
热门标签
热门文章
- 1Linux下Root权限无法读取文件探究_输入输出错误,尝试对 进行stat调用时
- 2软件测试入职一年多薪资正常应该有多少?_软件测试有经验一年的工作薪资
- 3navicat premium 12+ Mac 3分钟 破解方案_all patch solutions are suppressed
- 4云计算——ACA学习 阿里云云计算服务概述_飞天操作系统
- 5构建第一个ArkTS应用(纯HarmonyOS应用)_arkts sdk版本
- 6hi3861 OpenHarmony PCA9685 舵机控制板
- 7docker inspect命令详解_docker inspect 详解
- 8使用TortoiseGit处理代码冲突
- 9训练自己的yolov5样本, 并部署到rv1126 <四>_rk_mpi_sys_getmediabuffer
- 10用python写个基于深度学习的股票价格预测模型
当前位置: article > 正文
bert简介_Google 最强开源模型 BERT 在 NLP 中的应用 | 技术头条
作者:weixin_40725706 | 2024-03-25 20:30:19
赞
踩
google bert api


作者 | 董文涛
责编 | 唐小引
出品 | CSDN(ID:CSDNnews)
【CSDN 编者按】Google 的 BERT 模型一经发布便点燃了 NLP 各界的欢腾,Google Brain 的资深研究科学家 Thang Luong 曾给出其“开启了 NLP 新时代”的高度定义,国内外许多公司及开发者对其进行了研究及应用,本文作者及其团队对 BERT 进行了应用探索。
随着 Google 推出的 BERT 模型在多种 NLP 任务上取得 SOTA,NLP 技术真正进入了大规模应用阶段,由此,我们展开了对 BERT 的探索。
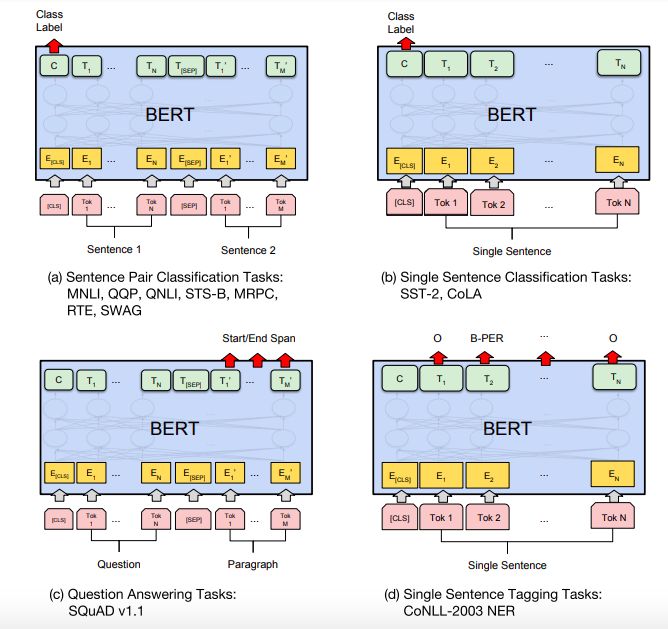

训练模型
训练数据
训练其他模型时我们已经标注了大量的训练数据,主要把相似句对分为三类来标注:
不相似(0)、相关(0.5)、相似(1)
所以,训练 BERT 模型时就可以“拿来主义”了。
模型修改
我们的主要应用点是相似度计算,期望模型返回的结果是一个概率(分值)而不是每个类别的概率。当然如果模型给的结果是每一个类别的概率,依然可以通过加权
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/312300
推荐阅读
相关标签

