
- 1spark的使用_spark怎么用
- 2CRM客户管理系统源码PHP开发搭建_c.xsymz.icu
- 3Java高级特性之解析XML_编写如下结构的xml文档,具体值自行添加,至少添加两个学员的成绩信息
- 4cvte面试过程
- 5Manifest merger failed解决方法_caused by: java.lang.runtimeexception: manifest me
- 6显卡算力表-arch-架构_nvidia 算力查询arch
- 7_MSC_VER和VS版本对应
- 8python晋江文学城数据分析——简单的可视化(pyecharts)
- 9ei会议论文录用但不参加会议_会议论文有录用通知吗
- 10python文件的读写操作_python读写文件操作类型
Spark3.x入门到精通-阶段五(SparkStreaming详解原理&java&scala双语实战)_spark3 支持java语法嘛
赞
踩
SparkStreaming
简介
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
- 通过高级 API 构建应用程序,简单易用;
- 支持多种语言,如 Java,Scala 和 Python;
- 良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态;
- 能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合;
- Spark Streaming 可以从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,也支持自定义数据源。

DStream
Spark Streaming 提供称为离散流 (DStream) 的高级抽象,用于表示连续的数据流。 DStream 可以从来自 Kafka,Flume 和 Kinesis 等数据源的输入数据流创建,也可以由其他 DStream 转化而来。在内部,DStream 表示为一系列 RDD。
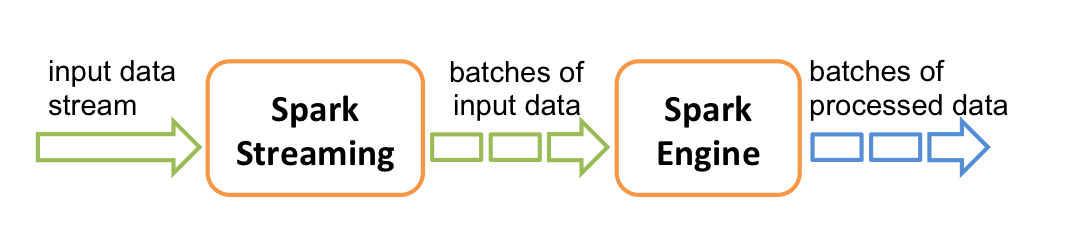
Spark & Storm & Flink
storm 和 Flink 都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
开始使用
hello world
java版本
- public class JavaHelloWord {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- //当使用Local模式启动Spark时,master URL必须为"local[n]",且"n"的值必须大于"receivers"的数量:
- //否则会出现Expecting 1 replicas with only 0 处理
- sparkConf.setMaster("local[2]")
- .setAppName("JavaHelloWord");
-
- //Durations.seconds(1)表示每一秒拉去一次数据
- //每一秒就是一个batch,每一个batch里面会有多个rdd
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9999);
-
- //对于RDD里面每一个元素处理,这里的每一个元素是一行数据,其实中间的操作就是对于RDD里面元素的处理
- JavaDStream<String> wordDStream = socketTextStream.flatMap(new FlatMapFunction<String, String>() {
- @Override
- public Iterator<String> call(String s) throws Exception {
- System.out.println(s);
- return Arrays.asList(s.split(" ")).iterator();
- }
- });
-
- JavaPairDStream<String, Integer> wordCountDStream = wordDStream.mapToPair(new PairFunction<String, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(String word) throws Exception {
- return new Tuple2<String, Integer>(word, 1);
- }
- });
-
- JavaPairDStream<String, Integer> resultDStream = wordCountDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- return v1 + v2;
- }
- });
-
- resultDStream.foreachRDD(
- //这里对于每一batch所有的RDD进行分布式的发送到集群其他机器上面去执行
- rdd->{
- rdd.foreach(new VoidFunction<Tuple2<String, Integer>>() {
- //对于RDD里面每一个分区里面的数据进行分布式计算
- @Override
- public void call(Tuple2<String, Integer> result) throws Exception {
- System.out.println(result);
- }
- });
- }
- );
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.close();
- }
- }

打包后执行(下面是client提交,就会在提交的机器上面启动Driver,那么打印的时候就会直接在提交的窗口打印数据)
- bin/spark-submit \
- --master yarn \
- --deploy-mode client \
- --driver-memory 512m \
- --executor-memory 512m \
- --executor-cores 1 \
- --num-executors 2 \
- --queue default \
- --class com.zhang.one.javasparkstreaming.JavaHelloWord \
- /home/bigdata/spark/spark-yarn/original-sparkstart-1.0-SNAPSHOT.jar
下面用cluster提交(启动的Driver在集群的随机一台启动)
- bin/spark-submit \
- --master yarn \
- --deploy-mode cluster \
- --driver-memory 512m \
- --executor-memory 512m \
- --executor-cores 1 \
- --num-executors 2 \
- --queue default \
- --class com.zhang.one.javasparkstreaming.JavaHelloWord \
- /home/bigdata/spark/spark-yarn/original-sparkstart-1.0-SNAPSHOT.jar
下面是查看输出数据的步骤

scala版本
- object ScalaStreaingWc {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- conf.setAppName("ScalaStreaingWc")
- .setMaster("local[2]")
-
- val sparkStreaming = new StreamingContext(conf, Seconds(1))
- sparkStreaming.socketTextStream("master",9999)
- .flatMap(_.split(" "))
- .map((_,1))
- .reduceByKey(_+_)
- .foreachRDD(rdd=>rdd.foreach(println))
-
- sparkStreaming.start()
- sparkStreaming.awaitTermination()
- sparkStreaming.stop()
- }
- }
SparkStreaming用Kafka作为数据源
Receiver模式(由于这种模式在spark3.x没有了所以就不写代码了)
关于上面为什么必须用local[*]图解,因为sparkstreaming会一直占用资源,必须有足够资源的前提它才能启动,下面以Reciver模式原理图解
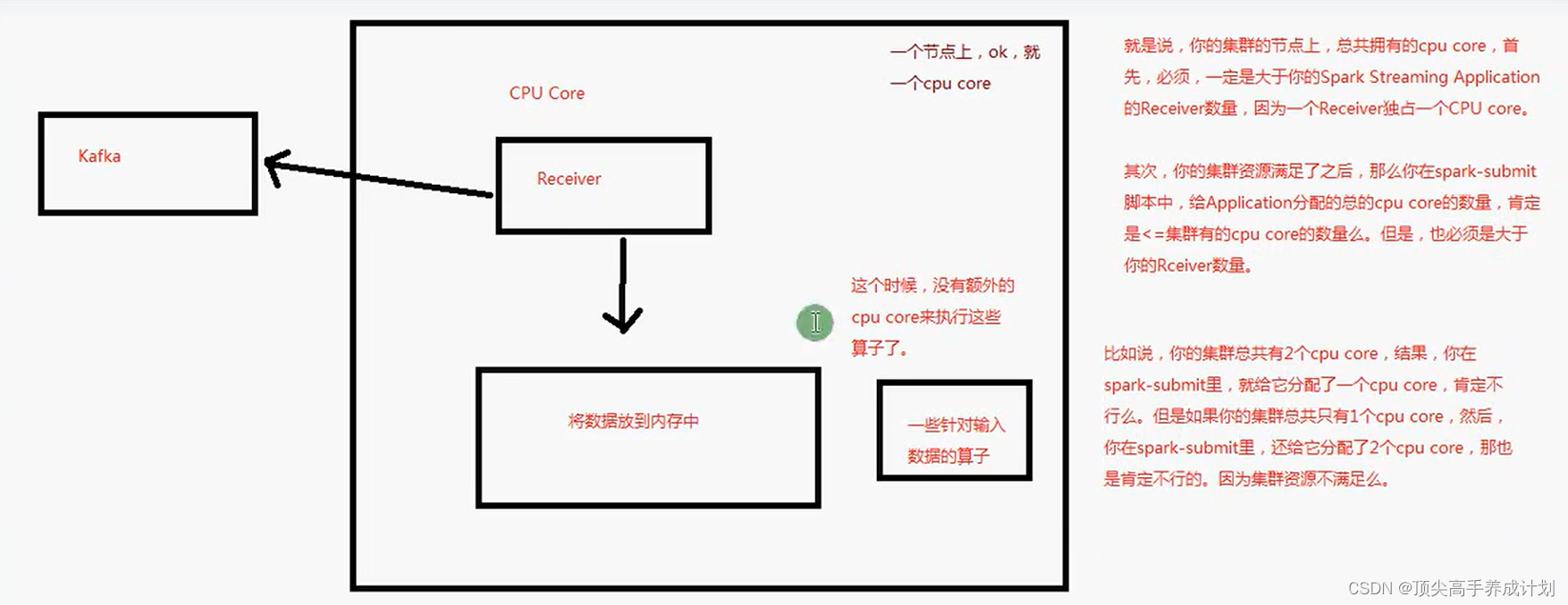
Direct模式
java&scala双语实战
- 有点kafka的partition和RDD的partiton有一一对应的关系
- 能够保证spark仅仅消费一次kafka的数据
现在kafka创建对应的topic
./kafka-topics.sh --bootstrap-server master:9092 --create --topic spark-streaming-topic --partitions 2 --replication-factor 2创建一个生产者
./kafka-console-producer.sh --broker-list master:9092 --topic spark-streaming-topicjava版本
- public class JavaKafkaDirectStream {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- //对应kafka里面的分区一一对应
- sparkConf.setMaster("local[2]")
- .setAppName("JavaKafkaDirectStream");
-
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- Map<String, Object> params = new HashMap<>();
- params.put("bootstrap.servers","master:9092");
- params.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
- params.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
- params.put("group.id","spark-streaming-group");
- params.put("auto.offset.reset","latest");
- params.put("enable.auto.commit",true);
- List<String> topics = Arrays.asList("spark-streaming-topic");
- JavaInputDStream<ConsumerRecord<String, String>> kafkaDStream = KafkaUtils.createDirectStream(
- javaStreamingContext,
- LocationStrategies.PreferConsistent(),
- ConsumerStrategies.Subscribe(topics, params));
-
- JavaDStream<String> kafkaValueDStream = kafkaDStream.map((Function<ConsumerRecord<String, String>, String>) v1 -> v1.value());
- JavaDStream<String> woldDStream = kafkaValueDStream.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(s.split(" ")).iterator());
- JavaPairDStream<String, Integer> wordCountDStream = woldDStream.mapToPair((PairFunction<String, String, Integer>) s -> new Tuple2<String, Integer>(s, 1));
- JavaPairDStream<String, Integer> resultDStream = wordCountDStream.reduceByKey((Function2<Integer, Integer, Integer>) (v1, v2) -> v1 + v2);
- resultDStream.foreachRDD(rdd->rdd.foreach((VoidFunction<Tuple2<String, Integer>>) result -> System.out.println(result)));
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
scala版本
- object ScalaKafkaDirectStream {
- def main(args: Array[String]): Unit = {
-
- val sparkConf = new SparkConf().setAppName("ScalaKafkaDirectStream").setMaster("local[2]")
- val streamingContext = new StreamingContext(sparkConf, Seconds(5))
-
- val kafkaParams = Map[String, Object](
- /*
- * 指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找其他 broker 的信息。
- * 不过建议至少提供两个 broker 的信息作为容错。
- */
- "bootstrap.servers" -> "master:9092",
- /*键的序列化器*/
- "key.deserializer" -> classOf[StringDeserializer],
- /*值的序列化器*/
- "value.deserializer" -> classOf[StringDeserializer],
- /*消费者所在分组的 ID*/
- "group.id" -> "spark-streaming-group",
- /*
- * 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
- * latest: 在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
- * earliest: 在偏移量无效的情况下,消费者将从起始位置读取分区的记录
- */
- "auto.offset.reset" -> "latest",
- /*是否自动提交*/
- "enable.auto.commit" -> (true: java.lang.Boolean)
- )
-
- /*可以同时订阅多个主题*/
- val topics = Array("spark-streaming-topic")
- val stream = KafkaUtils.createDirectStream[String, String](
- streamingContext,
- /*位置策略*/
- /**
- * 位置策略
- * Spark Streaming 中提供了如下三种位置策略,用于指定 Kafka 主题分区与 Spark 执行程序 Executors 之间的分配关系:
- PreferConsistent : 它将在所有的 Executors 上均匀分配分区;
- PreferBrokers : 当 Spark 的 Executor 与 Kafka Broker 在同一机器上时可以选择该选项,它优先将该 Broker 上的首领分区分配给该机器上的 Executor;
- PreferFixed : 可以指定主题分区与特定主机的映射关系,显示地将分区分配到特定的主机.
- */
- PreferConsistent,
- /*订阅主题*/
- /**
- *
- * @param 需要订阅的主题的集合
- * @param Kafka 消费者参数
- * @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的
- * def Subscribe[K, V](
- topics: ju.Collection[jl.String],
- kafkaParams: ju.Map[String, Object],
- offsets: ju.Map[TopicPartition, jl.Long]): ConsumerStrategy[K, V] = { ... }
- */
- Subscribe[String, String](topics, kafkaParams)
- )
-
- /*打印输入流*/
- stream.map(_.value())
- .flatMap(_.split(" "))
- .map((_,1))
- .reduceByKey(_+_)
- .foreachRDD(rdd=>rdd.foreach(println))
-
- streamingContext.start()
- streamingContext.awaitTermination()
- }
- }
常用的transform使用
updateStateByKey
- 对于每一个key维护一个状态
- 注意使用它的时候必须开始checkpoint(因为如果数据丢失了,还可以在磁盘中恢复数据)
java版本
- public class JavaUpdateStateByKey {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- sparkConf.setMaster("local[2]")
- .setAppName("JavaUpdateStateByKey");
- //解决权限问题
- System.setProperty("HADOOP_USER_NAME","bigdata");
-
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- javaStreamingContext.checkpoint("hdfs://master:8020/sparkstreamingcheckpoing");
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9998);
-
- JavaDStream<String> wordDStream = socketTextStream.flatMap(new FlatMapFunction<String, String>() {
- @Override
- public Iterator<String> call(String s) throws Exception {
- return Arrays.asList(s.split(" ")).iterator();
- }
- });
-
- //装换成key,value操作的
- JavaPairDStream<String, Integer> wordCountDStream = wordDStream.mapToPair(new PairFunction<String, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(String s) throws Exception {
- return new Tuple2<String, Integer>(s, 1);
- }
- });
-
- //对于每一个key维护一个状态
- wordCountDStream.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>(){
- @Override
- public Optional<Integer> call(List<Integer> newValues, Optional<Integer> state) throws Exception {
- Integer initData=0;
- //如果有state了,就拿出这个state的值
- if(state.isPresent()){
- initData=state.get();
- }
- //这里对于每一batch的新的数据对于state进行累加
- for (Integer newValue : newValues) {
- initData+=newValue;
- }
- return Optional.of(initData);
- }
- }).foreachRDD(rdd->rdd.foreach((VoidFunction<Tuple2<String, Integer>>) result -> System.out.println(result)));
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
scala版本
- object ScalaUpdateStateByKey {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- conf.setMaster("local[2]")
- .setAppName("ScalaUpdateStateByKey")
- //解决权限问题(主要一点要在得到sparkStreaming前配置)
- System.setProperty("HADOOP_USER_NAME", "bigdata")
- val sparkStreaming = new StreamingContext(conf, Seconds(1))
- sparkStreaming.checkpoint("hdfs://master:8020/scalasparkstreamingcheckpoing");
-
- sparkStreaming.socketTextStream("master",9998)
- .flatMap(_.split(" "))
- .map((_,1))
- .updateStateByKey((values:Seq[Int],state:Option[Int])=>{
- var res: Int = state.getOrElse(0)
- for (elem <- values) {
- res=res+elem
- }
- Option(res)
- }).foreachRDD(rdd=>rdd.foreach(println))
-
- sparkStreaming.start()
- sparkStreaming.awaitTermination()
- sparkStreaming.stop()
- }
- }
transform
使用它是因为DStream只能和DStream执行join操作,当我们想和其他的RDD使用的时候就需要用到它
下面我们写一个事实黑名单点击过滤案例
java版本实现
- public class JavaBlackList {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- sparkConf.setMaster("local[2]")
- .setAppName("JavaHelloWord");
-
- //定义要过滤的黑名单的数据
- List<Tuple2<String, Boolean>> blackList = new ArrayList<>();
- blackList.add(new Tuple2<>("zhangsan",true));
- //得到每一批的数据的时候,我们为了测试把批次间隔调大一点
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(5));
- JavaPairRDD<String, Boolean> blackListRDD = javaStreamingContext.sparkContext().parallelizePairs(blackList);
-
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9998);
- JavaPairDStream<String, String> socketTupleUserMsg = socketTextStream.mapToPair(new PairFunction<String, String, String>() {
- @Override
- public Tuple2<String, String> call(String s) throws Exception {
- String[] socketTextStringItem = s.split(" ");
- //因为假的输入的是name msg的形式
- String userName = socketTextStringItem[0];
- String msg = socketTextStringItem[1];
- return new Tuple2<String, String>(userName, msg);
- }
- });
-
- //第一个参数是装换成的RDD,第二个是要返回什么RDD
- socketTupleUserMsg.transform(new Function<JavaPairRDD<String, String>, JavaRDD<String>>() {
- @Override
- public JavaRDD<String> call(JavaPairRDD<String, String> socketKeyValue) throws Exception {
- //对于事实得到的用户数据和黑名单的数据进行左外连接的操作,
- JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> allUser = socketKeyValue.leftOuterJoin(blackListRDD);
- //过滤出黑名单的数据
- JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> filterUser = allUser.filter(new Function<Tuple2<String, Tuple2<String, Optional<Boolean>>>, Boolean>() {
- @Override
- public Boolean call(Tuple2<String, Tuple2<String, Optional<Boolean>>> v1) throws Exception {
- //这里是Optional的特殊处理,isPresent表示这个Optional是否有值
- //get()如果有值,并且左外连接以后匹配到了名字那么就是黑名单的数据我们直接过滤掉
- if (v1._2._2.isPresent() && v1._2._2.get()) {
- return false;
- }
- return true;
- }
- });
-
- //对于连接的数据,我们只要之前输入的数据就行,那么就通过map进行装换处理
-
- return filterUser.map(new Function<Tuple2<String, Tuple2<String, Optional<Boolean>>>, String>() {
- @Override
- public String call(Tuple2<String, Tuple2<String, Optional<Boolean>>> v1) throws Exception {
- return v1._2._1;
- }
- });
- }
- //得到最后过滤出来的结果
- }).foreachRDD(rdd->rdd.foreach(new VoidFunction<String>() {
- @Override
- public void call(String res) throws Exception {
- System.out.println(res);
- }
- }));
-
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
scala版本实现
- object ScalaBlackList {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- conf.setMaster("local[2]")
- .setAppName("ScalaBlackList")
-
- //定义用户黑名单
- val blackUser = List(
- ("a", true)
- )
- val sparkStreaming = new StreamingContext(conf, Seconds(2))
- val context: SparkContext = sparkStreaming.sparkContext
- val blackUserRDD: RDD[(String, Boolean)] = context.parallelize(blackUser)
-
- val socketDS: ReceiverInputDStream[String] = sparkStreaming.socketTextStream("master", 9998)
- socketDS.map(item => {
- val socketText: Array[String] = item.split(" ")
- val userName: String = socketText(0)
- val msg: String = socketText(1)
- (userName, msg)
- }).transform(rdd => {
- val allUser: RDD[(String, (String, Option[Boolean]))] = rdd.leftOuterJoin(blackUserRDD)
- //对于所有的数据进行过滤
- allUser.filter(item=>{
- //表示在黑名单里面没有数据的时候就是填充一个false作为默认值
- !item._2._2.getOrElse(false)
- }).map(item=>{
- (item._1,item._2._1)
- })
- }).foreachRDD(rdd=>rdd.foreach(println))
-
- sparkStreaming.start()
- sparkStreaming.awaitTermination()
- sparkStreaming.stop()
- }
- }
window(滑动窗口)
案例
实时统计每10秒统计最近60秒的最多的搜索词top3
java版本
- public class JavaWinddow {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- sparkConf.setAppName("JavaWinddow")
- .setMaster("local[2]");
-
- //每一秒得到一份batch数据,里面其实一堆RDD
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9998);
- JavaPairDStream<String, Integer> wordCount = socketTextStream.mapToPair(new PairFunction<String, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(String s) throws Exception {
- return new Tuple2<String, Integer>(s, 1);
- }
- });
-
- //这里使用窗口的特性,每10秒统计最近60秒的数据,也就是上面的数据会一直累积,到达条件以后往下面执行
- //第一个是reduceByKey的操作函数,
- // 第二个值是窗口大小
- //第三个值是滑动距离
- JavaPairDStream<String, Integer> reduceWindowValue = wordCount.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- return v1 + v2;
- }
- }, Durations.seconds(60), Durations.seconds(10));
-
- JavaPairDStream<Integer, String> integerStringJavaPairDStream = reduceWindowValue.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
- @Override
- public Tuple2<Integer, String> call(Tuple2<String, Integer> initData) throws Exception {
- return new Tuple2<Integer, String>(initData._2, initData._1);
- }
- });
- //装换成RDD使用RDD的操作,对于60秒的数据进行排序
- JavaPairDStream<Integer, String> sortDS = integerStringJavaPairDStream.transformToPair(rdd -> rdd.sortByKey(false));
-
- sortDS.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(Tuple2<Integer, String> res) throws Exception {
- return new Tuple2<String, Integer>(res._2, res._1);
- }
- }).foreachRDD(rdd->rdd.take(3).forEach(
- item->{
- System.out.println(item);
- }
- ));
-
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
scala版本
- object ScalaWindow {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- conf.setAppName("ScalaWindow")
- .setMaster("local[2]")
-
- val sparkStreaming = new StreamingContext(conf, Seconds(1))
- val socketDS: ReceiverInputDStream[String] = sparkStreaming.socketTextStream("master", 9998)
- val reduceRDD: DStream[(String, Int)] = socketDS.map((_, 1))
- .reduceByKeyAndWindow((num1:Int,num2:Int)=>num2+num1, Seconds(60), Seconds(10))
-
- reduceRDD.map(item=>{
- (item._2,item._1)
- }).transform(rdd=>rdd.sortByKey(false)).foreachRDD(rdd=>rdd.take(3).foreach(println))
-
- sparkStreaming.start()
- sparkStreaming.awaitTermination()
- sparkStreaming.stop()
- }
- }
foreachRDD详解
案例
实时处理10秒统计一次最近60秒的搜索按搜索的次数倒叙
- public class JavaWinddow {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- sparkConf.setAppName("JavaWinddow")
- .setMaster("local[2]");
-
- //每一秒得到一份batch数据,里面其实一堆RDD
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9998);
- JavaPairDStream<String, Integer> wordCount = socketTextStream.mapToPair(new PairFunction<String, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(String s) throws Exception {
- return new Tuple2<String, Integer>(s, 1);
- }
- });
-
- //这里使用窗口的特性,每10秒统计最近60秒的数据,也就是上面的数据会一直累积,到达条件以后往下面执行
- //第一个是reduceByKey的操作函数,
- // 第二个值是窗口大小
- //第三个值是滑动距离
- JavaPairDStream<String, Integer> reduceWindowValue = wordCount.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- return v1 + v2;
- }
- }, Durations.seconds(60), Durations.seconds(10));
-
- JavaPairDStream<Integer, String> integerStringJavaPairDStream = reduceWindowValue.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
- @Override
- public Tuple2<Integer, String> call(Tuple2<String, Integer> initData) throws Exception {
- return new Tuple2<Integer, String>(initData._2, initData._1);
- }
- });
- //装换成RDD使用RDD的操作,对于60秒的数据进行排序
- JavaPairDStream<Integer, String> sortDS = integerStringJavaPairDStream.transformToPair(rdd -> rdd.sortByKey(false));
-
- sortDS.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(Tuple2<Integer, String> res) throws Exception {
- return new Tuple2<String, Integer>(res._2, res._1);
- }
- }).foreachRDD(rdd -> rdd.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() {
- @Override
- public void call(Iterator<Tuple2<String, Integer>> res) throws Exception {
- //得到连接,每一个连接处理一个分区的数据
- Jedis jedis = RedisHelper.getJedis();
- Map<String, String> resMap = new HashMap<>();
- while (res.hasNext()) {
- Tuple2<String, Integer> value = res.next();
- String oldValue = resMap.get(value._1);
- if (oldValue == null) {
- oldValue = "0";
- }
- Integer newValue = Integer.valueOf(oldValue) + value._2;
- resMap.put(value._1, newValue + "");
- }
- if(!resMap.isEmpty()){
- jedis.del("hotWordTop3");
- jedis.hset("hotWordTop3", resMap);
- }
- //把连接还回去
- RedisHelper.removeJedis(jedis);
- }
- }));
-
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
放入redis
- <dependency>
- <groupId>redis.clients</groupId>
- <artifactId>jedis</artifactId>
- <version>3.1.0</version>
- </dependency>
如果没有redis想快点使用的话下面提供docker安装
- sudo yum install docker
- sudo systemctl start docker
- sudo systemctl enable docker
时间同步操作(有些时间不一样会有问题)
- sudo yum install -y ntpdate
- sudo ntpdate 120.24.81.91
-
- #冲突时使用这个
- sudo sudo systemctl stop ntp
镜像加速(由于自己提供的经常过期,可以自己去找下)
- sudo systemctl daemon-reload
- sudo systemctl restart docker
启动一个redis容器并且开机自启
sudo docker run -itd --name spark-redis -p 6379:6379 --restart=always redis:6.0创建一个redis的工具类
- public class RedisHelper {
-
- private static JedisPool jedisPool=null;
-
- static {
-
- GenericObjectPoolConfig config = new GenericObjectPoolConfig();
- config.setMaxIdle(10);
- config.setMaxTotal(20);
- config.setMinIdle(5);
- jedisPool = new JedisPool(config, "node1");
- }
-
- public static Jedis getJedis() {
- Jedis resource = jedisPool.getResource();
- return resource;
- }
-
- public static void removeJedis(Jedis jedis){
- jedis.close();
- }
- }
结合SparkSql实战
案例要求
每10秒统计最近60秒用户点击top3的数据
- public class JavaStreamingSql {
- public static void main(String[] args) throws InterruptedException {
- SparkConf sparkConf = new SparkConf();
- sparkConf.setAppName("JavaStreamingSql")
- .setMaster("local[2]");
- //第一步得到sparkStreaming,我们可以认为DStream就是1s的一个RDD,但是事件上是产生了一个batch的数据
- //一个batch里面有很多RDD
- JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
- JavaReceiverInputDStream<String> socketTextStream = javaStreamingContext.socketTextStream("master", 9998);
-
- //得到的点击数据进行map
- JavaPairDStream<String, Integer> wordCountDStream = socketTextStream.mapToPair(new PairFunction<String, String, Integer>() {
- //得到的数据是每个用户名
- @Override
- public Tuple2<String, Integer> call(String userName) throws Exception {
- return new Tuple2<String, Integer>(userName, 1);
- }
- });
-
- //第二步开窗并求聚合操作
- JavaPairDStream<String, Integer> reduceByKeyAndWindowDStream = wordCountDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- return v1 + v2;
- }
- }, Durations.seconds(60), Durations.seconds(10));
-
- //第三步根据得到的RDD使用SparkSql进行分析
- reduceByKeyAndWindowDStream.foreachRDD(rdd->{
- //根据RDD得到Row
- JavaRDD<Row> userClickRowCount = rdd.map(new Function<Tuple2<String, Integer>, Row>() {
- @Override
- public Row call(Tuple2<String, Integer> rddItem) throws Exception {
- return RowFactory.create(
- rddItem._1,
- rddItem._2
- );
- }
- });
-
- //定义Row的元数据
- List<StructField> rowMeta = new ArrayList<>();
- rowMeta.add(DataTypes.createStructField("userName",DataTypes.StringType,true));
- rowMeta.add(DataTypes.createStructField("clickNum",DataTypes.IntegerType,true));
- StructType rowMetastructType = DataTypes.createStructType(rowMeta);
-
- //使得Row和structType建立联系
- SQLContext sqlContext = new SQLContext(javaStreamingContext.sparkContext());
- Dataset<Row> userClickDataFrame = sqlContext.createDataFrame(userClickRowCount, rowMetastructType);
- userClickDataFrame.registerTempTable("userClickData");
-
- //这里开始对于每10秒统计最近60秒的数据
- Dataset<Row> res = sqlContext.sql(
- "select userName,clickNum from " +
- "(" +
- "select userName,clickNum,row_number() over (order by clickNum desc) as rank from " +
- "userClickData" +
- ") where rank<=3"
- );
-
- res.show();
- });
-
- javaStreamingContext.start();
- javaStreamingContext.awaitTermination();
- javaStreamingContext.stop();
- }
- }
输出的结果是
- +--------+--------+
- |userName|clickNum|
- +--------+--------+
- | c| 28|
- | a| 19|
- | f| 12|
- +--------+--------+
scala版本
- object ScalaSparkStreamSql {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- conf.setAppName("ScalaSparkStreamSql")
- .setMaster("local[2]")
-
- val sparkStreaming = new StreamingContext(conf, Seconds(1))
- sparkStreaming.socketTextStream("master", 9998)
- .map((_, 1))
- //每10秒得到最近60秒的数据,60是窗口的大小,10是滑动的长度
- .reduceByKeyAndWindow((num1: Int, num2: Int) => {
- num1 + num2
- }, Seconds(60), Seconds(10))
- .foreachRDD(rdd => {
- //得到Row
- val userClickRow: RDD[Row] = rdd.map(
- mapItem => {
- Row(mapItem._1, mapItem._2)
- }
- )
- //得到数据
- val userClickStructTyoe: StructType = StructType(
- Array(
- StructField("userName", DataTypes.StringType, true),
- StructField("clickNum", DataTypes.IntegerType, true)
- )
- )
-
- //得到DataFrame
- val sparkSession: SparkSession = SparkSession
- .builder()
- .config(conf)
- .getOrCreate()
-
- //开始查询数据
- val userClickDataFrame: DataFrame = sparkSession.createDataFrame(userClickRow, userClickStructTyoe)
- userClickDataFrame.createTempView("userClickData")
-
- sparkSession.sql(
- """
- |select userName,clickNum from
- |(
- | select userName,clickNum,row_number() over (order by clickNum desc) as rank from
- | userClickData
- |) where rank<=3
- |""".stripMargin
- ).show()
-
- //后面可以更具结果的数据自己处理保存到redis或者mysql
- })
-
-
- sparkStreaming.start()
- sparkStreaming.awaitTermination()
- sparkStreaming.stop()
- }
- }
输出结果
- +--------+--------+
- |userName|clickNum|
- +--------+--------+
- | a| 9|
- | v| 3|
- | c| 3|
- +--------+--------+
缓存与持久化机制
- sparkstreaming默认对窗口的操作,还有upstateBykey开启的持久化的操作
- 与RDD不同的是它默认都是会要序列化的
Sparkstreaming容错机制
分区容错
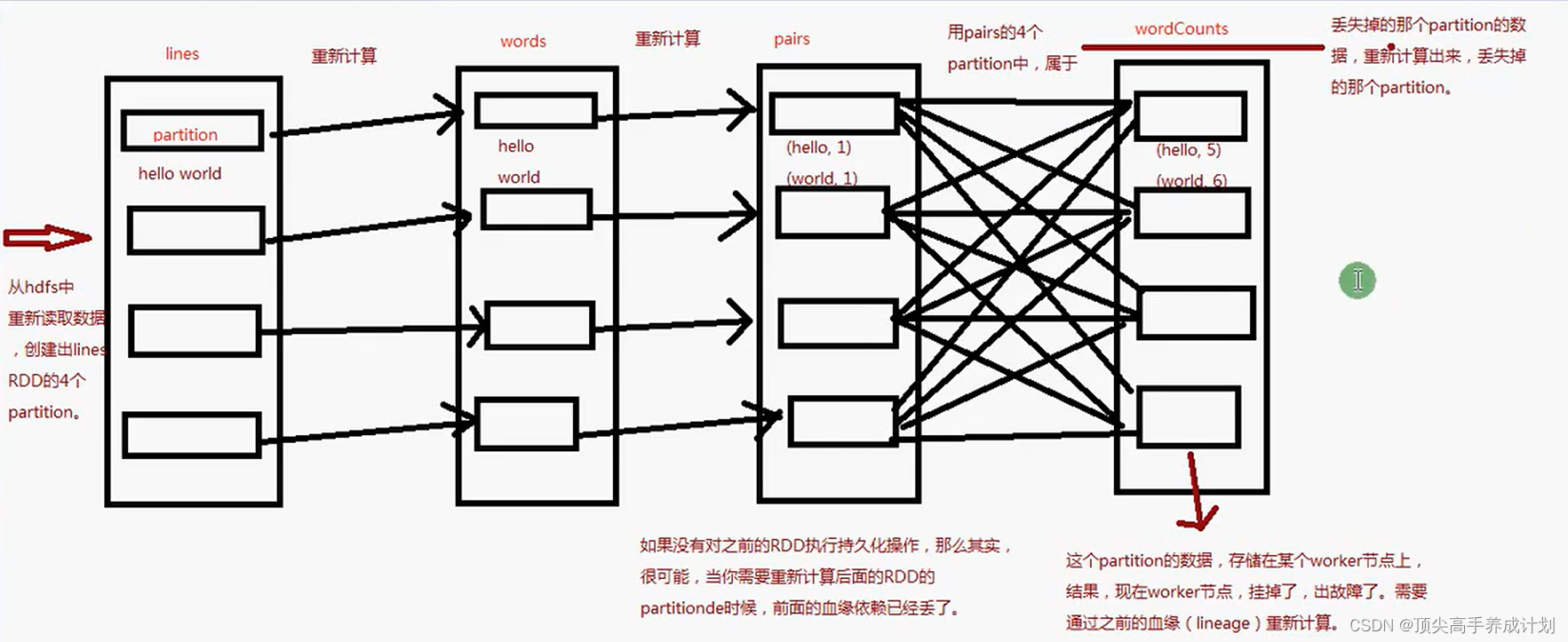
可靠receiver
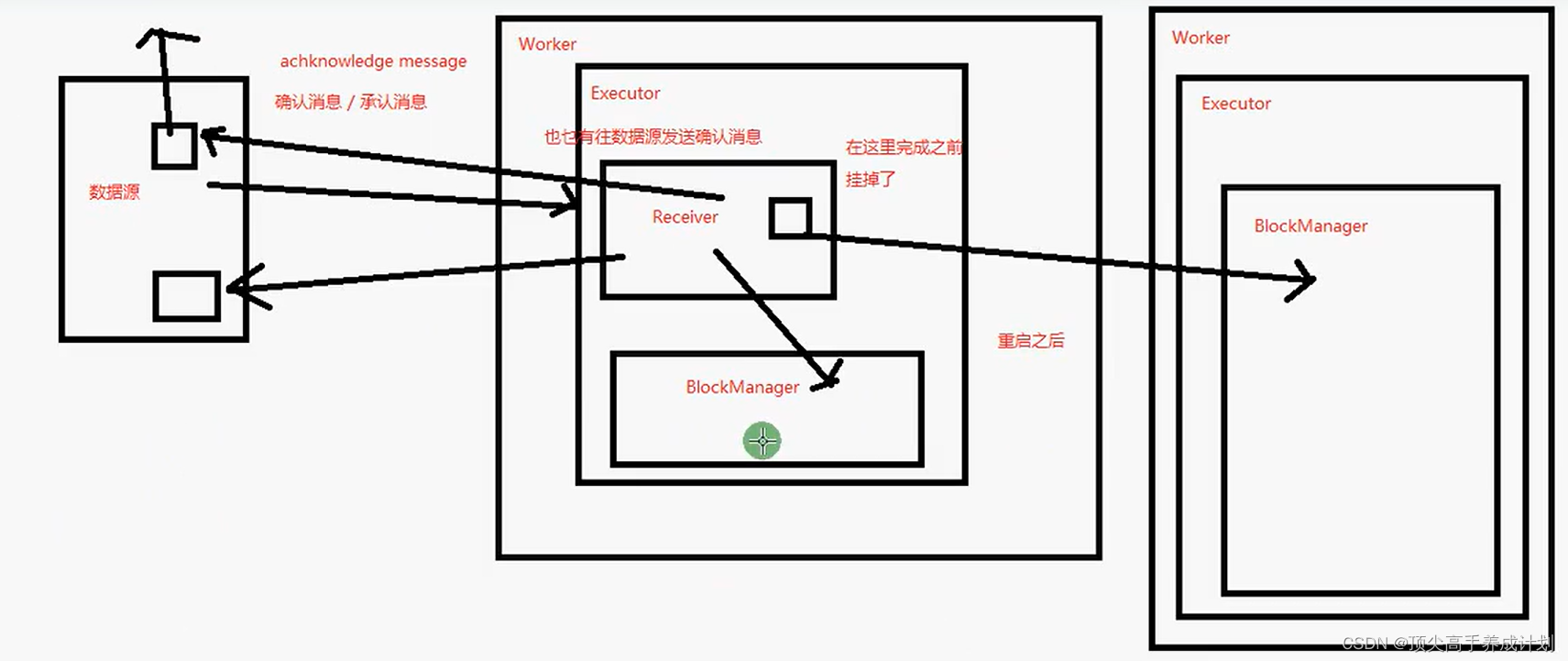
SparkStreaming架构原理
sparkStreaming架构原理图解
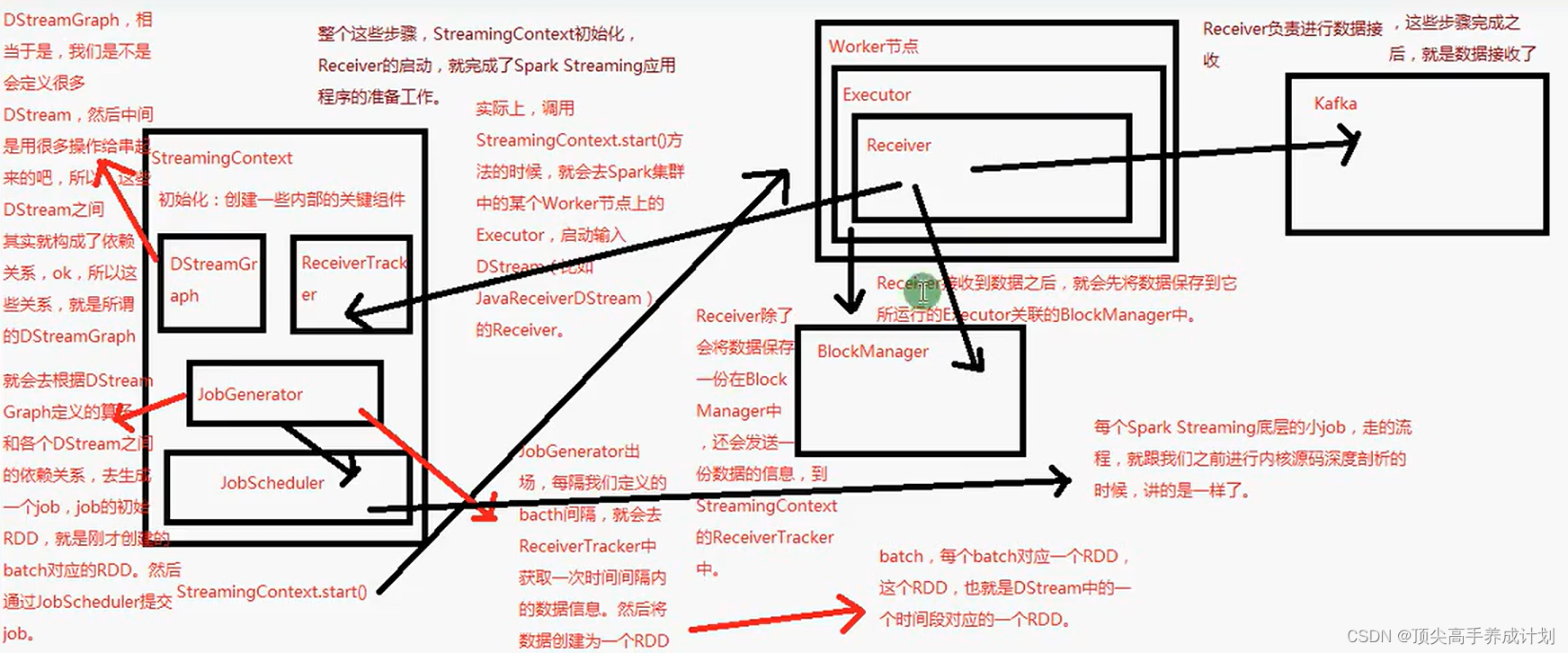
接收数据的原理
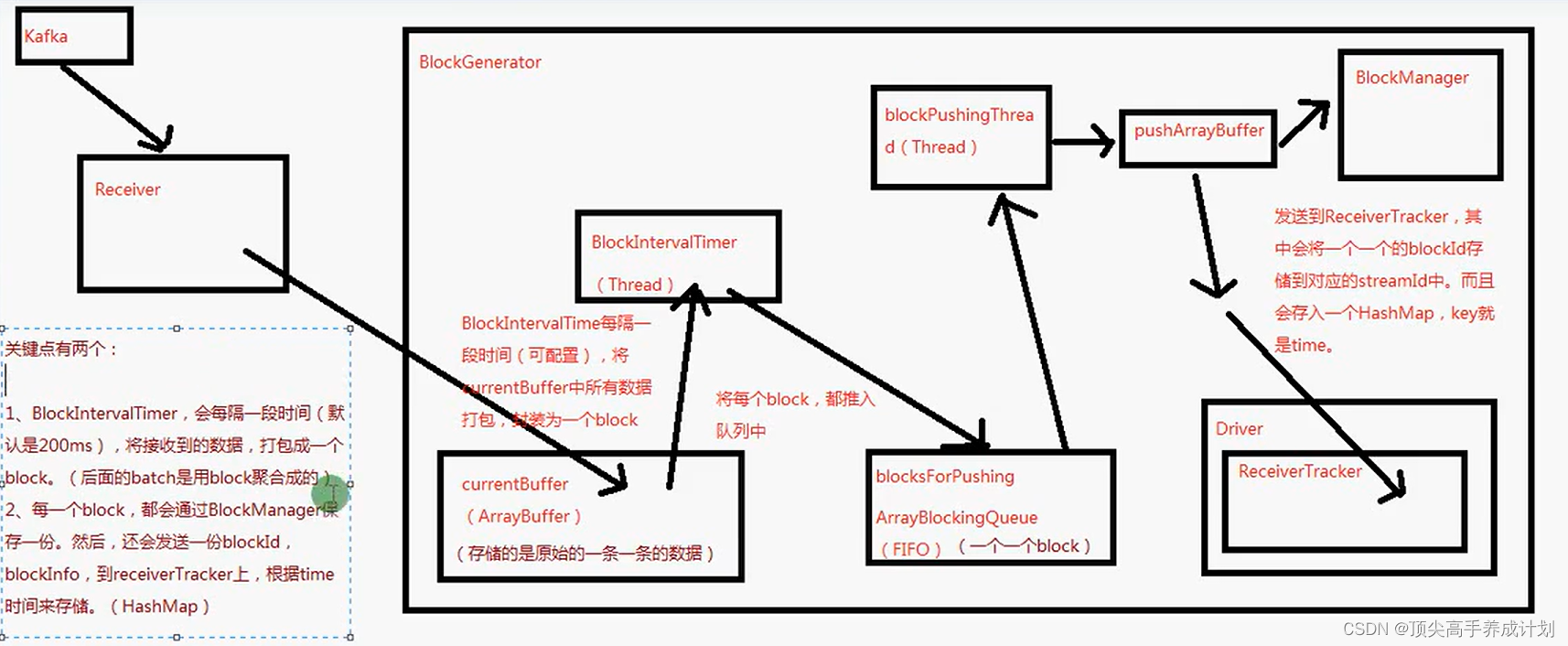
写数据原理

SparkStreaming性能调优
- 对于receiver模式的处理,可以调高receiver的数量,提高并行度
- 对于每一批的RDD进行调优,因为RDD的分区和每一个batch里面的block有关,比如batch的间隔是2s,也就是JavaStreamingContext(sparkConf, Durations.seconds(2)),这里就是设置拉去batch的时间,每一批batch里面有若干的block,每一个block产生的时间是200毫秒,每一个block对应RDD的一个分区,这里调优的地方就是如果你的CPU有8核,但是如果你每一批的数据就是5个block的话,那么就是没有充分的利用cpu我们这个时候就可以对于block产生的时间减少
- 对于Kafka的Direct模式的话,我们只要设置的并行度和分区一样就可以了
- 使用CMS垃圾回收器,减少gc的时间,提高batch的处理速度

