
- 1Linux各目录的作用
- 2Stable Diffusion WebUI Tag相关的2个插件_tag插件
- 3Visual Studio Code for Mac(好用的微软代码编辑器)
- 4git 命令动画学
- 5英文论文SCI 1区解读复现【NO.20】Improved YOLOv8-GD deep learning model for defect detection inelectroluminesce_improvedyolov8-gd deep learning model for defect d
- 6文本挖掘与文本自然语言理解:实现计算机与自然语言之间的深度交流
- 7机器学习——python机器学习第2版笔记_python机器学习第二版
- 8化繁为简、性能提升 -- 在WPF程序中,使用Freetype库心得_c# freetype
- 9推荐四款可视化工具,解决99%的可视化大屏需求_jeecgboot可视化设计
- 10spring kafka 设置超时时间(session.timeout.ms和max.poll.interval.ms) 防止出现rebalance
【文档智能 & LLM】LayoutLLM:一种多模态文档布局模型和大模型结合的框架
赞
踩
前言
传统的文档理解任务,通常的做法是先经过预训练,然后微调相应的下游任务及数据集,如文档图像分类和信息提取等,通过结合图像、文本和布局结构的预训练知识来增强文档理解。LayoutLLM是一种结合了大模型和视觉文档理解技术的单模型方法,通过多模态指令数据集的微调来提高对图像文档的理解和分析能力。
LayoutLMv3
在此之前,先简单介绍下LayoutLLM的编码器LayoutLMv3。
概述:文本的布局信息使用了片段级别,一段文本共用一组坐标。视觉借鉴了ViT的方法替换CNN,减少了参数以及省去了很多的预处理步骤。使用了两种新的损失MIM和WPA进行预训练。
paper:LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
link:https://arxiv.org/abs/2204.08387
code:https://github.com/microsoft/unilm/tree/master/layoutlmv3
模型结构
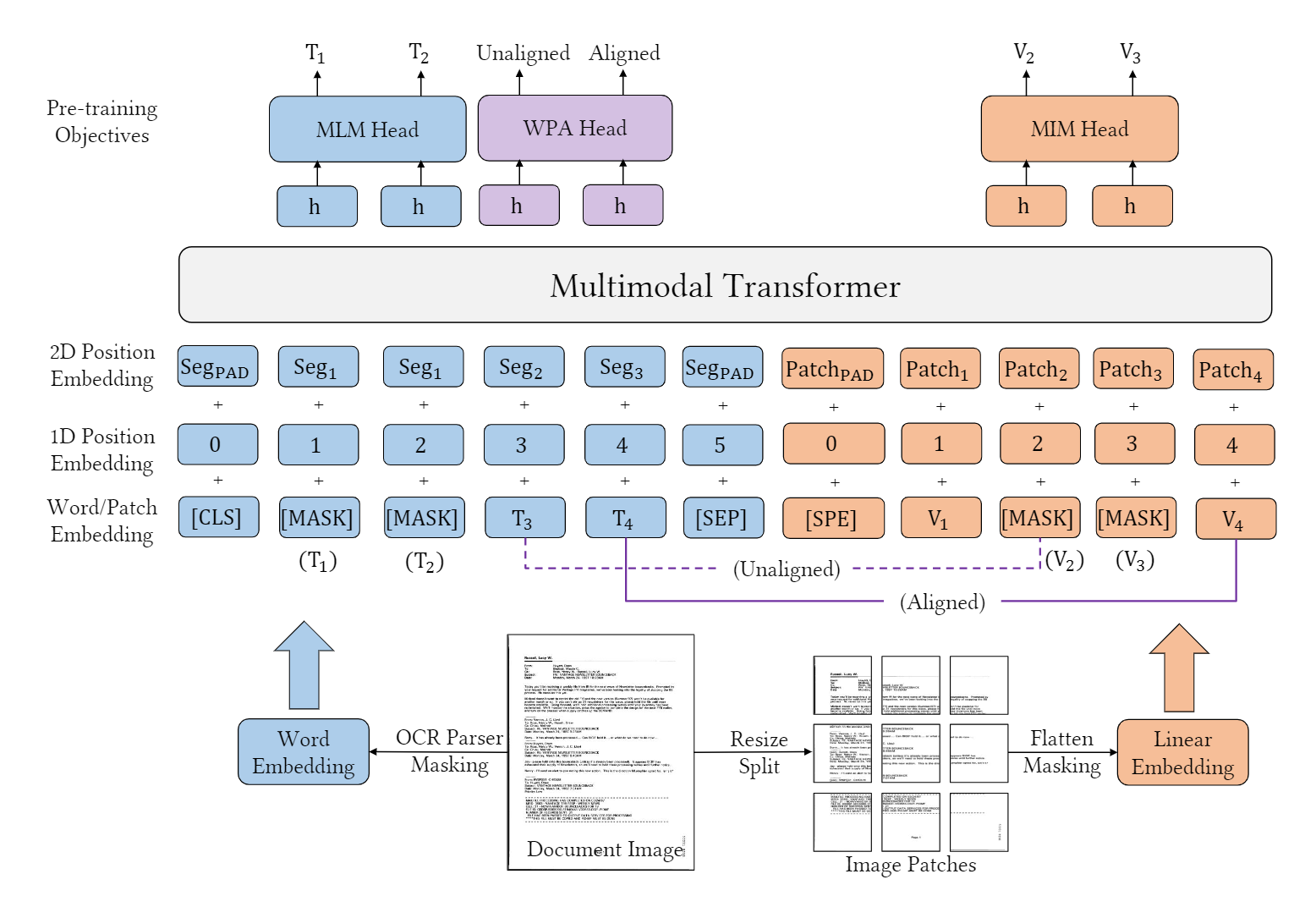
- 文本嵌入:RoBerta backbone
- 视觉嵌入:与layoutLMv2相同,与之前的单词级别的边界框不同,此处使用了片段级别的嵌入,即:块边界框。
- 布局嵌入:不再使用CNN网络,采用类似ViT思想的backbone,将图片切分成一个个的patches。
预训练任务
- Masked Language Modeling (MLM):使用span掩码策略,mask掉30%的文本token,maks的span长度服从泊松分布(λ=3)
- Masked Image Modeling (MIM):
- 用分块掩码策略随机掩盖掉40%的图像token,用交叉熵损失驱动其重建被掩盖的图像区域;
- 图像token的标签来自一个图像tokenizer,通过图像vocab将密集图像的像素转化成离散token,相比于低级高噪声的细节部分,更促进学习高级特征;
- Word-Patch Alignment (WPA):学习文本单词和图像patches之间的细粒度对齐。WPA的目的是预测文本单词的相应图像补丁是否被屏蔽。具体地说,当对应的图像标记也被取消屏蔽时,为未屏蔽的文本标记分配一个对齐的标签[aligned]。否则,将指定一个未对齐的标签[unaligned]。
LayoutLLM
模型架构
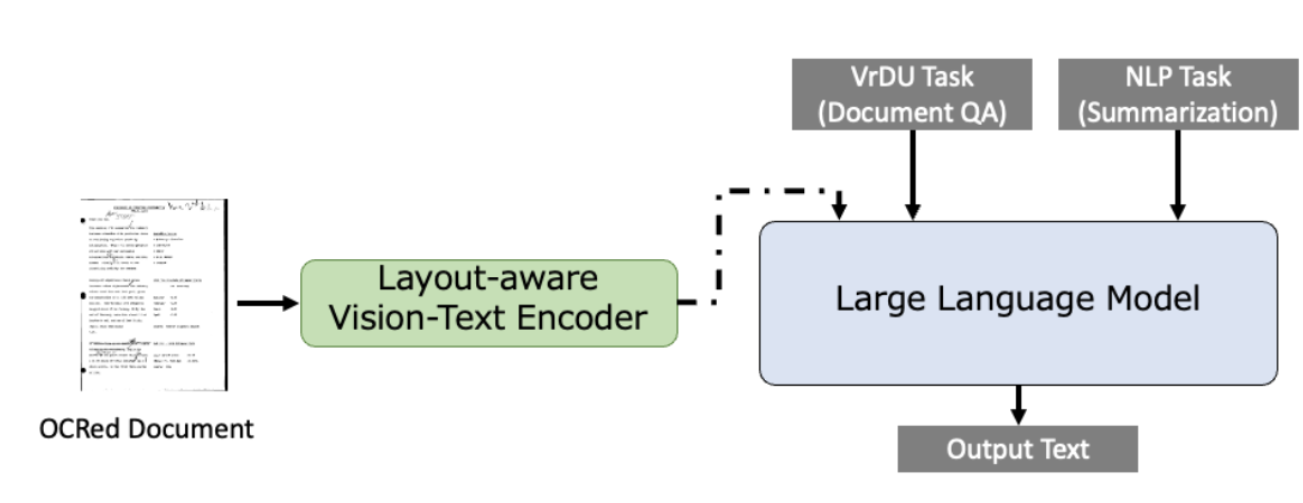
LayoutLLM主要由两部分组成:编码器(Encoder)和解码器(Decoder)。
- 编码器:负责对文档图像进行编码,处理视觉和布局信息。这里使用的是预训练的VrDU模型,特别是LayoutLMv3,它能够捕捉文档的布局结构和文本信息,并生成相应的特征。简单来说就是将OCR文本和视觉信息从文档图像中编码,生成一个最大序列长度为512的一维序列,以便输入到Llama模型中。
- 解码器:基于大型语言模型(LLMs),如Llama,它负责解释任务指令,并使用其语言理解能力来分析文档的文本内容,最终输出结果。
VrDU Prompts
结合大模型,通过对不同的下游任务设定提示词。LayoutLLM能够理解不同类型的VrDU任务,并结合文档的特征来生成适当的响应。这种方法使得单一模型能够灵活地处理多种任务,而不需要为每个任务单独训练模型。
prompt格式
prompt格式和Alpaca模型的格式保持一致:
The previous information is about document images.
Below is an instruction that describes a task. Write a
response that appropriately completes the request.
### Instruction: {instruction}
### Response
- 1
- 2
- 3
- 4
- 5
不同下游任务的prompt示例
-
文档分类:
“执行文档分类。分类标签是...”。- 1
-
文档信息提取:
“执行文档信息提取。分类标签是... 输出格式是一组提取词及其标签,用逗号分隔。如果存在多个提取目标,使用\n作为分隔符并分割输出。”。- 1
这个提示指导模型识别文档中的语义实体,并按照指定的格式输出提取的信息和标签。
-
文档问答:
“执行文档问答。问题是...”。- 1
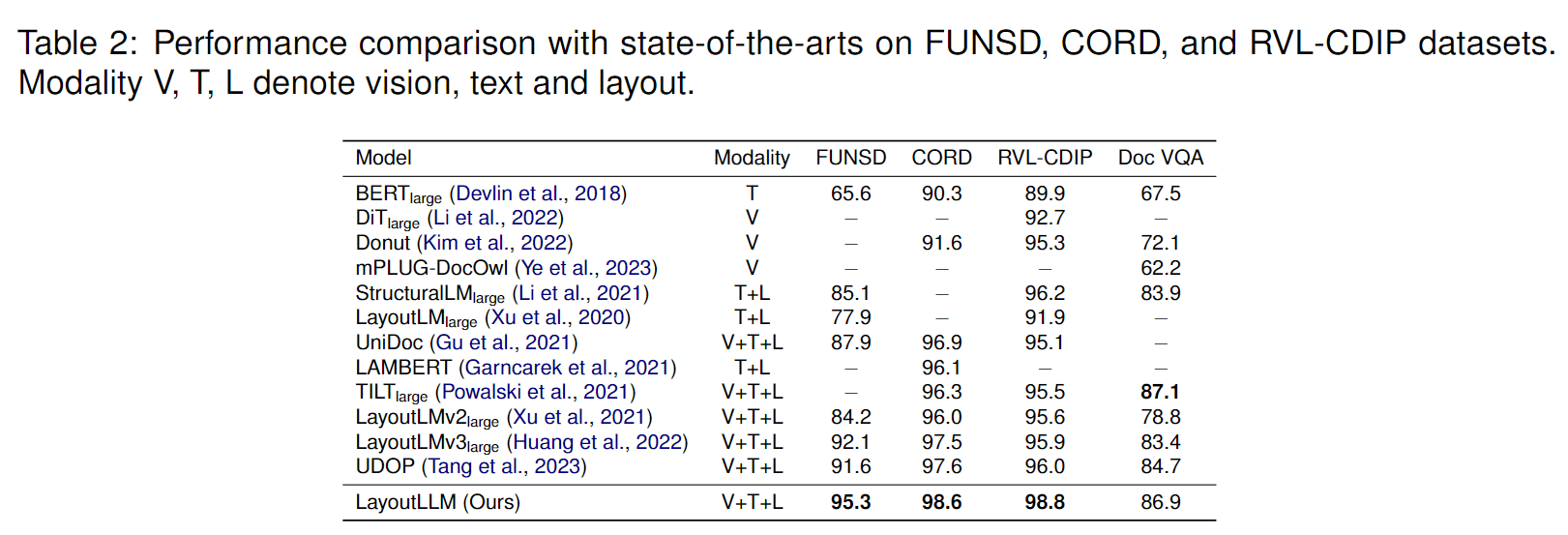
评价

总结
本文介绍了一种传统布局模型结合大模型做文档理解的方法:LayoutLLM。这个框架通过结合VrDU编码器来捕捉文档图像的特征,以及使用LLM作为解码器来处理任务指令,有效地提高了对文档图像的理解和分析能力。
参考文献
【1】LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking,https://arxiv.org/abs/2204.08387
【2】LayoutLLM: Large Language Model Instruction Tuning for Visually Rich Document Understanding,https://arxiv.org/abs/2403.14252

