
热门标签
热门文章
- 1ACl访问控制实验
- 2高等数学(无穷小与无穷大)
- 3Hadoop运行模式(五)、编写Hadoop集群常用脚本、Hadoop集群启停脚本、常用端口号说明、集群时间同步、时间服务器配置、其他机器配置_hadoop集群同步脚本
- 4AI绘画|Stable diffusion 4.8.7升级版来了!大尺度模型..._stable diffusion4.8.7
- 52023华为OD 面试手撕代码真题【实现备忘录系统】_华为od面试手撕代码
- 6ES的开发手册_es开发文档
- 7强化学习与自然语言处理的融合:实现人类级别的AI
- 8Ctfshow web入门 SSTI 模板注入篇 web361-web372 详细题解 全_ctfshow web361
- 9MongoDB创建和管理索引_mongodb创建文本索引
- 102846. 边权重均等查询
当前位置: article > 正文
一元线性模型用R语言进行拟合_r语言线性拟合
作者:weixin_40725706 | 2024-08-01 05:12:52
赞
踩
r语言线性拟合
一、一元线性模型介绍
一元线性模型的数学形式:
回归分析的主要任务就是通过n组样本观测值,对 进行估计。一般用
分别表示
的估计值,则称
为y关于x的一元线性经验回归方程。
二、R语言实现
以下为R语言实现一元线性模型拟合相关代码
- getwd()#查看工作目录
- setwd("文件绝对位置")#设置工作目录
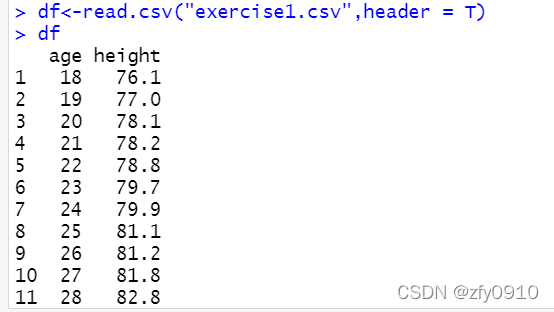
- df<-read.csv("exercise1.csv",header = T)#读取拟合数据文件
- library(ggplot2)#导入画图包
- ggplot(df,aes(x=age,y=height))+
- geom_point()#绘制散点图
- simple <- lm(height~age,data=df)
- summary(simple)
- confint(simple)#求解估计值的95%的置信区间
- pre=data.frame(age=30)#对age=30进行预测
- simple.pre=predict(simple,pre,interval = "prediction",level = 0.95)
- simple.pre
1、第一步读取文件数据(注意是csv文件,其他类型文件也能读取,但要修改读取文件的相关代码)
df<-read.csv("exercise1.csv",header = T)#读取拟合数据文件csv文件:
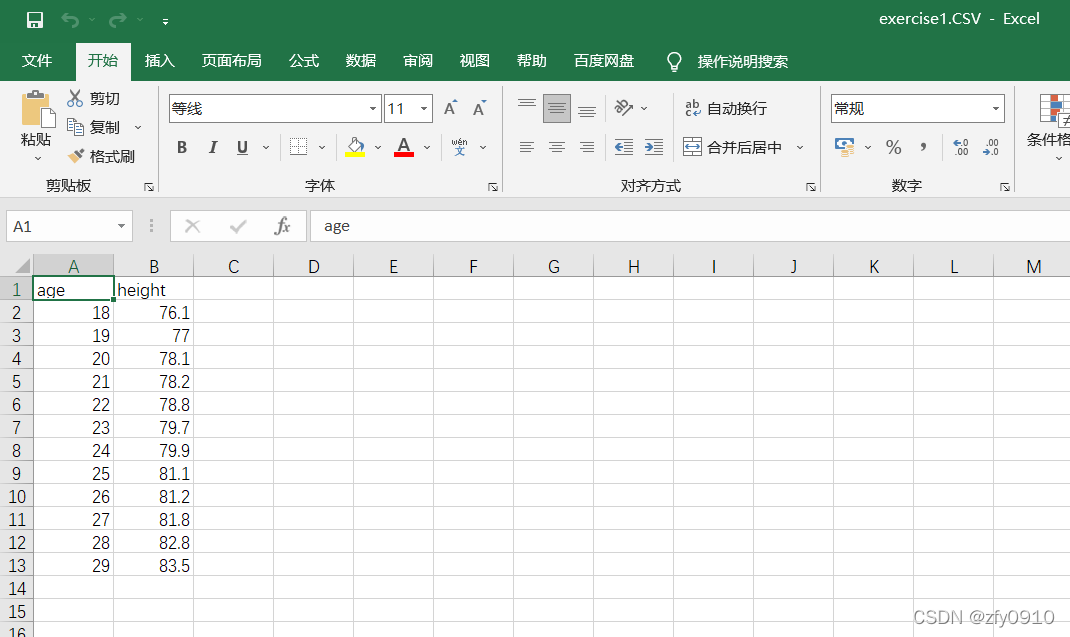
查看是否读取文件成功:
2、导入画图包
library(ggplot2)#导入画图包3、绘制散点图,验证数据是否有相关性
- ggplot(df,aes(x=age,y=height))+
- + geom_point()#绘制散点图
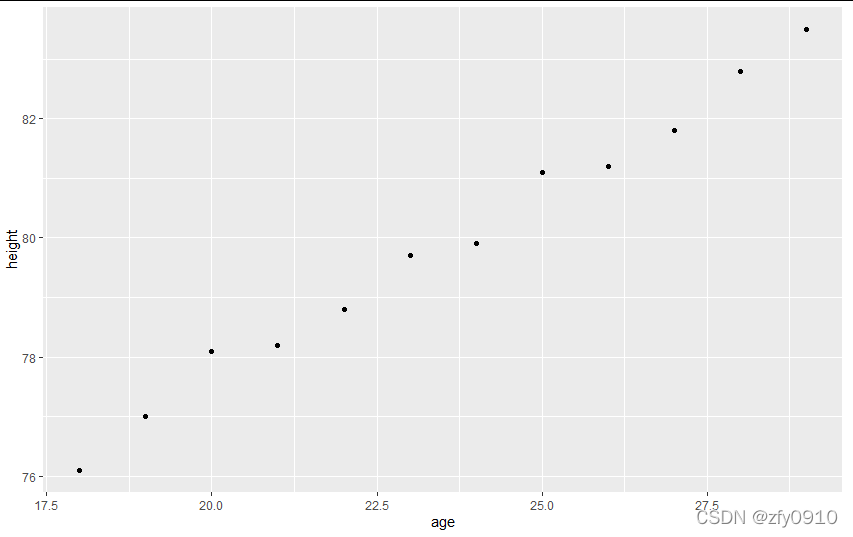
4、进行数据拟合,计算估计值并进行相关检验
- simple <- lm(height~age,data=df)
- summary(simple)
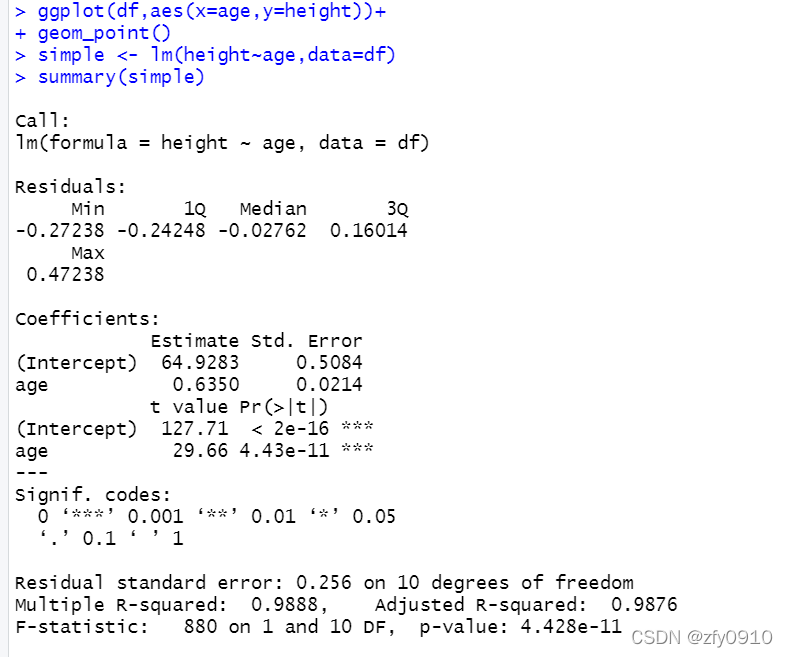
Residuals:为残差水平的五数概括,通过它我们可以了解残差的大概水平。
(Intercept):估计值,即估计截距
age :估计值,即估计斜率
Estimate:估计值
Std. Error:(standard error)估计的标准差的估计
t value:检验统计量t的值
Pr(>|t|):检验的P值,当P值小于显著性水平α的时候,模型效果显著
”***":代表模型效果非常显著,在“Signif. codes”中给出了解释
Residual standard error: 0.256 on 10 degrees of freedom:10自由度的残差标准差是0.256
Multiple R-squared:拟合优度,结果越接近于1,x和y的整体线性相关度越大;越接近于0,x和y的线性相关度越小。必须指出的是,当拟合优度为0时候只能说明x和y不是线性关系,但是x和y还可能是其他类型的相关关系
5、求解置信区间
confint(simple)#求解估计值的置信区间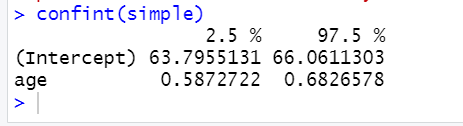
6、根据计算可以知道残差值,估计值大小,t检验以及p值,显著性水平。
最终模型求解为:
注意,一元线性回归在做预测的时,预测点的位置离样本点均值越近,预测越准确,离样本点均值越远,预测越不可靠。
7、预测
- pre=data.frame(age=30)#对age=30进行预测
- simple.pre=predict(simple,pre,interval = "prediction",level = 0.95)
- simple.pre

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/912446
推荐阅读
相关标签

