
热门标签
热门文章
- 1winfrom软件开发汽车测试_从事汽车电子软件开发岗,我们最近还没那么愁
- 2js:Set集合的实现_js实现set
- 3我,32岁,动力机械专业研究生,转行到算法工程师,完成薪资翻倍_开发转算法工程师
- 4lstm与bp神经网络——时序数据预测_时序数据 神经网络预测
- 5linux内核audit,linux中audit审计服务
- 6问题 D: DS B-树构建及查找_在初始为空的m阶b-树中依次插入n个结点,按层次遍历输出关键字,然后再查找m个关键
- 7docker es持久化_如何用最简短的话讲清楚Docker的全貌?
- 8优质论文list(分布式系统/存储/索引相关)_论文list包括什么
- 9华为OD机试 - 悄悄话(Python、Java、C++、Javascript)_java 悄悄话 od
- 10一款轻量级写作神器Typora
当前位置: article > 正文
《动手学深度学习PyTorch版》4_机器翻译ffn
作者:weixin_40725706 | 2024-06-14 19:46:46
赞
踩
机器翻译ffn
机器翻译及相关技术
1、机器翻译和数据集
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。

1.数据预处理
将数据集清洗、转化为神经网络的输入minbatch
def preprocess_raw(text):
# 处理空格
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
out = ''
# 标点之前统一加上空格
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and i > 0 and text[i-1] != ' ':
out += ' '
out += char
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字符在计算机里以编码形式存在,我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。 而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表不间断空白符nbsp(non-breaking space),超出gbk编码范围,是需要去除的特殊字符。


2.分词(Tokenization):字符串切成单词,组成源语言、目标语言两个单词列表,列表中的每个元素是一个已经切分成单词的句子样本。
#output:
source:[['go', '.'], ['hi', '.'], ['hi', '.'],...]
target: [['va', '!'], ['salut', '!'], ['salut', '.'],...]
- 1
- 2
- 3
3.建立词典:单词(字符串)列表转成单词id(0~n)组成的列表
src_vocab = build_vocab(source)
len(src_vocab) # 3789
- 1
- 2
4.载入数据集
# pad()函数使样本(句子)长度变成指定长度 def pad(line, max_len, padding_token): if len(line) > max_len: return line[:max_len] return line + [padding_token] * (max_len - len(line)) pad(src_vocab[source[0]], 10, src_vocab.pad) # [38, 4, 0, 0, 0, 0, 0, 0, 0, 0] # 返回pad好的单词列表和每个句子的有效长度 def build_array(lines, vocab, max_len, is_source): lines = [vocab[line] for line in lines] # 目标语言的每个句子都加上头尾字符 if not is_source: lines = [[vocab.bos] + line + [vocab.eos] for line in lines] array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines]) # 有效长度,以便计算Loss时排除padding字段,pad字段不在字典索引范围 valid_len = (array != vocab.pad).sum(1) #第一个维度 return array, valid_len # 返回预处理好的两个单词列表,和train_iter def load_data_nmt(batch_size, max_len): # This function is saved in d2l. src_vocab, tgt_vocab = build_vocab(source), build_vocab(target) src_array, src_valid_len = build_array(source, src_vocab, max_len, True) tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False) train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len) train_iter = data.DataLoader(train_data, batch_size, shuffle=True) return src_vocab, tgt_vocab, train_iter src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size=2, max_len=8) # 某个Batch的train_iter X = tensor([[ 5, 24, 3, 4, 0, 0, 0, 0], [ 12, 1388, 7, 3, 4, 0, 0, 0]], dtype=torch.int32) Valid lengths for X = tensor([4, 5]) Y = tensor([[ 1, 23, 46, 3, 3, 4, 2, 0], [ 1, 15, 137, 27, 4736, 4, 2, 0]], dtype=torch.int32) Valid lengths for Y = tensor([7, 7])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
4.模型训练
Encoder-Decoder常应用于输入序列和输出序列的长度是可变的对话系统、生成式任务中。

Sequence to Sequence模型
训练:训练时decoder每个单元输出得到的单词并不!作为下一个单元的输入单词。

预测:Encoder的隐层状态准确性奠定了翻译的准确性
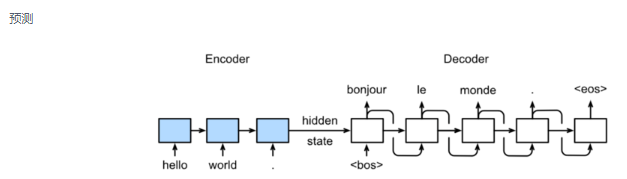
Seq2Seq具体结构:其中Embbedding层把每个单词序列映射成一个n维向量。

class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self- 1
- 2
- 3
- 4
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/719378
推荐阅读
相关标签

