多数知名互联网公司都加班_互联网公司为啥都特忙
- 10基于FPGA DDR3设计之总结简介
本地化模型部署与应用_ollma模式
赞
踩
一、本地化部署的意义和 方法(WHY)
1.常见的大模型:ChatGPT、文心一言等,特点都是在线的模型,受限于网络和各种服务端限制
2.AI PC 强调使用本地的资源自由自主的运行大模型,本地化部署是核心
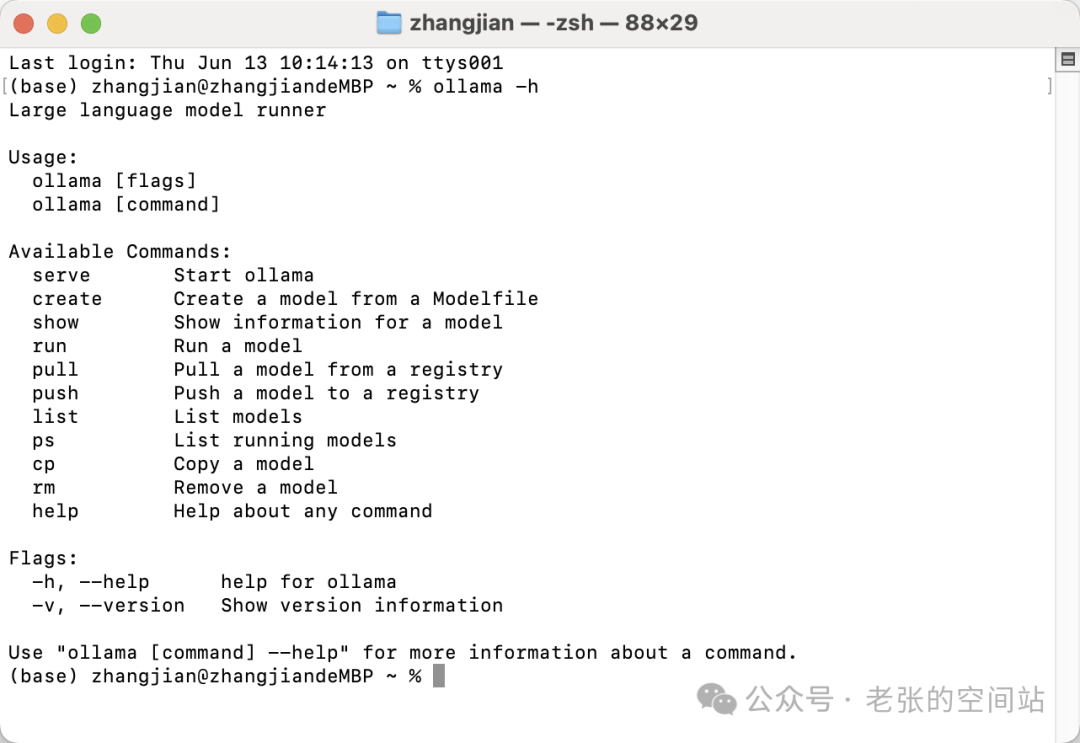
3.Ollama https://ollama.com/ 和LM Studio https://lmstudio.ai/

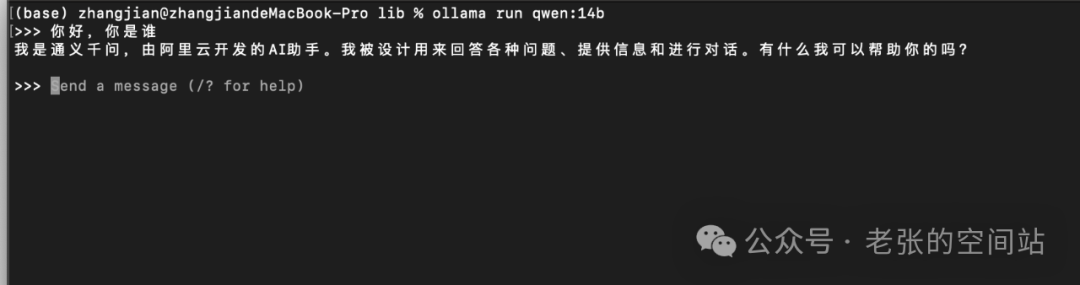
4.这里我们选择更加方便的ollama,运行第一个本地化模型,下载安装后ollama后,命令行运行:
ollama run qwen:14b
- 1
然后展开对话吧。
为什么是Ollma
无限接近docker的使用方法。带来方便的模型管理方式。
Ollama 支持的模型列表 https://ollama.com/library
不只是当前先进的语言模型,另外支持向量模型
二、本地化部署的模型能做什么(WHAT)
仅仅是运行一个模型么?本地化部署的意义:实现更强的功能
离大模型落地应用最近的工程化技术(RAG)
1.大模型自身的缺陷:模型滞后(时间落后)、模型幻觉(答非所问)、私有数据匮乏。
为解决这个问题:训练、微调、提示词功能、RAG分别从不同的角度,以不同的代价和效果来增强模型功能。
1. 训练模型 (Training a Model)
-
定义:从头开始训练一个模型,通常在大型数据集上进行。
-
优点:
-
可以针对特定任务从头开始学习。
-
能够获得与任务高度相关的模型表示。
-
缺点:
-
需要大量的标注数据和计算资源。
-
训练时间较长。
2. 微调模型 (Fine-tuning a Model)
-
定义:在预训练模型的基础上,针对特定任务进行额外的训练。
-
优点:
-
利用预训练模型的知识,减少所需数据和计算资源。
-
快速适应新任务。
-
缺点:
-
可能存在领域偏差,如果任务与预训练数据差异较大。
-
需要足够的领域特定数据进行有效微调。
3. 提示词工程 (Prompt Engineering)
-
定义:设计问题或任务的表述方式,以指导预训练模型生成期望的输出。
-
优点:
-
无需改变模型权重,通过调整输入来影响输出。
-
灵活,可以针对各种不同的任务快速设计提示词。
-
缺点:
-
需要创造性地设计有效的提示词,这可能需要试错。
-
对于复杂的任务,可能需要多个提示词或复杂的提示结构。
4. Retrieval-Augmented Generation (RAG)
-
定义:结合检索机制和序列生成模型,首先检索相关信息,然后基于检索到的内容生成输出。
-
优点:
-
结合了检索的广泛信息和生成模型的灵活性。
-
能够利用外部信息源,生成更准确、更丰富的回答。
-
缺点:
-
需要有效检索系统和生成模型的结合。
-
检索到的信息可能不总是相关,需要模型有能力筛选和整合信息。
综合对比:
-
资源需求:微调和提示词工程通常比从头训练模型需要更少的资源。RAG可能需要额外的检索系统资源。
-
适应性:微调和RAG能够较好地适应新任务,而从头训练模型和提示词工程则依赖于设计和现有数据。
-
灵活性:提示词工程提供了高度的灵活性,而RAG则在生成能力上提供了灵活性。
-
性能:从头训练的模型理论上可以提供最佳性能,但实际中微调、提示词工程和RAG通过利用预训练模型和外部信息,也能实现优异的性能。
在实际应用中,选择哪种方法取决于任务的具体需求、可用资源、数据集的大小和特性以及期望的部署速度。通常,这些方法可以结合使用,以实现最佳的性能和效率。
2.通过本地知识库的方式来弥补大模型的缺陷是目前流行的强化大模型的方向。
2.maxkb智能知识库系统,打造属于自己的AI助手
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data 1panel/maxkb
- 1
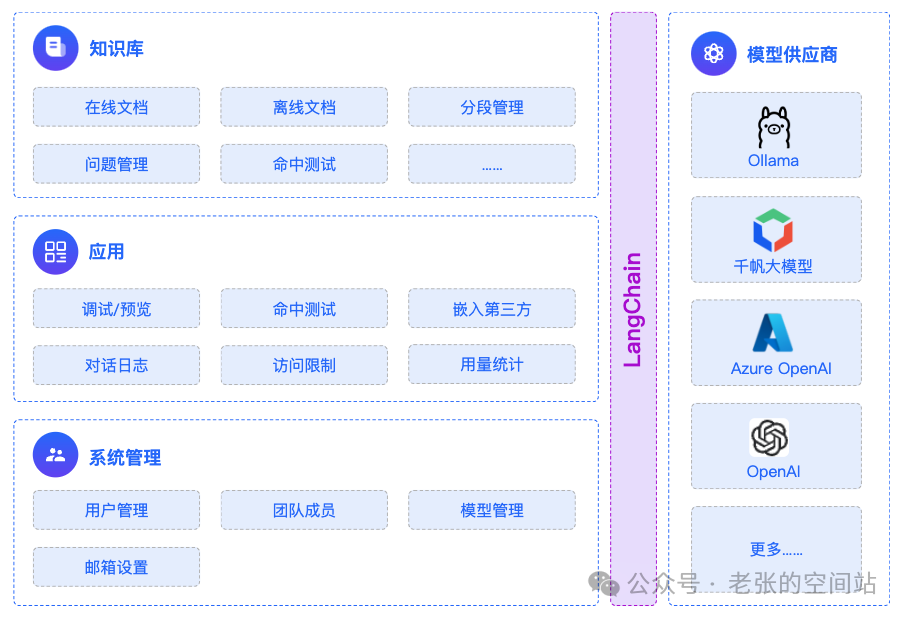
MaxKB的业务架构
4.引入本地知识库后,结构如下

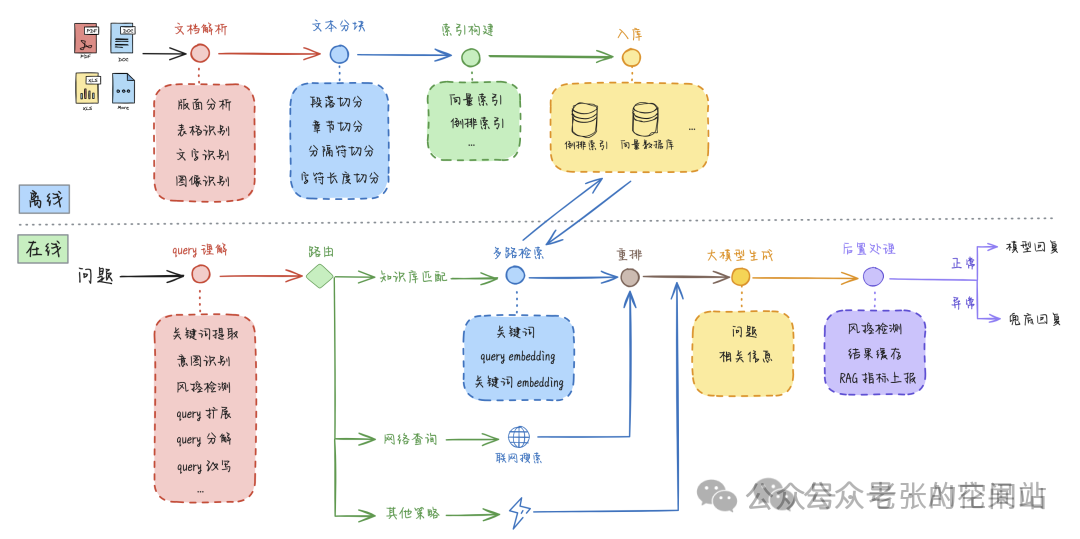
以上是MaxKB的设计原理,是一个典型的基于RAG的AI应用的架构范例
6.什么是RAG,检索增强生成(Retrieval-augmented Generation)

RAG的核心流程图
- 1
三、基于本地化部署应急群AI助手实现步骤(HOW)
1.实际应用:某电商网站的应急微信群,每天会收到大量的客服问题,有一部分是固定的回复方式,此部分就可以借助基于RAG的AI应用,辅助(甚至是自动完成回答)。
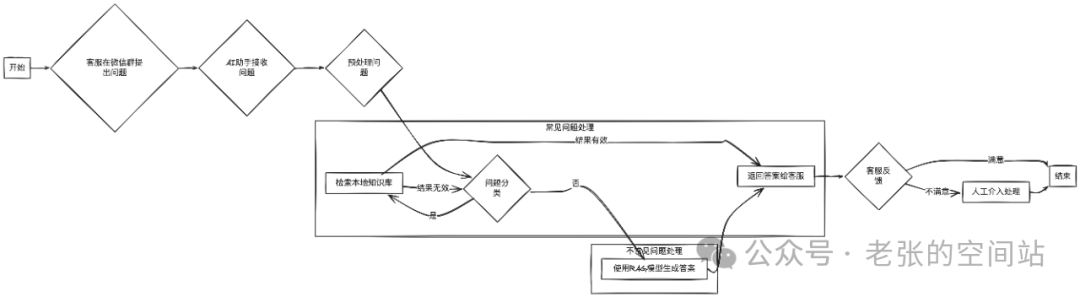
达成目标的准备条件:
A:一个充实的本地知识库
B:一个本地化运行的模型
C:一个由A和B组成的AI知识库系统
实现步骤:
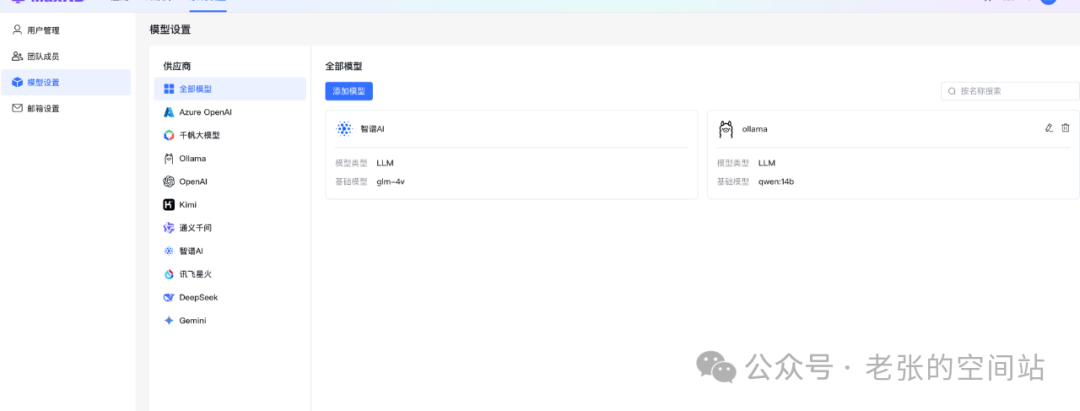
1.MaxKB配置ollama模型
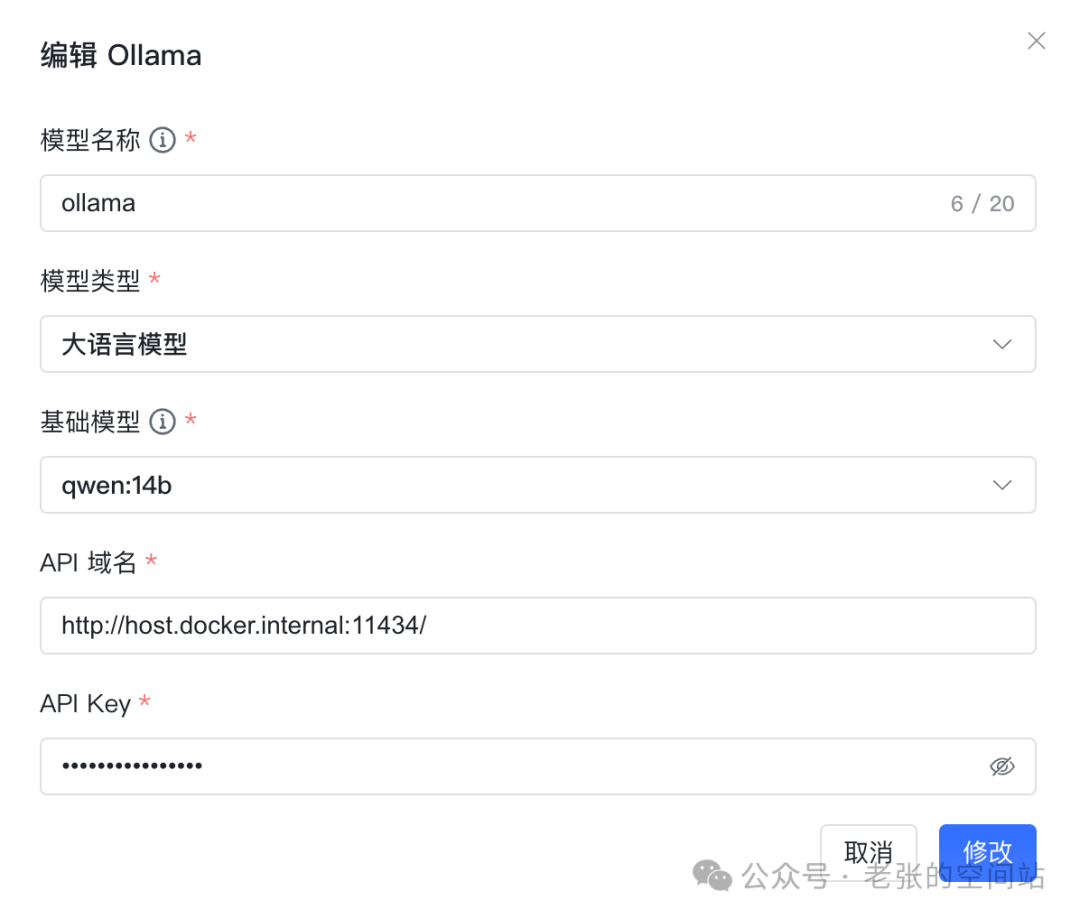
重点关注是API域名:http://host.docker.internal:11434/ MaxKB推荐安装方式为docker,所以外部连接需要指定宿主机。另外ollama提供对外接口能力,对应接口为11434。
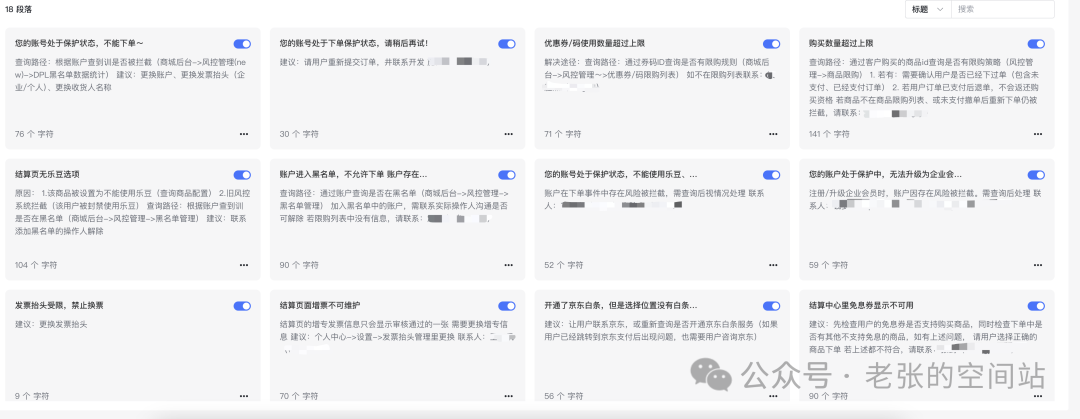
2.MaxKB本地知识库准备
可以导入各种文档也可以自行添加分段
3.MaxKB创建助手应用并完成测试
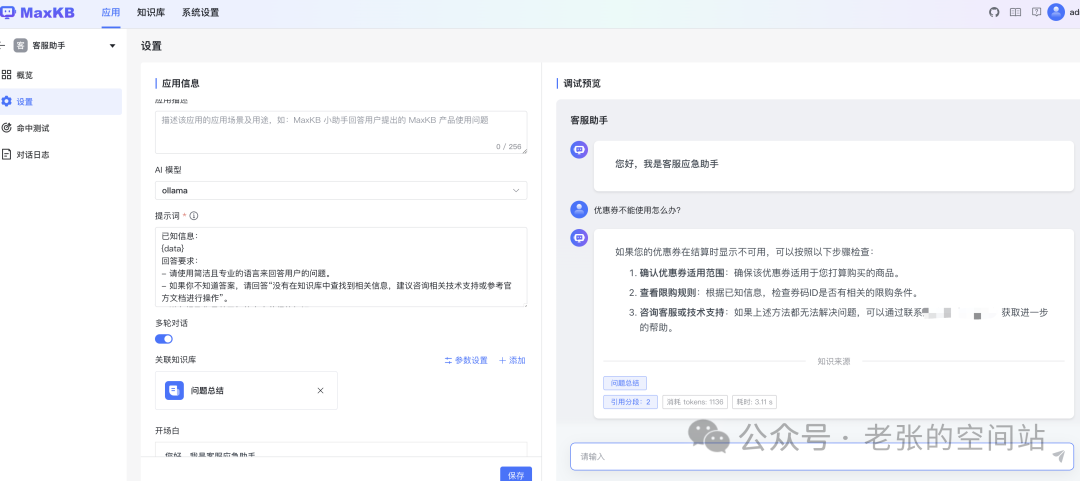
关注重点:
关联知识库
配置模型
提示词,提示词工程是AI应用的重要内容,好的提示词会引导并规范模型的输出。这方面的细节和优化需要展开为另外的课题单独讨论。
4.调试后发布
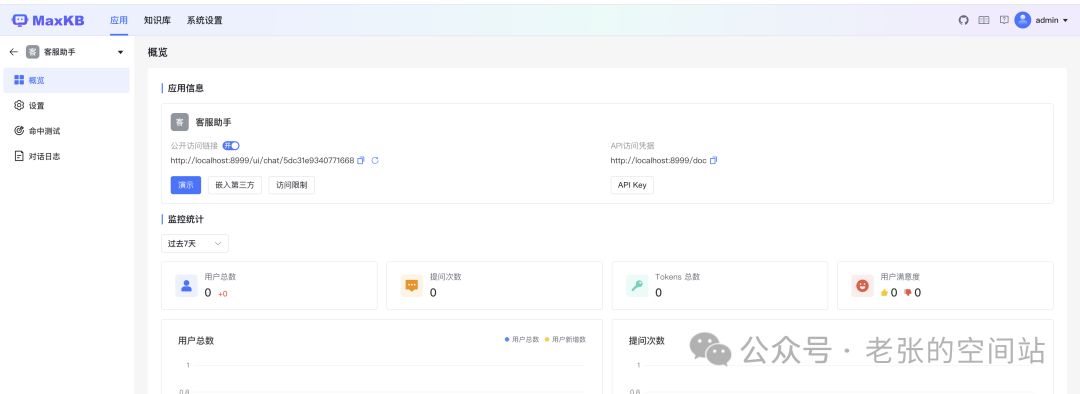
如何应用
发布后可以通过标准的REST API,供其他服务调用
http://localhost:8999/doc/
也可以通过嵌入方式直接对接原系统客服系统
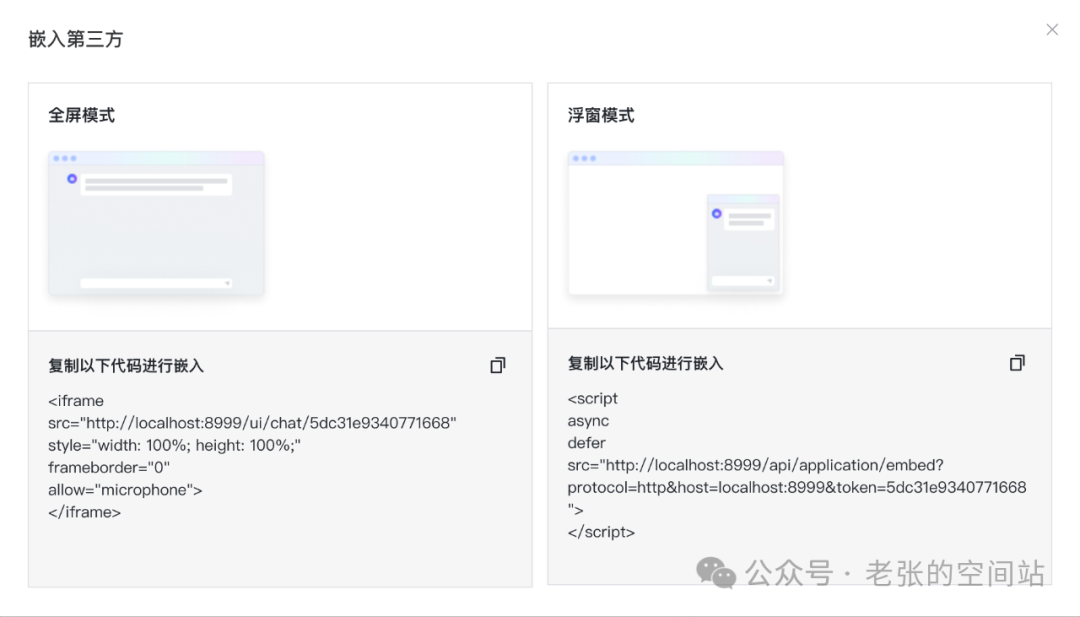
四、达成目标后哪里可以更好(WHERE)
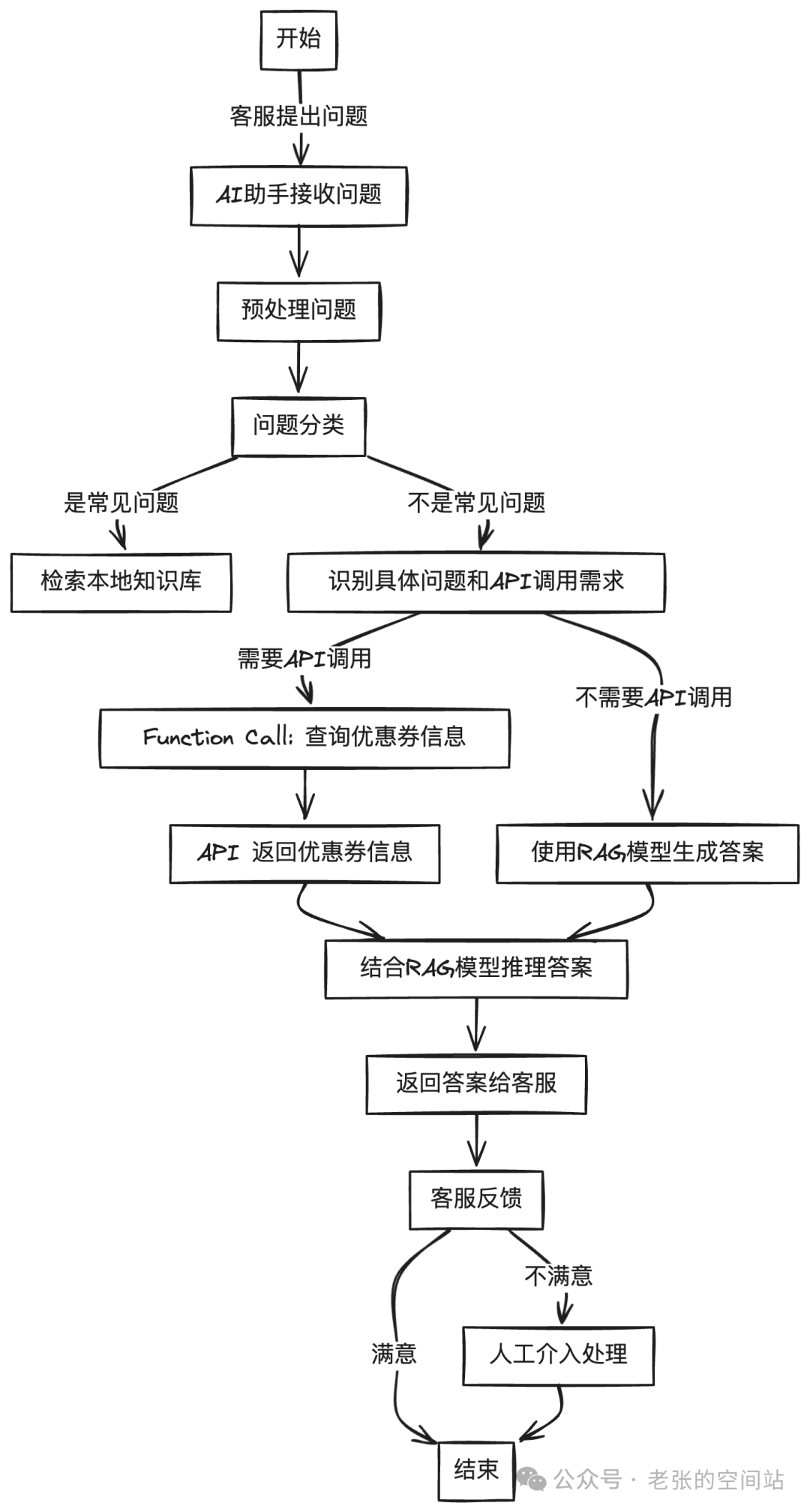
1.知识问答的局限性:基于知识库的问答,可以提高回答的准确性,但无法分析具体的问题,比如某某优惠券为什么不可用。简单的输出优惠券的使用规范,虽然正确并没有抓住核心问题。需要额外的实时查询数据支撑。
第一个Agent的组成:知识库、Function Call(实时调取接口能力)、流程搭建、模型推理
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

