- 1android4.4修改设置中默认定位模式_android4.4 bd gps
- 2android studio提高编译的速度,安装apk过慢问题解决_安卓开发apk文件变大之后,安装越来越慢
- 3Huggingface入门篇 II (QA)_huggingface access token
- 4【树莓派-网络监控(3)角度遥控】基于python3控制两自由度舵机,实现摄像头拍摄角度的遥控_树莓派使用舵机控制摄像头
- 5Mybatis查询数据返回多条_mybatis查询前10条数据
- 6软件测试专业术语对照表
- 7vue2.x项目中ts配置axios返回值类型推导_axios interceptors 改变返回值类型
- 8Java-JVM 虚拟机原理调优实战
- 9窗函数作用和性质_窗函数的作用
- 10OpenCV 4基础篇| OpenCV图像的拼接
mysql 主从延迟分析
赞
踩
一、如何分析主从延迟
分析主从延迟一般会采集以下三类信息。
从库服务器的负载情况
为什么要首先查看服务器的负载情况呢?因为软件层面的所有操作都需要系统资源来支撑。
常见的系统资源有四类:CPU、内存、IO、网络。对于主从延迟,一般会重点关注 CPU 和 IO 。
分析 CPU 是否达到瓶颈,常用的命令是 top,通过 top 我们可以直观地看到主机的 CPU 使用情况。以下是 top 中 CPU 相关的输出。
Cpu(s): 0.2%us, 0.2%sy, 0.0%ni, 99.5%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st下面我们看看各个指标的具体含义。
- us:处理用户态( user )任务的 CPU 时间占比。
- sy:处理内核态( system )任务的 CPU 时间占比。
- ni:处理低优先级进程用户态任务的 CPU 时间占比。
进程的优先级由 nice 值决定,nine 的范围是 -20 ~ 19 ,值越大,优先级越低。其中,1 ~ 19 称之为低优先级。 - id:处于空闲状态( idle )的 CPU 时间占比。
- wa:等待 IO 的 CPU 时间占比。
- hi:处理硬中断( irq )的 CPU 时间占比。
- si:处理软中断( softirq )的 CPU 使用率。
- st:当系统运行在虚拟机中的时候,被其它虚拟机占用( steal )的 CPU 时间占比。
一般来说,当 CPU 使用率 ( 1 - 处于空闲状态的 CPU 时间占比 )超过 90% 时,需引起足够关注。毕竟,对于数据库应用来说,CPU 很少是瓶颈,除非有大量的慢 SQL 。
接下来看看 IO。
查看磁盘 IO 负载情况,常用的命令是 iostat 。
- # iostat -xm 1
- avg-cpu: %user %nice %system %iowait %steal %idle
- 4.21 0.00 1.77 0.35 0.00 93.67
-
- Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
- sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- sdb 0.00 0.00 841.00 3234.00 13.14 38.96 26.19 0.60 0.15 0.30 0.11 0.08 32.60
命令中指定了 3 个选项,其中,
- -x:打印扩展信息。
- -m:指定吞吐量的单位是 MB/s ,默认是 KB/s 。
- 1:每隔 1s 打印一次。
下面看看输出中各指标的具体含义。
- rrqm/s:每秒被合并的读请求的数量。
- wrqm/s:每秒被合并的写请求的数量。
- r/s:每秒发送给磁盘的读请求的数量。
- w/s:每秒写入磁盘的写请求的数量。注意,这里的请求是合并后的请求。r/s + w/s 等于 IOPS 。
- rMB/s:每秒从磁盘读取的数据量。
- wMB/s:每秒写入磁盘的数据量。rMB/s + wMB/s 等于吞吐量。
- avgrq-sz:I/O 请求的平均大小,单位是扇区,扇区的大小是 512 字节。一般而言,I/O 请求越大,耗时越长。
- avgqu-sz:队列里的平均 I/O 请求数量。
- await:I/O 请求的平均耗时,包括磁盘的实际处理时间及队列中的等待时间,单位 ms 。
其中,r_await 是读请求的平均耗时,w_await 是写请求的平均耗时。 - svctm:I/O 请求的平均服务时间,单位 ms 。注意,这个指标已弃用,在后续版本会移除。
- %util:磁盘饱和度。反映了一个采样周期内,有多少时间在做 I/O 操作。
一般来说,我们会重点关注 await 和 %util。
对于只能串行处理 I/O 请求的设备来说,%util 接近 100% ,就意味着设备饱和。但对于 RAID、SSD 等设备,因为它能并行处理,故该值参考意义不大,即使达到了 100% ,也不意味着设备出现了饱和。至于是否达到了性能上限,需参考性能压测下的 IOPS 和吞吐量。
主从复制状态
对于主库,执行 SHOW MASTER STATUS 。
- mysql> show master status;
- +------------------+----------+--------------+------------------+---------------------------------------------+
- | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
- +------------------+----------+--------------+------------------+---------------------------------------------+
- | mysql-bin.000004 | 1631495 | | | bd6b3216-04d6-11ec-b76f-000c292c1f7b:1-5588 |
- +------------------+----------+--------------+------------------+---------------------------------------------+
- 1 row in set (0.00 sec)
SHOW MASTER STATUS 的输出中重点关注 File 和 Position 这两个指标的值。
对于从库,执行 SHOW SLAVE STATUS 。
- mysql> show slave status\G
- *************************** 1. row ***************************
- ...
- Master_Log_File: mysql-bin.000004
- Read_Master_Log_Pos: 1631495
- ...
- Relay_Master_Log_File: mysql-bin.000004
- ...
- Exec_Master_Log_Pos: 1631495
- ...
SHOW SLAVE STATUS 的输出中重点关注 Master_Log_File,Read_Master_Log_Pos,Relay_Master_Log_File,Exec_Master_Log_Pos 这四个指标的值。
接下来,重点比较以下两对值。
第一对:( File , Position ) & ( Master_Log_File , Read_Master_Log_Pos )
这里面,
- ( File , Position ) 记录了主库 binlog 的位置。
- ( Master_Log_File , Read_Master_Log_Pos ) 记录了 IO 线程当前正在接收的二进制日志事件在主库 binlog 中的位置。
如果 ( File , Position ) 大于 ( Master_Log_File , Read_Master_Log_Pos ) ,则意味着 IO 线程存在延迟。
第二对:( Master_Log_File , Read_Master_Log_Pos ) & ( Relay_Master_Log_File , Exec_Master_Log_Pos )
这里面,( Relay_Master_Log_File, Exec_Master_Log_Pos ) 记录了 SQL 线程当前正在重放的二进制日志事件在主库 binlog 的位置。
如果 ( Relay_Master_Log_File, Exec_Master_Log_Pos ) < ( Master_Log_File, Read_Master_Log_Pos ) ,则意味着 SQL 线程存在延迟。
Master_Log_File, Relay_Log_File, Relay_Master_Log_File
Master_Log_File
当前IO从master读取的binlog的文件名。Relog_Log_File
slave的SQL先前当读取的relay log文件名。Relay_Master_log_File
当前SQL执行的最新的SQL Event是包含在master哪个binlog文件中的。
Read_Master_Log_Pos, Relay_Log_Pos, Exec_Master_Log_Pos
这三个参数可以说是至关重要,也经常被搞混。Read_Master_Log_Pos
I/O读取到的log在master的binlog中的位置。
Relay_Log_Pos
SQL执行到的Relay Log的位置。
Exec_Master_Log_Pos
SQL执行到的SQL Event在master的binlog中的位置。
如果Read_Master_Log_Pos和master的show master status的位置一样,而Exec_Master_Log_Pos的值小于它们,那说明SQL线程出现了过载,正在执行一个非常熬时间的SQL或者slave服务器的性能出现恶化等等。
主库 binlog 的写入量
主要是看主库 binlog 的生成速度,比如多少分钟生成一个。
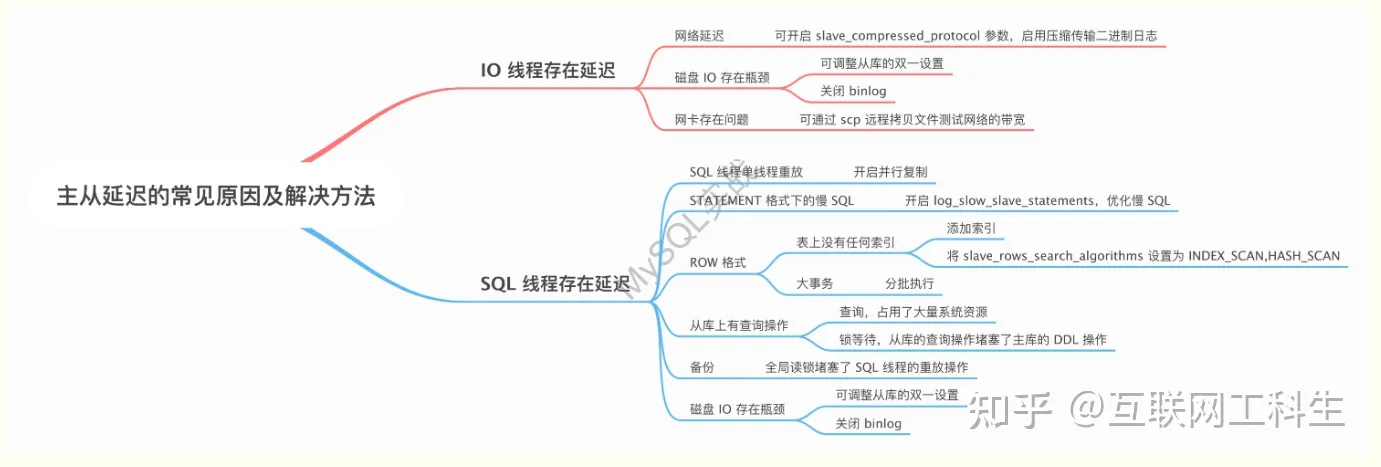
二、主从延迟的常见原因及解决方法
下面分别从 IO 线程和 SQL 线程这两个方面展开介绍。
IO 线程存在延迟
下面看看 IO 线程出现延迟的常见原因及解决方法。
- 网络延迟。
判断是否为网络带宽限制。如果是,可开启 slave_compressed_protocol 参数,启用 binlog 的压缩传输。或者从 MySQL 8.0.20 开始,通过 binlog_transaction_compression 参数开启 binlog 事务压缩。 - 磁盘 IO 存在瓶颈 。
可调整从库的双一设置或关闭 binlog。
注意,在 MySQL 5.6 中,如果开启了 GTID ,则会强制要求开启 binlog ,MySQL 5.7 无此限制。 - 网卡存在问题。
这种情况不多见,但确实碰到过。当时是一主两从的架构,发现一台主机上的所有从库都延迟了,但这些从库对应集群的其它从库却没有延迟,后来通过 scp 远程拷贝文件进一步确认了该台主机的网络存在问题,最后经系统组确认,网卡存在问题。
一般情况下,IO 线程很少存在延迟。
SQL 线程存在延迟
下面看看 SQL 线程出现延迟的常见原因及解决方法。
主库写入量过大,SQL 线程单线程重放
具体体现如下:
- 从库磁盘 IO 无明显瓶颈。
- Relay_Master_Log_File , Exec_Master_Log_Pos 也在不断变化。
- 主库写入量过大。如果磁盘使用的是 SATA SSD,当 binlog 的生成速度快于 5 分钟一个时,从库重放就会有瓶颈。
这个是 MySQL 软件层面的硬伤。要解决该问题,可开启 MySQL 5.7 引入的基于 LOGICAL_CLOCK 的并行复制。
关于 MySQL 并行复制方案,可参考:MySQL 并行复制方案演进历史及原理分析
STATEMENT 格式下的慢 SQL
具体体现,在一段时间内 Relay_Master_Log_File , Exec_Master_Log_Pos 没有变化。
看下面这个示例,对 1 张千万数据的表进行 DELETE 操作,表上没有任何索引,在主库上执行用了 7.52s,观察从库的 Seconds_Behind_Master,发现它最大达到了 7s 。
- mysql> show variables like 'binlog_format';
- +---------------+-----------+
- | Variable_name | Value |
- +---------------+-----------+
- | binlog_format | STATEMENT |
- +---------------+-----------+
- 1 row in set (0.00 sec)
-
- mysql> select count(*) from sbtest.sbtest1;
- +----------+
- | count(*) |
- +----------+
- | 10000000 |
- +----------+
- 1 row in set (1.41 sec)
-
- mysql> show create table sbtest.sbtest1\G
- *************************** 1. row ***************************
- Table: sbtest1
- Create Table: CREATE TABLE `sbtest1` (
- `id` int NOT NULL,
- `k` int NOT NULL DEFAULT '0',
- `c` char(120) NOT NULL DEFAULT '',
- `pad` char(60) NOT NULL DEFAULT ''
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
- 1 row in set (0.00 sec)
-
- mysql> delete from sbtest.sbtest1 where id <= 100;
- Query OK, 100 rows affected (7.52 sec)

对于这种执行较慢的 SQL ,并行复制实际上也是无能为力的, 此时只能优化 SQL。
在 MySQL 5.6.11 中,引入了参数 log_slow_slave_statements ,可将 SQL 重放过程中执行时长超过 long_query_time 的操作记录在慢日志中。
表上没有任何索引,且二进制日志格式为 ROW
同样,在一段时间内,Relay_Master_Log_File , Exec_Master_Log_Pos 不会变化。
如果表上没有任何索引,对它进行操作,在主库上只是一次全表扫描。但在从库重放时,因为是 ROW 格式,对于每条记录的操作都会进行一次全表扫描。
还是上面的表,同样的操作,只不过二进制日志格式为 ROW ,在主库上执行用了 7.53s ,但 Seconds_Behind_Master 最大却达到了 723s ,是 STATEMENT 格式下的 100 倍。
- mysql> show variables like 'binlog_format';
- +---------------+-------+
- | Variable_name | Value |
- +---------------+-------+
- | binlog_format | ROW |
- +---------------+-------+
- 1 row in set (0.00 sec)
-
- mysql> delete from sbtest.sbtest1 where id <= 100;
- Query OK, 100 rows affected (7.53 sec)
如果因为表上没有任何索引,导致主从延迟过大,常见的优化方案如下:
- 在从库上临时创建个索引,加快记录的重放。注意,尽量选择一个区分度高的列添加索引,列的区分度越高,重放的速度就越快。
- 将参数 slave_rows_search_algorithms 设置为 INDEX_SCAN,HASH_SCAN 。
设置后,对于同样的操作,Seconds_Behind_Master 最大只有 53s 。
大事务
这里的大事务,指的是二进制日志格式为 ROW 的情况下,操作涉及的记录数较多。
还是上面的测试表,只不过这次 id 列是自增主键,执行批量更新操作。更新操作如下,其中,N 是记录数,M 是一个随机字符,每次操作的字符均不一样。
update sbtest.sbtest1 set c=repeat(M,120) where id<=N接下来我们看看不同记录数下对应 Seconds_Behind_Master 的最大值。
| 记录数 | 主库执行时长(s) | Seconds_Behind_Master最大值(s) |
|---|---|---|
| 50000 | 0.76 | 1 |
| 200000 | 3.10 | 8 |
| 500000 | 17.32 | 39 |
| 1000000 | 63.47 | 122 |
可见,随着记录数的增加,Seconds_Behind_Master 也是不断增加的。
所以对于大事务操作,建议分而治之,每次小批量执行。
判断一个 binlog 是否存在大事务,可通过我之前写的一个 binlog_summary.py 的工具来分析,该工具的具体用法可参考:Binlog分析利器-binlog_summary.py
从库上有查询操作
从库上有查询操作,通常会有两方面的影响:
1. 消耗系统资源。
2. 锁等待。
常见的是从库的查询操作堵塞了主库的 DDL 操作。看下面这个示例。
- mysql> show processlist;
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- | Id | User | Host | db | Command | Time | State | Info |
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- | 5 | event_scheduler | localhost | NULL | Daemon | 2239 | Waiting on empty queue | NULL |
- | 17 | root | localhost | NULL | Query | 0 | init | show processlist |
- | 18 | root | localhost | NULL | Query | 19 | User sleep | select id,sleep(1) from sbtest.sbtest1 |
- | 19 | system user | connecting host | NULL | Connect | 243 | Waiting for source to send event | NULL |
- | 20 | system user | | | Query | 13 | Waiting for table metadata lock | alter table sbtest.sbtest1 add c2 int |
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- 5 rows in set (0.00 sec)
从库上存在备份
常见的是备份的全局读锁阻塞了 SQL 线程的重放。看下面这个示例。
- mysql> show processlist;
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- | Id | User | Host | db | Command | Time | State | Info |
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- | 5 | event_scheduler | localhost | NULL | Daemon | 4177 | Waiting on empty queue | NULL |
- | 17 | root | localhost | NULL | Query | 0 | init | show processlist |
- | 18 | root | localhost | NULL | Query | 36 | User sleep | select id,sleep(1) from sbtest.sbtest2 |
- | 19 | system user | connecting host | NULL | Connect | 2181 | Waiting for source to send event | NULL |
- | 20 | system user | | | Query | 2 | Waiting for global read lock | alter table sbtest.sbtest1 add c1 int |
- | 28 | root | localhost | NULL | Query | 17 | Waiting for table flush | flush tables with read lock |
- +----+-----------------+-----------------+------+---------+------+----------------------------------+----------------------------------------+
- 6 rows in set (0.00 sec)
磁盘 IO 存在瓶颈
这个时候可调整从库的双一设置或关闭 binlog。
三、总结
综合上面的分析,主从延迟的常见原因及解决方法如下图所示。