
热门标签
热门文章
- 1ImportError: cannot import name ‘db‘ from partially initialized module ‘app‘ (most likely due to a c_importerror: cannot import name 'db' from partiall
- 2基于FPGA的数字信号处理(22)--进位保存加法器(Carry Save Adder, CSA)
- 3SQLserver2019基本操作
- 4Oracle中递归查询(START WITH……CONNECT BY……)
- 5leetcode刷题 242.有效的字母异位词_leetcode 第 242 题:给定两个字符串 s 和 t,编写一个函数来判断 t 是否是 s
- 6MySQL简单配置GTID_mysql-8.2.0-linux-glibc2.17-x86-64.tar.xz
- 7利用C++与Python调用千帆免费大模型,构建个性化AI对话系统_python 免费模型系统
- 82024年第五届“华数杯”全国大学生数学建模竞赛 A题详细思路+详细matlab代码+优秀论文范例
- 9ROS2 + 科大讯飞 初步实现机器人语音控制_ubuntu 机器人 语音控制
- 10基于 Paimon 的袋鼠云实时湖仓入湖实战剖析
当前位置: article > 正文
PaliGemma – 谷歌的最新开源视觉语言模型(一)_谷歌paligemma
作者:weixin_40725706 | 2024-08-02 03:13:19
赞
踩
谷歌paligemma
引言
PaliGemma 是谷歌推出的一款全新视觉语言模型。该模型能够处理图像和文本输入并生成文本输出。谷歌团队发布了三种类型的模型:预训练(PT)模型、混合(Mix)模型和微调(FT)模型,每种模型都有不同的分辨率和多种精度可供选择,方便用户使用。
所有模型都已在 Hugging Face Hub 模型库中发布,并附有模型卡和许可证,并与 transformers 集成。
什么是 PaliGemma?
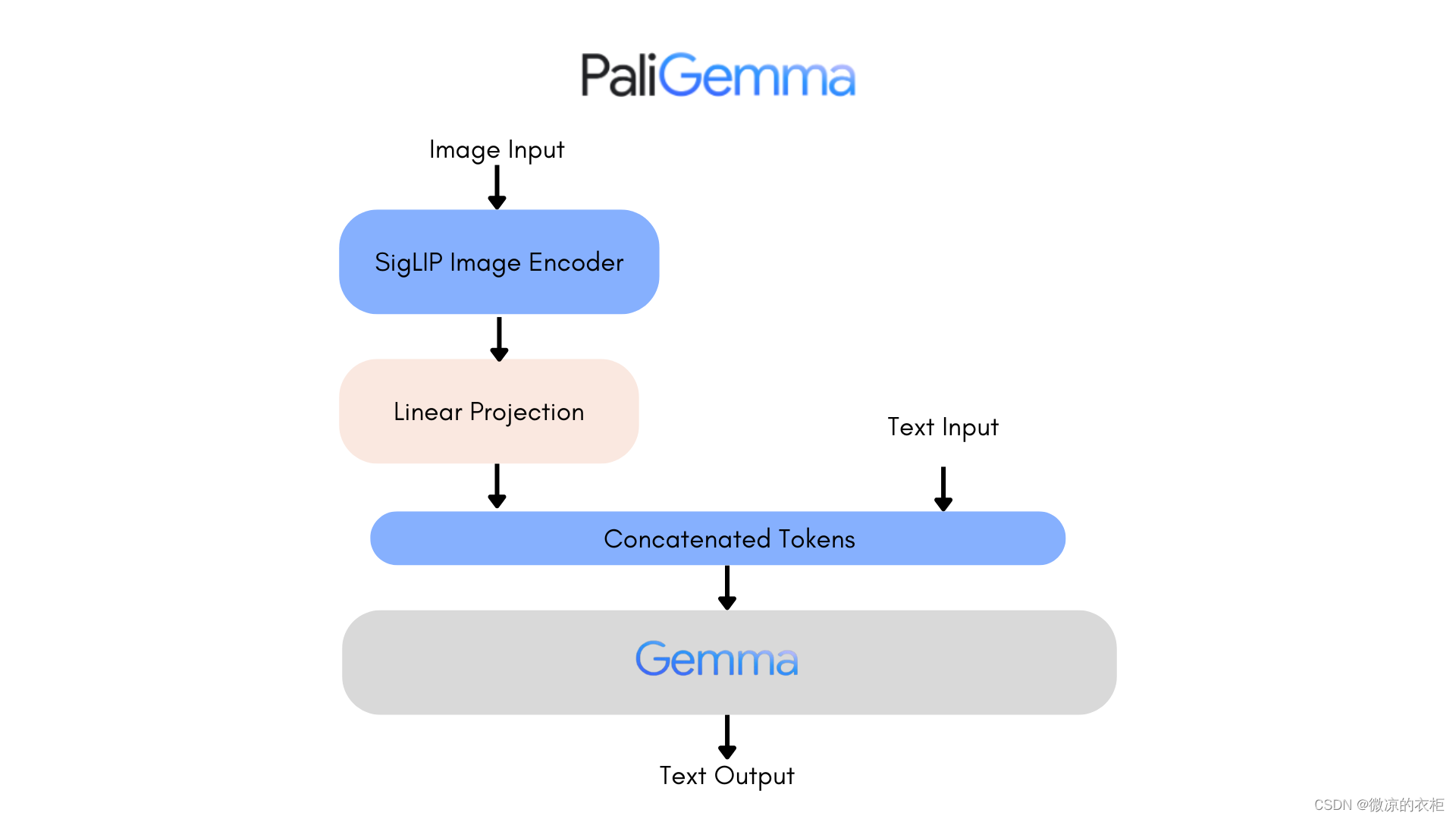
PaliGemma 是一组视觉语言模型,其架构由 SigLIP-So400m 作为图像编码器和 Gemma-2B 作为文本解码器组成。SigLIP 是一个先进的模型,能够理解图像和文本。像 CLIP 一样,它由图像和文本编码器共同训练。类似于 PaLI-3,PaliGemma 模型预训练于图像-文本数据集上,然后可以轻松地在下游任务上进行微调,例如图像字幕生成或引用分割。Gemma 是一个仅用于文本生成的解码器模型。通过使用线性适配器将 SigLIP 的图像编码器与 Gemma 结合,使 PaliGemma 成为一个强大的视觉语言模型。
PaliGemma 发布了三种类型的模型:
- PT 检查点:预训练模型,可以微调到下游任务。
- Mix 检查点:对多任务进行微调的 PT 模型。适用于带有自由文本提示的通用推理,仅供研究用途。
- FT 检查点:一组已经微调的模型,每个模型都专注于不同的学术基准。以多种分辨率提供,仅供研究用途。
这些模型提供三种不同的分辨率(224x224、448x448、896x896)和三种不同的精度(bfloat16、float16 和 float32)。每个模型库包含适用于给定分辨率和任务的检查点,并为每种可用精度提供三个修订版本。每个模型库的 main 分支包含 float32 检查点,而 bfloat16 和 float16 修订版本包含相应的精度版本。有适用于
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/916995
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

