
热门标签
当前位置: article > 正文
记忆碎片之python爬虫APP数据爬取fiddler抓包及多线程爬取流程分析(四)_python获取fildder
作者:Monodyee | 2024-06-15 09:02:06
赞
踩
python获取fildder
无敌免责声明:本案例用到的app仅仅做为学习使用,切勿使用爬虫程序恶意攻击该服务器。
有了前面三节内容的铺垫,相信对抓包和模拟器配置都有了一些了解,这里实现一个完整的案例,仅做为入门学习记录。
第一步:启动fiddler,并启用抓包
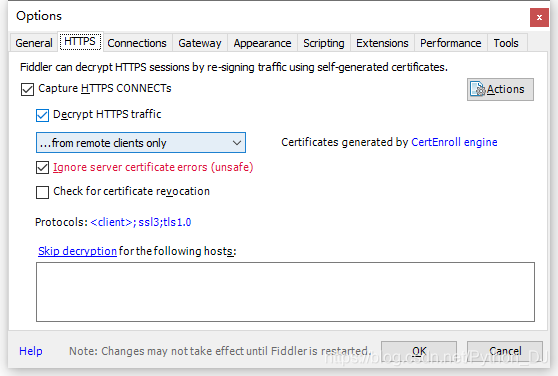
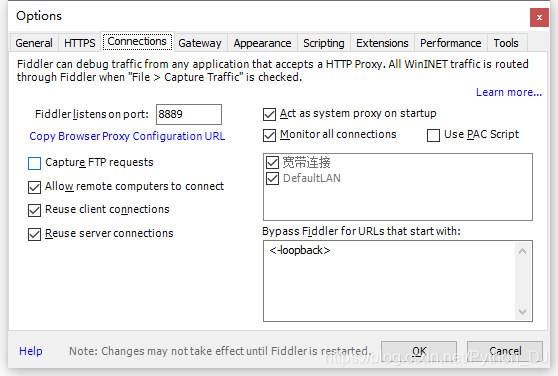
第二步:启动安卓模拟器,设置代理,并启动APP应用,明确抓取内容
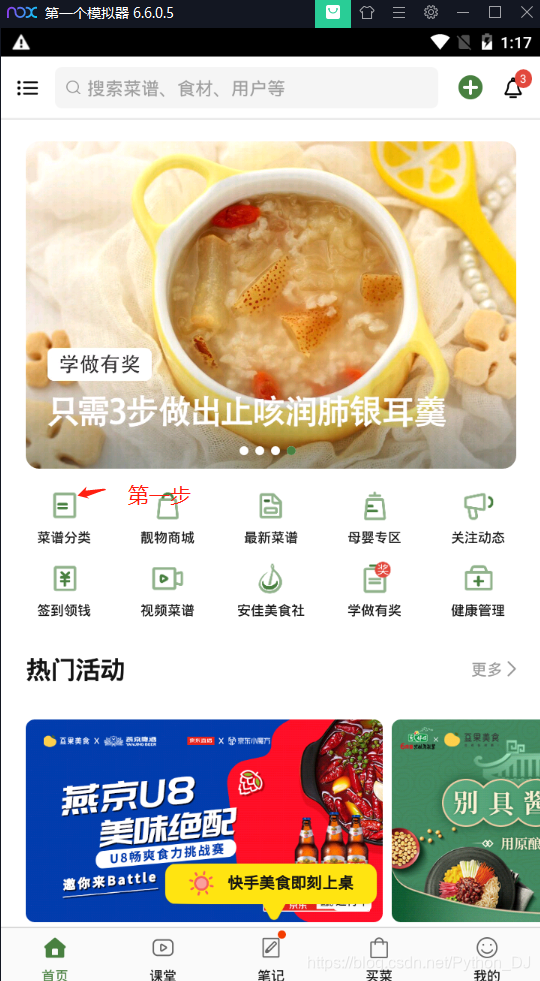
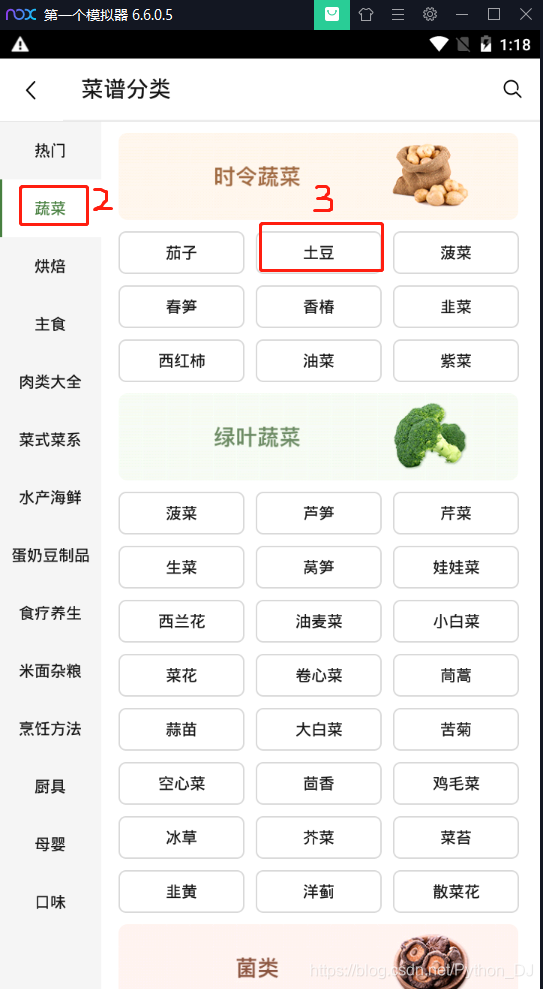

接着向下翻页,滚动鼠标滚轮,之后回到顶部,点击第一个菜谱进入菜谱的详情页,回到fiddler里面,设置停止抓包,在fiddler左下角单机一下,变成空白,就是取消继续抓包

第三步:分析数据包
经过分析,发现数据都是已api.douguo.net为host的方式返回的,不同的数据,用了不同的URL地址
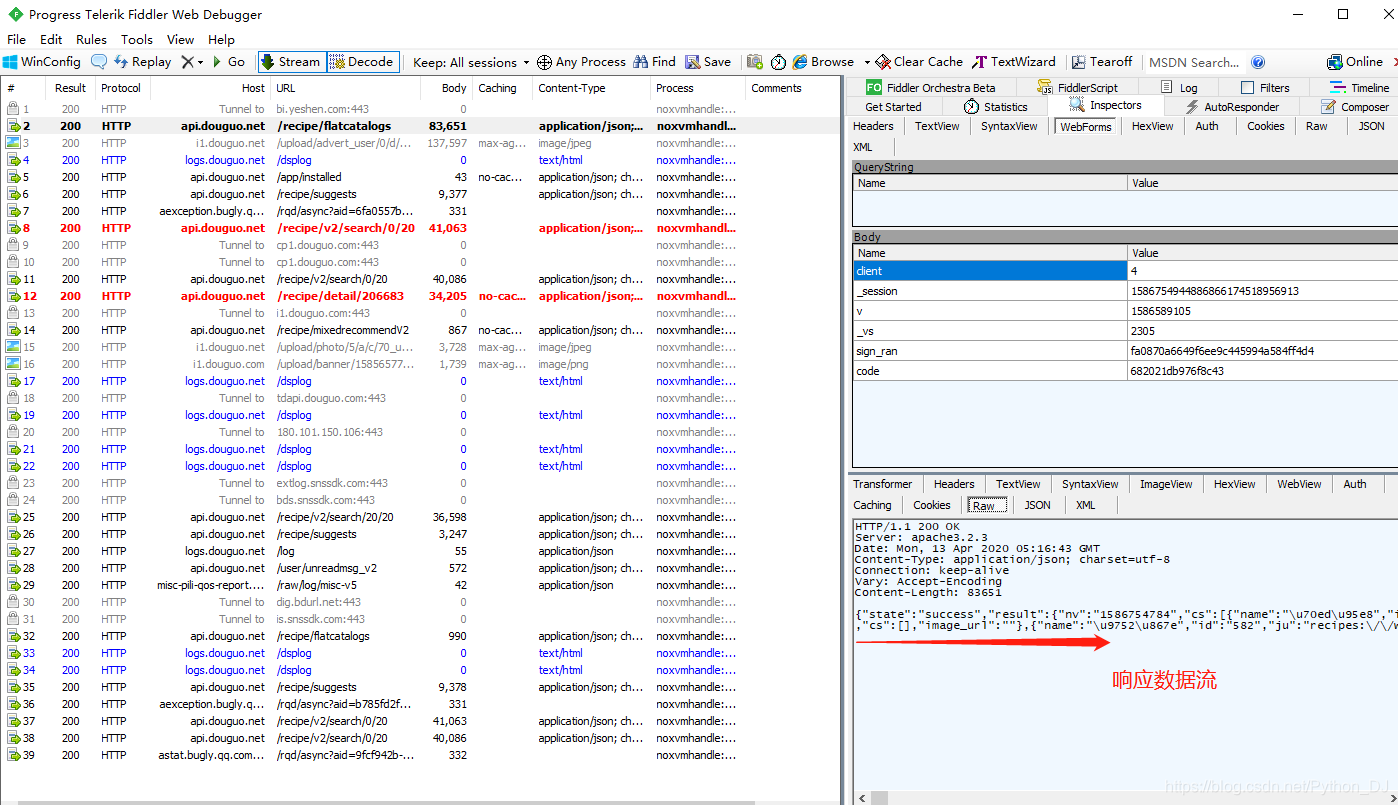
上图fiddler抓包分析之后,红色的请求就是爬虫程序所需要的,可以复制响应数据流到json.cn里面粘贴查看。
分析完这些之后,再分析每一个请求的细节内容
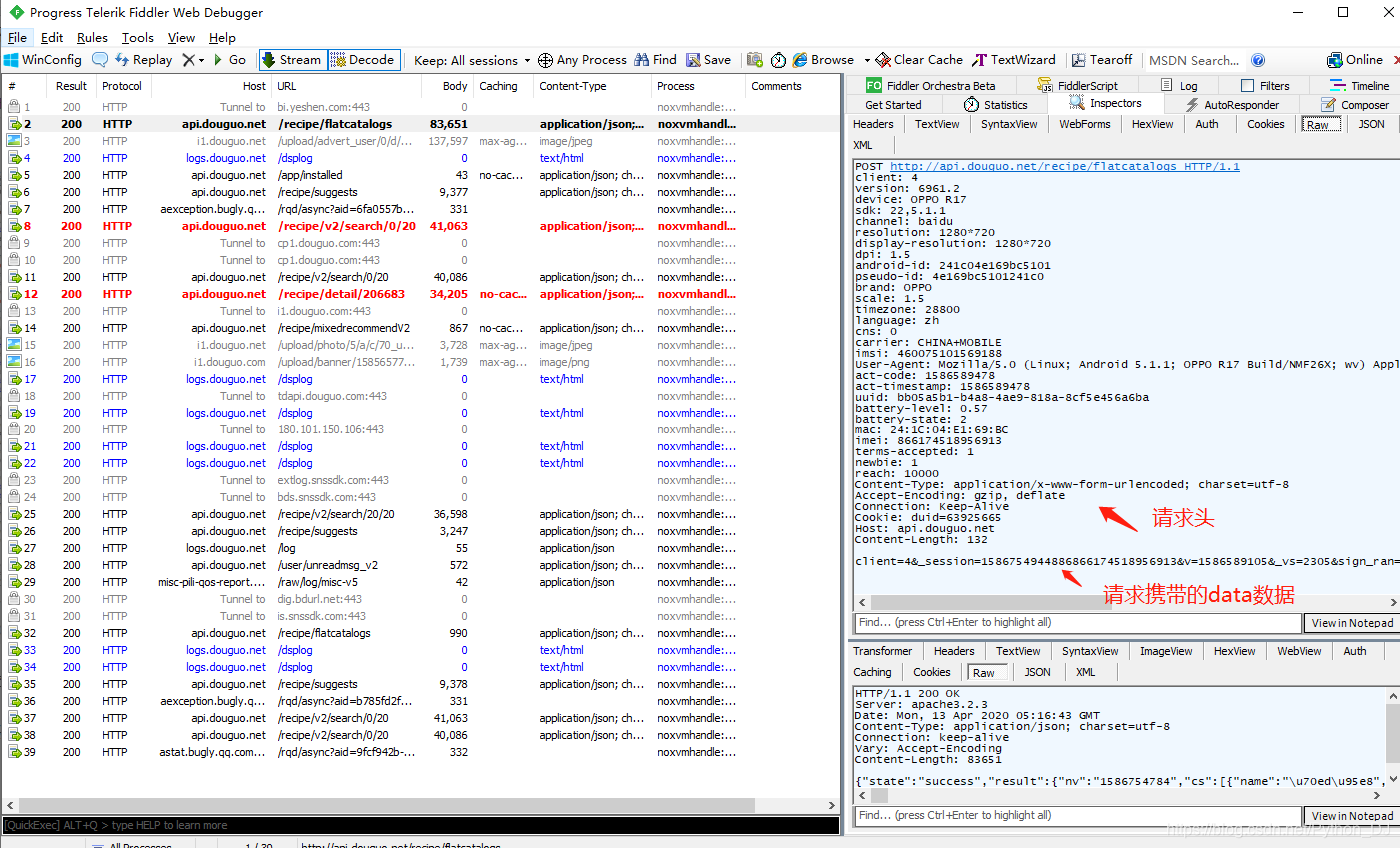
经过三个链接的请求头对比之后,发现三个请求的请求头都是一样的,不同的是每一个请求携带的data数据。
第四步:在编辑器中编写代码
# 记录 # 豆果美食app案例 """ 在夜神模拟器中安装豆果美食apk,安装包可以在本地用浏览器搜索下载 打开fiddler工具,并修改Options的中的内容, 选项卡HTTPS from remote clients only 选项卡 Connections 端口8889 勾选Allow remote computers to connect(运行所有移动设备链接) 启动夜神模拟器的代理设置 """ """ fiddler已经能接收到数据包了,现在我们清空,走一遍app,让fiddler抓包 app走的流程是:首页-菜谱分类-蔬菜-土豆-菜谱-学做多-向下滑动鼠标(翻页操作) 抓包结束,在fiddler使用F12或鼠标点击左下角capture traffic停止抓包 接着来分析抓到的包: 观察发现,api.douguo.net是接口地址,重点查看返回的json数据 使用工具栏的find,在对话框中输入api.douguo.net,然后点击Find Sessions,现在所有域名和api.douguo.net相关的都变为黄色 然后查看这些包的数据,由于编码的问题,把返回数据放到浏览器json.cn里面查看 http://api.douguo.net/personalized/home HTTP/1.1 首页中部分类 http://api.douguo.net/recipe/flatcatalogs HTTP/1.1 点击“菜谱分类”后的所有分类 http://api.douguo.net/recipe/v2/search/0/20 HTTP/1.1 点击“学做多”后的内容 http://api.douguo.net/recipe/v2/search/20/20 HTTP/1.1 翻页操作 http://api.douguo.net/recipe/detail/957058 HTTP/1.1 详情页 """

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
主程序:
import json import requests from multiprocessing import Queue from APP数据抓取.spider_douguo import mogo from concurrent.futures import ThreadPoolExecutor # 创建队列 queue_list = Queue() # 请求函数 def handler_request(url, data): """ :param url: 请求不同页面的链接 :param data: 请求不同页面时所附带的请求数据 :return: 获得的页面结果 """ header = { "client": "4", "version": "6961.2", "device": "OPPO R17", "sdk": "22,5.1.1", "channel": "baidu", "resolution": "1280*720", "display-resolution": "1280*720", "dpi": "1.5", # "android-id": "241c04e169bc5101", # "pseudo-id": "4e169bc5101241c0", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "0", "carrier": "CHINA+MOBILE", # "imsi": "460075101569188", "User-Agent": "Mozilla/5.0 (Linux; Android 5.1.1; OPPO R17 Build/NMF26X; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.136 Mobile Safari/537.36", "uuid": "bb05a5b1-b4a8-4ae9-818a-8cf5e456a6ba", "battery-level": "0.86", "battery-state": "2", "terms-accepted": "1", "newbie": "1", # "mac": "24:1C:04:E1:69:BC", "imei": "866174518956913", # 这个不能去掉 ,这个是手机的ID,在模拟器里可查看 "reach": "10000", "act-code": "1586589478", "act-timestamp": "1586589478", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", # "Cookie": "duid=63925665", "Host": "api.douguo.net", # "Content-Length": "13", } # 在这里添加代理,当前代理链接已失效,只说明如何使用 # proxy = {"http": "http://H211EATS905745KC:F8FFBC929EB7D5A7@http-cla.abuyun.com:9030"} # response = requests.get(url=url, proxies=proxy) response = requests.post(url=url, headers=header, data=data) return response # 分类菜谱 def handle_index(): """ :return: 获取所有分类的名字,重组请求列表页的请求数据,并把数据放入队列,等待代用 """ url = "http://api.douguo.net/recipe/flatcatalogs" data = {"client": 4, # "_session": 1586589481759866174518956913, # "v": 1503650468, "_vs": 2305, # "sign_ran": "342696dee05600e1981d6cf95dfe22e9", # "code": "22a8091f41d1c9bb" } response = handler_request(url=url, data=data) # print(response.text) index_response_dict = json.loads(response.text) for index_item in index_response_dict["result"]["cs"]: for index_item_sub in index_item["cs"]: for item in index_item_sub["cs"]: # print(item) # 详情页client=4&_session=1586589481759866174518956913&keyword=%E5%9C%9F%E8%B1%86&order=3&_vs=11104&type=0&auto_play_mode=2&sign_ran=e31f5e1a08d5ea07b9e79a5d88f9a9df&code=a71450a7a3827c7a # 解码后client=4&_session=1586589481759866174518956913&keyword=土豆&order=3&_vs=11104&type=0&auto_play_mode=2&sign_ran=e31f5e1a08d5ea07b9e79a5d88f9a9df&code=a71450a7a3827c7a # 请求菜谱列表时要用到的请求数据 data_detail = { "client": "4", "_session": "1586589481759866174518956913", "keyword": item["name"], "order": "3", "_vs": "11104", "type": "0", "auto_play_mode": "2", # "sign_ran": "e31f5e1a08d5ea07b9e79a5d88f9a9df", # "code": "a71450a7a3827c7a", } # print(data_detail) queue_list.put(data_detail) # 菜谱列表及详情页 def handle_caipu_list(data): """ :param data: 所有分类的名字 :return: 根据类名获取到分类列表,并第二次请求获取详情页数据,最后把组合的字典数据写入MongoDB数据库 """ print("当前处理的食材:", data["keyword"]) caipu_list_url = "http://api.douguo.net/recipe/v2/search/0/20" caipu_list_response = handler_request(url=caipu_list_url, data=data) # print(caipu_list_response.text) caipu_list_response_dict = json.loads(caipu_list_response.text) for item in caipu_list_response_dict["result"]["list"]: # print(item) caipu_info = {} caipu_info["shicai"] = data["keyword"] if item["type"] == 13: caipu_info["user_name"] = item["r"]["an"] caipu_info["shicai_id"] = item["r"]["id"] caipu_info["describe"] = str(item["r"]["cookstory"]).replace("\n", "").replace(" ", "") caipu_info["caipu_name"] = item["r"]["n"] caipu_info["zuoliao_list"] = item["r"]["major"] caipu_info["pingfen"] = item["r"]["rate"] caipu_info["people"] = item["r"]["recommendation_tag"] # print(caipu_info) detail_url = f"http://api.douguo.net/recipe/detail/{str(caipu_info['shicai_id'])}" detail_data = { "client": "4", "_session": "1586589481759866174518956913", "author_id": "0", "_vs": "11101", "is_new_user": "1", # "sign_ran": "f98f1a6b40400f36fb07ec13242d5033", # "code": "04765aa8dc22d71d" } detail_response = handler_request(url=detail_url, data=detail_data) # print(detail_response.text) detail_response_dict = json.loads(detail_response.text) caipu_info["tips"] = detail_response_dict["result"]["recipe"]["tips"] caipu_info["cook_step"] = detail_response_dict["result"]["recipe"]["cookstep"] # print(json.dumps(caipu_info, ensure_ascii=False)) # Connect_mongo.insert_item(caipu_info) mogo.mongo_info.insert_item(caipu_info) else: continue if __name__ == '__main__': handle_index() pool = ThreadPoolExecutor(max_workers=20) print(queue_list.qsize()) # 查看总共有多少数据 while queue_list.qsize() > 0: pool.submit(handle_caipu_list, queue_list.get()) # 没有使用多进程的代码 # handle_caipu_list(queue_list.get()) # for _ in range(queue_list.qsize()): # handle_caipu_list(queue_list.get())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
如果有代理时,测试代理,这里仅用来参考,并没有使用代理
import requests
url = "http://ip.hahado.cn/ip" # 专门用来测试IP的一个链接
proxy = {"http": "http://H211EATS905745KC:F8FFBC929EB7D5A7@http-cla.abuyun.com:9030"}
# proxy = {"ip": "180.126.44.136"}
response = requests.get(url=url, proxies=proxy)
# print(response.text) {"ip":"180.126.44.136","locale":""}
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
MongoDB插入数据的代码
# 在Linux中使用yum安装MongoDB的安装 # /etc/init.d/mongod status 查看MongoDB运行的状态 # netstat -an | grep 27017 查看端口进程 # mongo exit退出 # liunx下载太慢,用win10 import pymongo from pymongo.collection import Collection # https://www.mongodb.com/download-center/community class Connect_mongo(object): def __init__(self): self.client = pymongo.MongoClient(host="127.0.0.1", port=27017) self.db = self.client["douguo"] # 自定义数据库名 # 插入数据的方法 def insert_item(self, item): # 数据库名 自定义表名 db_collection = Collection(self.db, "douguo_item") db_collection.insert_one(item) mongo_info = Connect_mongo() # mongo_info.insert_item({"aa": "bb"})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
附:因为从fiddler中复制的data和请求头等数据都是原始的,然而在使用的时候要转换成字典格式
# 原始数据 client=4&_session=1586754944886866174518956913&author_id=0&_vs=11101&is_new_user=1&sign_ran=293eba6ee05e51218b100efbd1941db2&code=695e2bb1c2fb7d6f # 处理之后的数据 "client":"4", "_session":"1586589481759866174518956913", "author_id":"0", "_vs":"11101", "is_new_user":"1", "sign_ran":"f98f1a6b40400f36fb07ec13242d5033", "code":"04765aa8dc22d71d", # 下面二行是替换操作 用后面的字符替换前面的字符 # & \n 请求头不用替换换行 # = : # 下面这一行是正则匹配替换 # (.*?):(.*) "$1":"$2",
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
第五步:安装配置MongoDB数据库
步骤自行百度并操作安装配置,我用的是4.2版本的,这个是下载地址https://www.mongodb.com/download-center/community
安装的时候,由于我的硬盘不是固态,最后会卡在进度条,一直等着就行了,我等了一个小时左右
至于配置,现在几乎不需要怎么配置就可以使用了,就连系统服务都是已经配置好了
最后运行爬虫,数据库保存数据如下
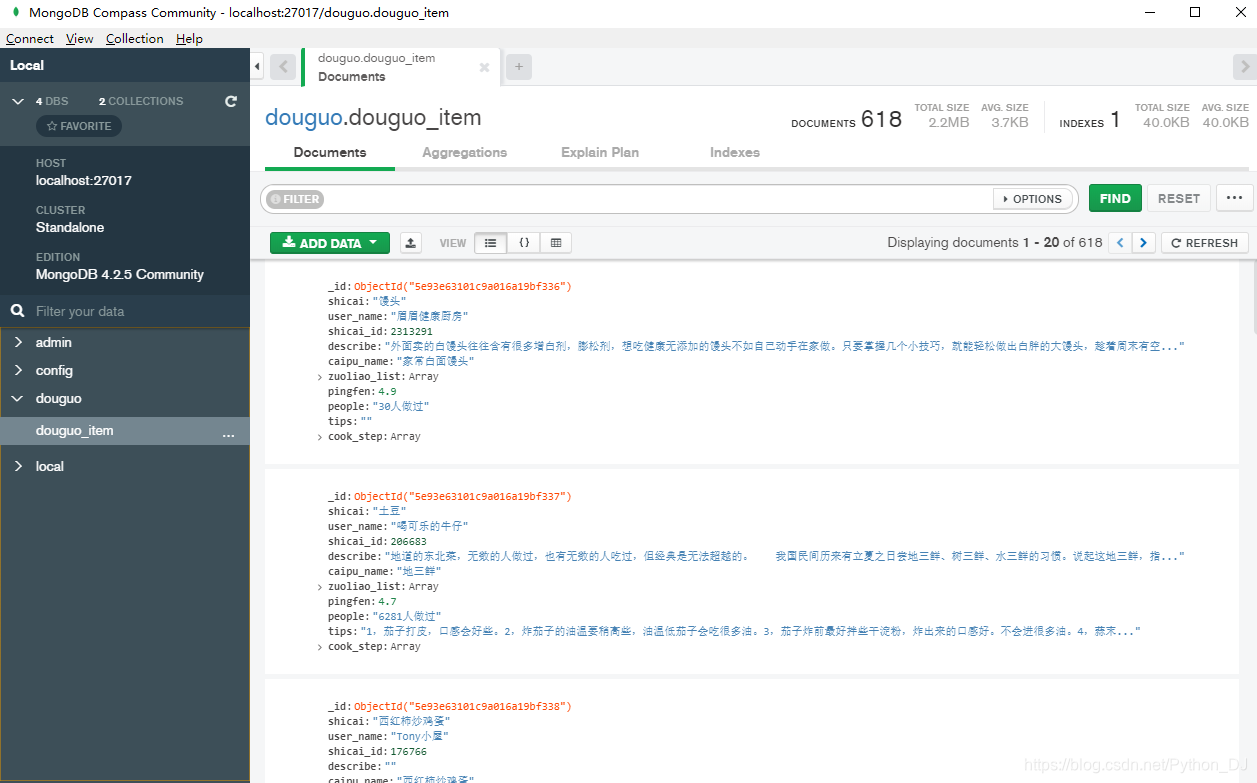
第六步:总结
这个只是一个练手的入门小项目,没有涉及到其他的反爬手段。
再次声明,注意节操,学习时适当爬取数据,用于测试就行,切勿恶意破坏服务器
仅做学习记录和参考,不可用于其他商业盈利目的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/721684
推荐阅读
相关标签

