
- 1AI文章编写助手:知识生成新利器,比传统撰写快10倍_文章助手
- 2NLP-基于bertopic工具的新闻文本分析与挖掘_bertopic教程
- 3【python入门篇】你好python_您好,python编程语言
- 4广告行业中那些趣事系列66:使用chatgpt类LLM标注数据并蒸馏到生产小模型
- 5NER任务语料_bosonnlp_ner_6c
- 6ARJ压缩软件使用说明_解压arj32文件命令
- 7excel if in函数_【Excel函数教程】IF函数你都不会用,还敢说熟练使用Excel?
- 8《Machine Learning(Tom M. Mitchell)》读书笔记——5、第四章_"tom mitchell \"machine learning\" (4.10)"
- 9鸿蒙开发实战项目(四十三):闹钟(ArkTS)_鸿蒙项目闹钟
- 10已经阻止此发布者在你的计算机上运行软件win10,win10系统打开软件提示已经阻止此发布者在你的计算机上运行软件怎么办...
论文阅读:Capture, Learning, and Synthesis of 3D Speaking Styles_flame bfm
赞
踩
前言
- 是2019 CVPR的一篇文章, 影响也比较广泛
输入输出:
输入为头部的模板Flame人脸模型和语音信号,输出为有运动的信号。
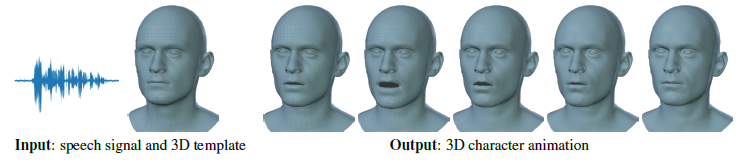
语音到3d运动存在的问题:
- 两个domain截然不同, 需要合适的非线性函数, 当然需要大量的训练数据
- 音素和面部运动存在多对多映射, 这个问题怎么解决呢?
- 人对真实很敏感, 有恐怖谷效应(uncanny valley)
- 与多个说话人的3d面部形状相关的语音训练数据很有限
数据集:
VOCA dataset: 12个subjects(应该是不同的人) 480个句子, 每个句子3到4秒, 句子从标准协议中选择
-
将一个通用的人脸模板与所有扫描对齐
-
The 4D scans are captured at 60fps and we align a common face template mesh to all the scans, bringing them into correspondence.
贡献点:
- 4d数据集, 60fps 大约29分钟的4d扫描, 与12个说话人的声音同步
- Conditioning on sub-ject labels during training allows the model to learn a variety of realistic speaking styles.
- VOCA(vioce operated character animation)能够改变说话风格, 与身份相关的面部形状和姿势(头部, 下巴和眼球旋转)
- 可以适用于训练集中没见到的人
- We train our model on a self-captured multi-subject 4D face dataset (VOCASET)
目前见到的3d人脸表示方法
- 低精度层面上的
- 3DMM(BFM)
- LSFM-3DMM
- FlAME model
- FaceScape model
- Facewarehouse
- 论文中使用的便是中间的Flame模型
- FLAME 人脸模型
- 从4000个个体上学习identity sapce
- 有正交的表情空间
- flame 把人脸模型分为三部分:shape形状 pose 姿态expression 表情

方法
整体架构
输入音频特征与subject-specific template T, 这里的subject是8个人的one-hot向量, 被加在了音频特征的最后一个维度, 将音频特征通过4层卷积, 结果再加上one-hot向量, 通过线性层得到 5023*3的位移。
语音特征提取
语音信号输入DeepSpeech中,进行特征提取,一帧为0.02s, 也就是50HZ, 对于Ts的音频片段, 含有50T帧, 然后通过线性插值得到60T帧。 这里有个overlap, In order to incorporate temporal information, we convert the audio frames to overlapping windows of size W × D, where W is the window size. The output is a threedimensional array of dimensions 60T ×W × D. (这里还没有很懂, 暂且认为就是有个60T ×W × D的语音特征)
-
D是Deepspeech输出字符集的概率, 共有26个英文加空格, 加‘, 加CTC算法里面的空字符, 共29,也有人用27的
-
由于使用DeepSpeech提取的特征没有任何空间相关性,因此将输入窗口重塑为W×1×(D+8)维度,并在时间维度上执行1D卷积。

具体结构可看下面的结构图

损失函数



