
热门标签
热门文章
- 1尽人事,听天命,十二轮面试最终圆梦字节,记一次最难面试记录_字节一面二面三面哪个最难
- 2快速部署k8s
- 3eclipse cannot resolved to a type 多种解决方案_eclipse cannot be resolved to a type
- 4图书借阅-er图_图书借阅系统er图及关系模型
- 5狂奔的羊驼-llama3生态大爆发_llama 3
- 6redis源码分析 2 迭代器_redis iterator
- 7【技术分享】基于DWA算法的动态静态障碍物局部路径规划及实时展示(Matlab实现)_matlab上运行局部规划器
- 8使用TabLayout和ViewPager实现左右滑动选项卡_android tablayout 判断左右滑动
- 9排序算法 - 堆排序详解_设计一个堆排序算法,使无序序列逆序排列
- 10Three.js——基于原生WebGL封装运行的三维引擎_webgl 3d引擎
当前位置: article > 正文
[代码实践]利用LSTM构建基于conll2003数据集的命名实体实体识别NER模型
作者:weixin_40725706 | 2024-06-12 12:27:52
赞
踩
conll2003数据集
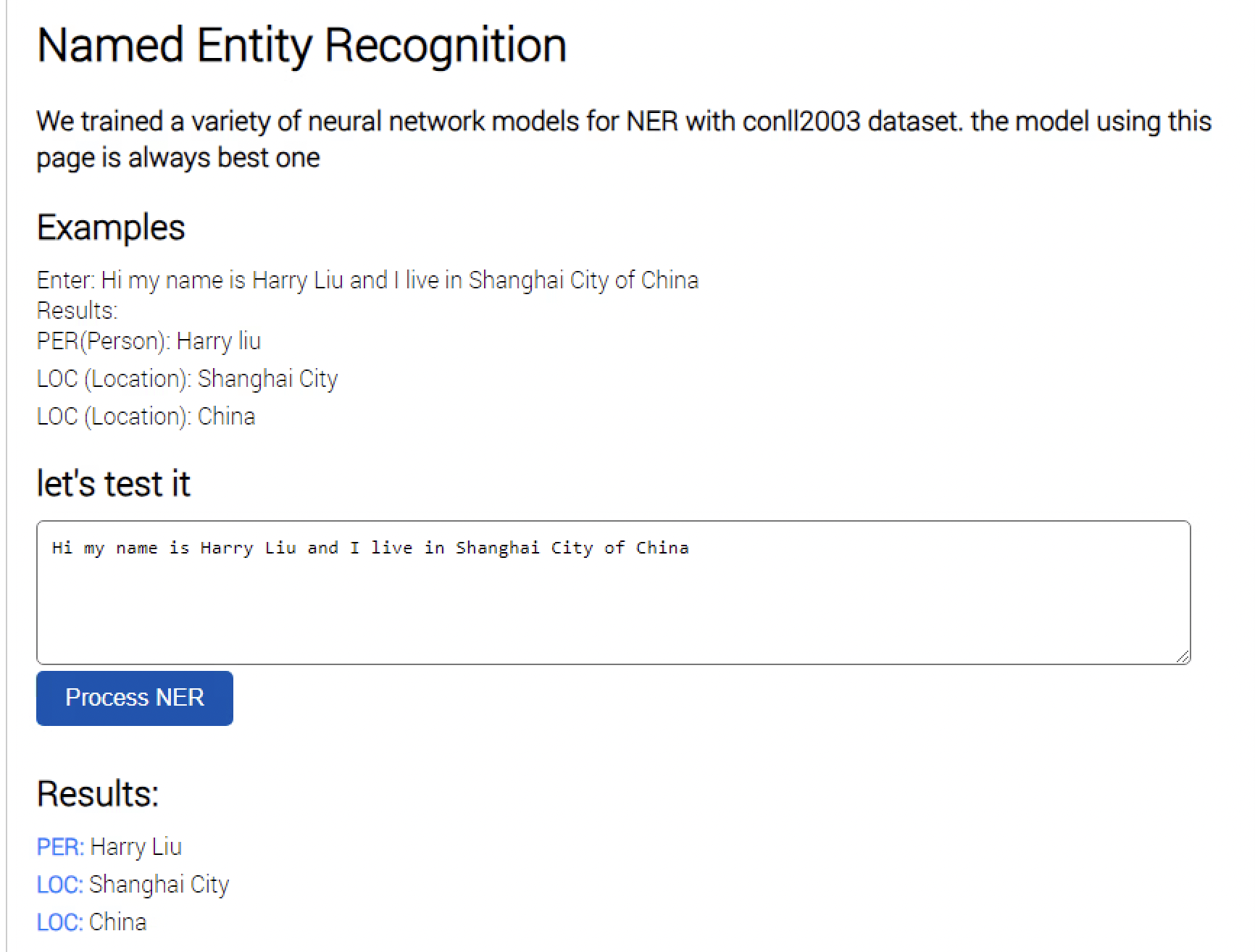
Python环境
- tensorflow=2.10.1
- keras=2.10.0
1. conll2003数据集介绍以及数据集预处理请看下面博客
conll2003数据集下载与预处理_茫茫人海一粒沙的博客-CSDN博客
2. 取预处理过的数据集
- import tensorflow as tf
- from keras.models import Model
- from keras.layers import Input, Embedding, LSTM, Dense, TimeDistributed
- import keras as keras
- from keras.callbacks import EarlyStopping, ModelCheckpoint
- from keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
- import numpy as np
-
- def load_dataset():
- dataset = np.load('dataset/dataset.npz')
- train_X = dataset['train_X']
- train_y = dataset['train_y']
- valid_X = dataset['valid_X']
- valid_y = dataset['valid_y']
- test_X = dataset['test_X']
- test_y = dataset['test_y']
- return train_X, train_y, valid_X, valid_y, test_X, test_y

3. 创建基于lstm网络的NER模型
- max_len =64
-
- def create_model():
- word2idx = load_dict('dataset/word2idx.json')
- tag2idx = load_dict('dataset/idx2Label.json')
-
- num_words = len(word2idx) + 1
- num_tags = len(tag2idx)
-
- # Define the model
- input_layer = Input(shape=(None,))
- embedding_layer = Embedding(input_dim=num_words, output_dim=60, input_length=max_len)(input_layer)
- lstm_layer = LSTM(units=50, return_sequences=True, dropout=0.5)(embedding_layer)
- output_layer = TimeDistributed(Dense(num_tags, activation="softmax"))(lstm_layer)
-
- model = Model(input_layer, output_layer)
-
- return model
4. 训练模型
- def train( model, train_X, train_y, valid_X, valid_y):
-
- # 定义保存模型的路径和文件名
- model_path = './dataset/ner_model.h5'
-
- # 定义早停回调函数
- early_stop = EarlyStopping(monitor='val_accuracy', patience=3, mode='max', verbose=1)
- # 定义ModelCheckpoint回调函数
- checkpoint = ModelCheckpoint(model_path, monitor='val_accuracy', save_best_only=True, mode='max', verbose=1)
- # Compile and train the model
- model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
-
-
- print(np.array(train_X).shape)
- print(np.array(train_y).shape)
-
- print(np.array(valid_X).shape)
- print(np.array(valid_y).shape)
-
- model.fit(train_X, train_y, batch_size=32, epochs=20, validation_data=(valid_X, valid_y), callbacks=[early_stop, checkpoint])
5. 测试模型
- def test(test_X, test_y ):
- model = keras.models.load_model('./dataset/ner_model.h5')
- # 评估模型
- scores = model.evaluate(test_X, test_y, verbose=0)
- print("Test accuracy:", scores[1])
6. 保存文件以及加载文件的方法
- def save_dict(dict, file_path):
- import json
- # Saving the dictionary to a file
- with open(file_path, 'w') as f:
- json.dump(dict, f)
-
-
- def load_dict(path_file):
- import json
-
- # Loading the dictionary from the file
- with open(path_file, 'r') as f:
- loaded_dict = json.load(f)
- return loaded_dict;
-
- print(loaded_dict) # Output: {'key1': 'value1', 'key2': 'value2'}
7. main方法来训练模型与测试模型
- if __name__ == '__main__':
- train_X, train_y, valid_X, valid_y, test_X, test_y =load_dataset()
- model= create_model()
- train(model, np.concatenate([train_X, valid_X]), np.concatenate([train_y, valid_y]),test_X, test_y)
- test(test_X, test_y )
- # predict()
执行结果. 一共应用了12个Epoch,训练集上的准确率是99.7%,测试集上准确率是98%。
- Epoch 11: val_accuracy did not improve from 0.99427
- 577/577 [==============================] - 28s 49ms/step - loss: 0.0043 - accuracy: 0.9987 - val_loss: 0.0269 - val_accuracy: 0.9942
- Epoch 12/20
- 576/577 [============================>.] - ETA: 0s - loss: 0.0038 - accuracy: 0.9988
- Epoch 12: val_accuracy did not improve from 0.99427
- 577/577 [==============================] - 28s 49ms/step - loss: 0.0038 - accuracy: 0.9988 - val_loss: 0.0270 - val_accuracy: 0.9942
- Epoch 13/20
- 577/577 [==============================] - ETA: 0s - loss: 0.0034 - accuracy: 0.9990
- Epoch 13: val_accuracy did not improve from 0.99427
- 577/577 [==============================] - 28s 49ms/step - loss: 0.0034 - accuracy: 0.9990 - val_loss: 0.0280 - val_accuracy: 0.9939
- Epoch 13: early stopping
- Test accuracy: 0.9942699670791626
8. 预测模型
- def predict():
-
- # Example sentences to predict
- test_sentences = [
- "John Wilson works at Apple",
- "Harry works at Citi",
- "I have a meeting with Peter Blackburn tomorrow .",
- "George Smith has writen many books",
- "BRUSSELS",
- "Peter Blackburn",
- 'EU rejects German call to boycott British lamb .',
- 'The European Commission said on Thursday it disagreed with German advice to consumers to shun British'
- ]
-
- word2idx = load_dict('dataset/word2idx.json')
- tag2idx = load_dict('dataset/idx2Label.json')
- model = keras.models.load_model('./dataset/ner_model.h5')
-
-
- # Convert test sentences to numerical sequences
- test_sequences = [[word2idx.get(word.lower(), 1) for word in sentence.split()] for sentence in test_sentences]
- print('test_sequences:',test_sequences)
- test_sequences = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=test_sequences, padding='post' , value=0)
-
- # Make predictions
- predictions = model.predict(test_sequences)
- # print(predictions)
- predicted_tags = tf.argmax(predictions, axis=-1)
-
- # Convert predicted tags back to labels
- predicted_labels = []
- for tags in predicted_tags:
- labels = [list(tag2idx.keys())[tag] for tag in tags]
- predicted_labels.append(labels)
-
- # Print the predicted labels
- for sentence, labels in zip(test_sentences, predicted_labels):
- print(f"Sentence: {sentence}")
- print(f"Predicted Labels: {labels}\n")
执行结果
- test_sequences: [[19297, 14241, 635, 6061, 5862], [17574, 635, 6061, 1], [23991, 4403, 5466, 26487, 14180, 22793, 7357, 10690, 13690], [986, 22945, 318, 1, 16871, 16227], [20014], [22793, 7357], [10799, 8816, 5569, 17034, 15182, 26639, 3124, 12927, 13690], [2858, 26758, 3140, 3214, 21958, 17324, 21359, 26677, 14180, 5569, 5119, 15182, 24318, 15182, 728, 3124]]
- 1/1 [==============================] - 0s 450ms/step
- Sentence: John Wilson works at Apple
- Predicted Labels: ['B-PER', 'I-PER', 'O', 'O', 'B-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: Harry works at Citi
- Predicted Labels: ['B-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: I have a meeting with Peter Blackburn tomorrow .
- Predicted Labels: ['O', 'O', 'O', 'O', 'O', 'B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: George Smith has writen many books
- Predicted Labels: ['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: BRUSSELS
- Predicted Labels: ['B-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: Peter Blackburn
- Predicted Labels: ['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: EU rejects German call to boycott British lamb .
- Predicted Labels: ['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
- Sentence: The European Commission said on Thursday it disagreed with German advice to consumers to shun British
- Predicted Labels: ['O', 'B-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'B-MISC', 'O', 'O', 'O', 'O', 'O', 'B-MISC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
-
-
- Process finished with exit code 0
9. 所有代码
- import tensorflow as tf
- from keras.models import Model
- from keras.layers import Input, Embedding, LSTM, Dense, TimeDistributed
- import keras as keras
- from keras.callbacks import EarlyStopping, ModelCheckpoint
- from keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
- import numpy as np
-
- def load_dataset():
- dataset = np.load('dataset/dataset.npz')
- train_X = dataset['train_X']
- train_y = dataset['train_y']
- valid_X = dataset['valid_X']
- valid_y = dataset['valid_y']
- test_X = dataset['test_X']
- test_y = dataset['test_y']
- return train_X, train_y, valid_X, valid_y, test_X, test_y
-
- max_len =64
-
- def create_model():
- word2idx = load_dict('dataset/word2idx.json')
- tag2idx = load_dict('dataset/idx2Label.json')
-
- num_words = len(word2idx) + 1
- num_tags = len(tag2idx)
-
- # Define the model
- input_layer = Input(shape=(None,))
- embedding_layer = Embedding(input_dim=num_words, output_dim=60, input_length=max_len)(input_layer)
- lstm_layer = LSTM(units=50, return_sequences=True, dropout=0.5)(embedding_layer)
- output_layer = TimeDistributed(Dense(num_tags, activation="softmax"))(lstm_layer)
-
- model = Model(input_layer, output_layer)
-
- return model
-
-
- def train( model, train_X, train_y, valid_X, valid_y):
-
- # 定义保存模型的路径和文件名
- model_path = './dataset/ner_model.h5'
-
- # 定义早停回调函数
- early_stop = EarlyStopping(monitor='val_accuracy', patience=3, mode='max', verbose=1)
- # 定义ModelCheckpoint回调函数
- checkpoint = ModelCheckpoint(model_path, monitor='val_accuracy', save_best_only=True, mode='max', verbose=1)
- # Compile and train the model
- model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
-
-
- print(np.array(train_X).shape)
- print(np.array(train_y).shape)
-
- print(np.array(valid_X).shape)
- print(np.array(valid_y).shape)
-
- model.fit(train_X, train_y, batch_size=32, epochs=20, validation_data=(valid_X, valid_y), callbacks=[early_stop, checkpoint])
- def save_dict(dict, file_path):
- import json
- # Saving the dictionary to a file
- with open(file_path, 'w') as f:
- json.dump(dict, f)
-
-
- def load_dict(path_file):
- import json
-
- # Loading the dictionary from the file
- with open(path_file, 'r') as f:
- loaded_dict = json.load(f)
- return loaded_dict;
-
- print(loaded_dict) # Output: {'key1': 'value1', 'key2': 'value2'}
-
- def test(test_X, test_y ):
- model = keras.models.load_model('./dataset/ner_model.h5')
- # 评估模型
- scores = model.evaluate(test_X, test_y, verbose=0)
- print("Test accuracy:", scores[1])
-
-
- def predict():
-
- # Example sentences to predict
- test_sentences = [
- "John Wilson works at Apple .",
- "I have a meeting with Peter Blackburn tomorrow.",
- "BRUSSELS",
- "Peter Blackburn",
- 'EU rejects German call to boycott British lamb.',
- 'The European Commission said on Thursday it disagreed with German advice to consumers to shun British'
- ]
-
- word2idx = load_dict('dataset/word2idx.json')
- tag2idx = load_dict('dataset/idx2Label.json')
- model = keras.models.load_model('./dataset/ner_model.h5')
-
-
- # Convert test sentences to numerical sequences
- test_sequences = [[word2idx.get(word.lower(), 0) for word in sentence.split()] for sentence in test_sentences]
- print('test_sequences:',test_sequences)
- test_sequences = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=test_sequences, padding='post' , value=0)
-
- # Make predictions
- predictions = model.predict(test_sequences)
- # print(predictions)
- predicted_tags = tf.argmax(predictions, axis=-1)
-
- # Convert predicted tags back to labels
- predicted_labels = []
- for tags in predicted_tags:
- labels = [list(tag2idx.keys())[tag] for tag in tags if tag != 0]
- predicted_labels.append(labels)
-
- # Print the predicted labels
- for sentence, labels in zip(test_sentences, predicted_labels):
- print(f"Sentence: {sentence}")
- print(f"Predicted Labels: {labels}\n")
-
-
- if __name__ == '__main__':
- train_X, train_y, valid_X, valid_y, test_X, test_y =load_dataset()
- model= create_model()
- train(model, np.concatenate([train_X, valid_X]), np.concatenate([train_y, valid_y]),test_X, test_y)
- test(test_X, test_y )
- # predict()
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

