
- 1【已解决】java.lang.IllegalStateException: Only fullscreen opaque activities can request orientation
- 2关于F5负载均衡你认识多少?
- 3使用谷歌地图在 Flutter 应用中添加地图_flutter google map
- 4宇树科技A1机器狗开源QP-MPC-Controller仿真环境搭建及运行_宇树机器狗是否开源
- 5sql server 数据库添加新用户,赋予权限_sql2019给用户授权
- 6Python毕业设计基于django的社区问答网站与设计(源码+系统+mysql数据库+Lw文档)_pycham如何实现某个领域的知识问答系统
- 7指针空间的申请和释放
- 8Pytorch学习率衰减基本方法
- 9React + 项目(从基础到实战) -- 第三期
- 10java算法编程题(60题)
大模型相关整理
赞
踩
机器学习
模型就是函数,这个函数可能是一个很简单的线性函数,也可以是一个非常复杂的高阶函数、或者是一个多层的神经网络函数。
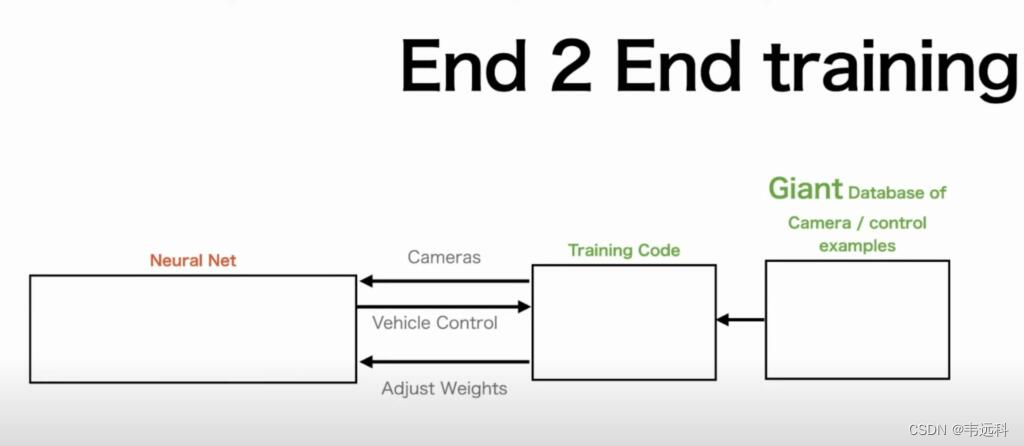
机器学习领域的很多研究和方法都是在尝试设计这个函数,以自动驾驶领域为例,之前的自动驾驶基于人类的经验和思考,将这个函数设计分为了好几个阶段:感知、定位(高精度地图等)、决策、执行等几个阶段,然后对每个阶段求解目标函数。
而特斯拉最近的端到端驾驶方案,则完全颠覆了之前的基于规则和人类经验的方案,直接用一个神经网络来描述自动驾驶这个函数,函数的输入是汽车给个角度摄像头的视频流,函数的输出则是方向盘的转动角度、刹车的力度等对汽车的控制行为。特斯拉基于真实的驾驶视频流,来训练出这个神经网络,从而将人类的驾驶经验传给计算机。https://www.teslarati.com/tesla-fsd-beta-v12-2-employees/

大模型简介
大模型的定义
- 也叫基础大模型(Foundation Model):包括大语言模型(LLM)、
- 底层通常是深度神经网络;
- 具有大规模的参数:10亿、百亿、千亿、万亿;
- 具有复杂的神经网络结构;
- 采用海量数据训练而成;
大模型的发展历程
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT 对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
大模型分类
代码
- from transformers import pipeline
-
- generator = pipeline("text-generation", model="distilgpt2")
- generator(
- "In this course, we will teach you how to",
- max_length=30,
- num_return_sequences=2,
- )
以上代码会自动从huggingface下载一个训练好的模型“distilgpt2”,采用该模型来进行文本续写;
相关背景信息
- 一个100B(1000亿)参数的预训练模型,大致需要220G的GPU内存去加载;
- 可以通过调整参数的精度,来降低模型加载所需要的资源;
- deepmind的一个论文指出,https://huggingface.co/papers/2203.15556,模型参数的比例和训练的数据集大小存在一个指导性的原则:控制模型参数的数量,尽量增加训练数据集的大小,也就是小模型,大数据;
部分观点
陆奇 《我的大模型世界观》——掘金卖铲
- 今天大部分数字化产品和公司,本质是信息搬运公司。
- 这个时代跟淘金时代很像,如果你那个时候去加州淘金,一大堆人会死掉。但是卖勺子、卖铲子的人永远可以赚钱。——AI时代的铲子是什么?
-
- 数据并不是金矿,在数据里成长出来的成功商业模式才是金矿;
- 数据、算力、模型、应用,四大要素;其中数据、算力(ai infra、ai中间件)是铲子,是勺子;
-
- 马斯克twitter不再提供给ai训练使用;
- 纽约时报起诉openai;
- “AI Infra是连接算力和应用的AI中间层基础设施,涵盖了数据准备、模型训练、模型部署和应用整合等环节,其中的基础软件工具有较高商业化潜力;目前AI Infra产业处于高速增长的发展早期,未来3-5年内各细分赛道有望保持30%+高速增长。”
《Thousands of AI Authors on the Future of AI》
到2027年,AI有10%的概率将战胜人类,到2047年这一概率升至50%;2037年有10%的工作能自动化完成,从而解放劳动力,到2116年这一数字升至50%。
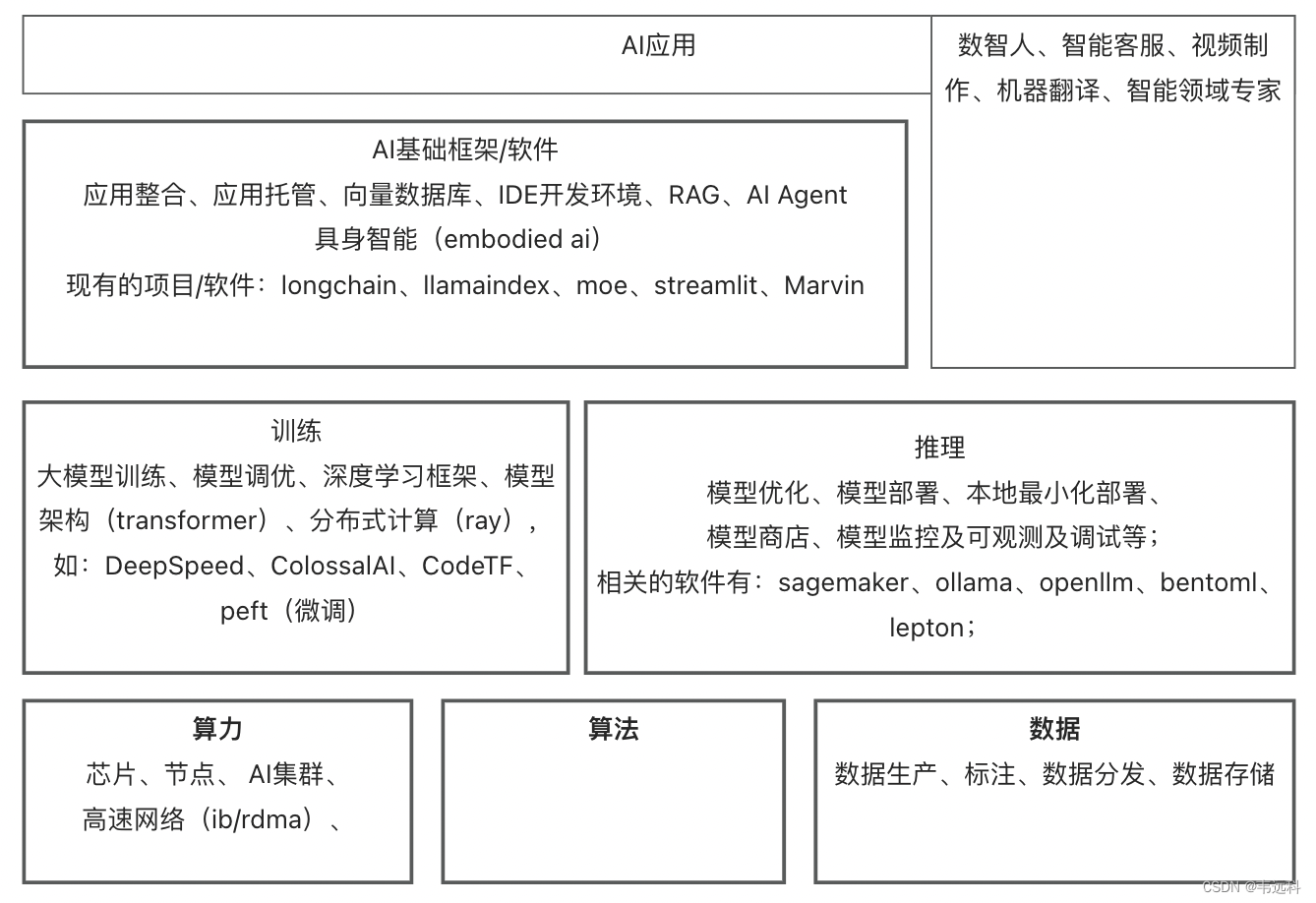
大模型上下游整理
- GPU节点镜像的制作:测试、release、上架;
- 节点的管理:基础环境(时间、软件仓库)、组件的安装管理;
- 数据分发
-
- 数据的加速策略:自动预热、
- 支持rdma网络,传输速率;
- 存储和GPU的混部,
- 开发部署生命周期提效
- LLM as Controller的项目做一个拆解,不同项目的主要差别在于LLM as Controller的逻辑以及各个专项Agent的能力,主要包含Visual ChatGPT、HuggingGPT、Toolformer、AutoGPT等项目。
AI Infra

涉及如下几个点:
- 数据准备,高质量的标注数据和特征库需求将持续增长,未来海量训练数据的需求或由合成数据满足
- 模型训练,底层分布式计算引擎和训练框架
- 模型部署
- 应用整合,LLMOps平台型产品
| 数据准备 |
|
| 模型开发训练 |
|
| 模型部署 |
|
| 应用整合 |
|
部分创业公司
- BentoML:
-
- 自研了OpenLLM
- 从模型部署切入,让AI开发开箱即用
- BentoCloud
- GitHub - bentoml/BentoML: Build Production-Grade AI Applications
- 和贾扬清做的lepton非常类似;
- lepton ai
-
- 贾扬清;
- Build AI The Simple Way | Lepton AI
- https://www.youtube.com/watch?v=rgjkmmSg6I8
- 把模型以及相关的依赖打包成一个photon,然后在本地和远端可以运行该photon;比如以下的语句基于gpt2创建了一个photon,背后还是调用huggingface去拉取gpt2模型;如:/api/models/gpt2
- lep photon create --name mygpt2 --model hf:gpt2
-
- lep photon run --name mygpt2 --local
-
- lep photon run --name mygpt2 --deployment-name mygpt2
-
- Scaleway:Scaleway 是一家法国云计算公司,提供各种容器托管服务。Scaleway 使用大模型来自动化容器平台的资源分配、故障处理和安全监控。
- Forescout:Forescout 是一家网络安全公司,提供网络安全解决方案。Forescout 使用大模型来分析容器的网络流量,并检测安全威胁。
- Enigma.ai:Enigma.ai 是一家瑞士公司,提供隐私保护解决方案。Enigma.ai 使用大模型来在保护数据隐私的情况下,分析容器平台的数据。
- Seldon:Seldon 是一家美国公司,提供机器学习模型部署平台。Seldon 使用大模型来为容器平台上的机器学习模型提供可解释性。
什么是大语言模型?
- 基于大量数据训练出来的神经网络,规模很大,比如175B参数;
- 可以应用于:文本翻译、摘要、聊天机器人;
- 底层的神经网络架构,大语言模型基本上都采用transformer架构;


Transformer
transformer, 2017年google提出的;在自然语言处理上碾压RNN、LSTM等模型,主要是注意力机制;
- 循环神经网络(RNNs)不使用注意力机制,而是逐个单词地遍历输入。相比之下,Transformer能同时处理整个输入序列。同时处理整个输入序列意味着Transformer的工作速度更快,并且能处理输入序列中单词之间更复杂的联系。
- 长短期记忆网络(LSTMs)使用隐藏状态来记住过去发生的事情。然而,当存在太多层时(也称为梯度消失问题),它们可能难以学习。与此同时,转换器表现得更好,因为它们可以同时查看所有输入和输出单词,并找出它们之间的关系(这要归功于它们巧妙的注意力机制)。由于注意力机制,它们非常擅长理解单词之间的长期联系。
有一篇论文,attension is all you need。https://arxiv.org/pdf/1706.03762.pdf

- 文本嵌入:token,vector;
-
- 文字首先被拆分成token,token并不是一个word,可能是word的一部分;
- token -> word embeding; 一个向量,词的相似度;
- 位置编码:词的位置信息被编码进输入的vector中;
- 编码层/self-attention:Multiple layers of the encoder are used in the transformer.
-
- self-attention, 理解词和词之间的关系;
transformer架构在2017年提出,原本是应用与翻译领域的;基于transformer架构产生了一系列的大模型,比如:
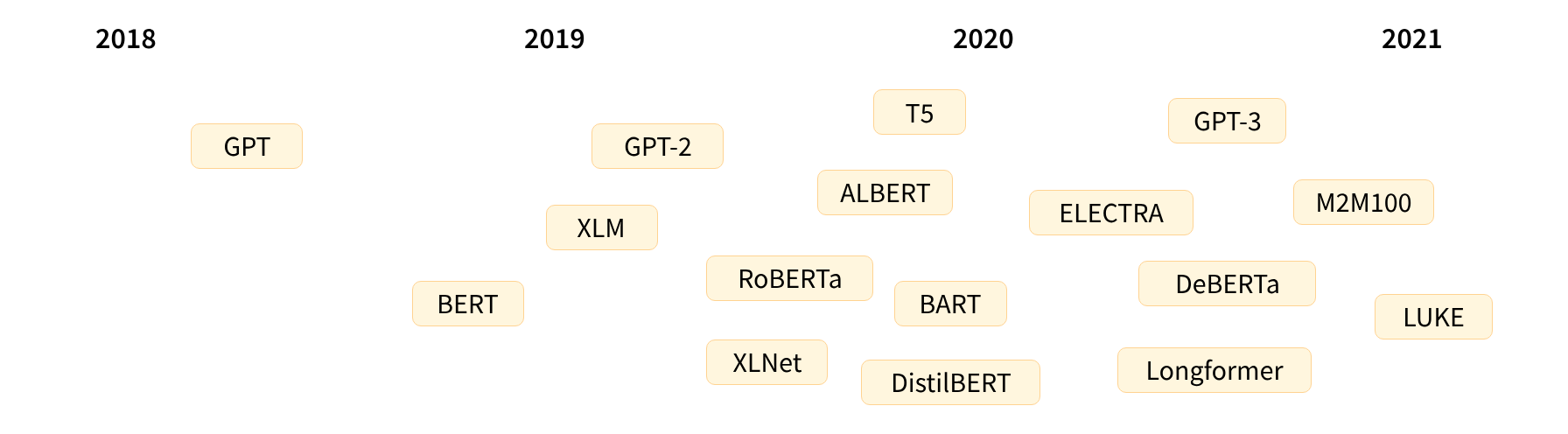
随着时间的演进,模型的规模越来越大。为了训练模型,投入的金钱、数据、能源也指数级增长。但简单来讲,模型的训练分为两类,从0到1训练模型、以及基于存量模型的调优;
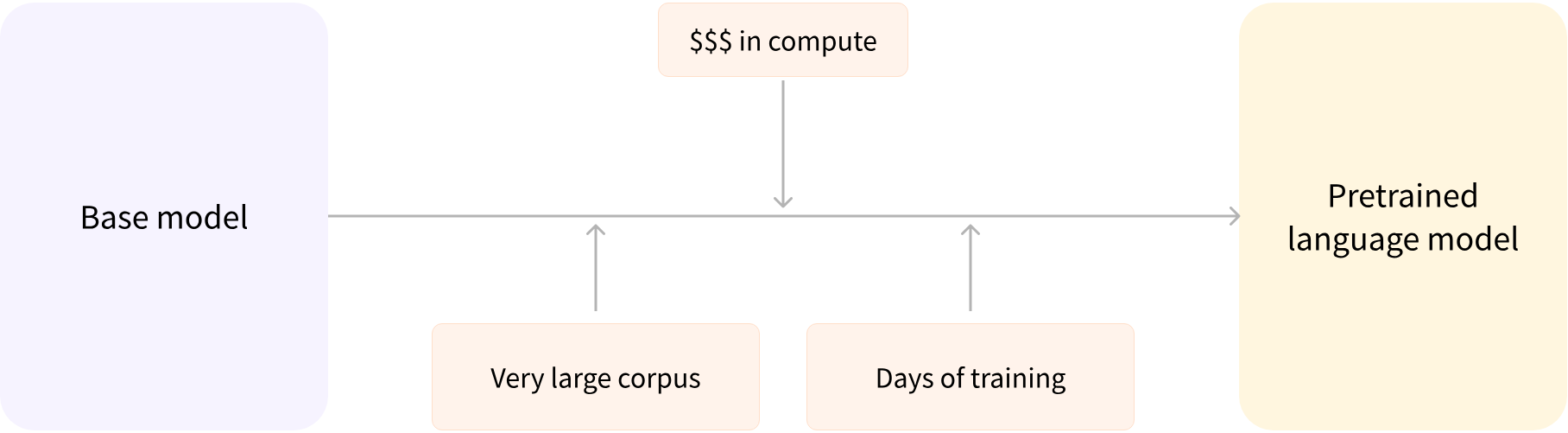
相比从0到1,模型的调优在成本上会低很多,比如采用arXiv数据集在基础大模型的基础上训练一个针对科研人员的特定领域大模型。

transformer架构分为两部分:decoder、encoder;详细的介绍参考论文:https://arxiv.org/abs/1706.03762
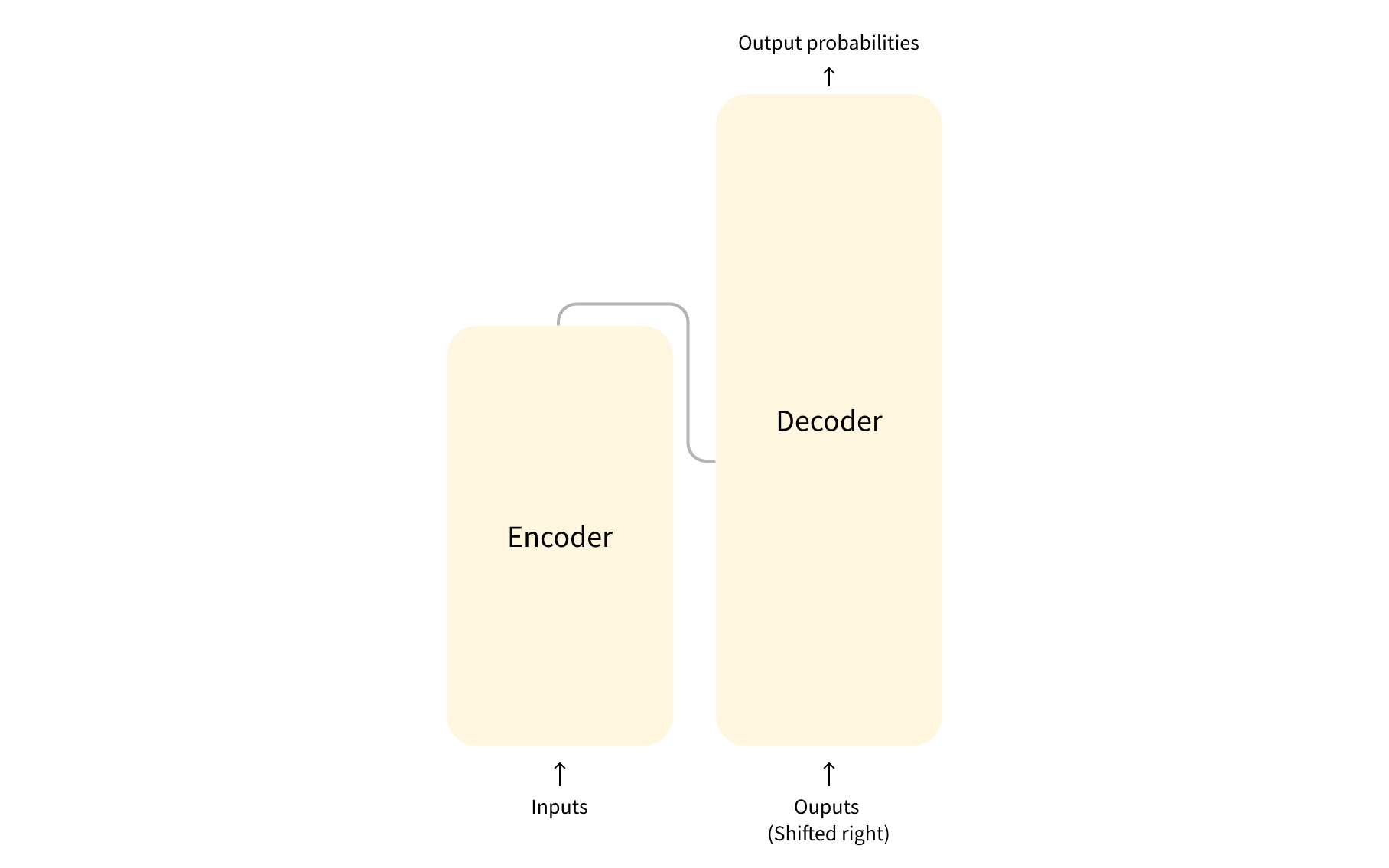
- encoder:编码器接收输入并构建其表示(其特征)。这意味着模型被优化以从输入中获得理解。
- decoder:解码器使用编码器的表示(特征)以及其他输入来生成目标序列。这意味着模型是针对生成输出进行优化的。
LongChain

代码演示:hf_train_test.py
模型调优
优化模型参数
-
- 基于领域数据集再训练;
-
-
- 本地训练演示,hf_train_test.py
-
-
- 高效调参PEFT;
RAG(retrieval-augmented generation)
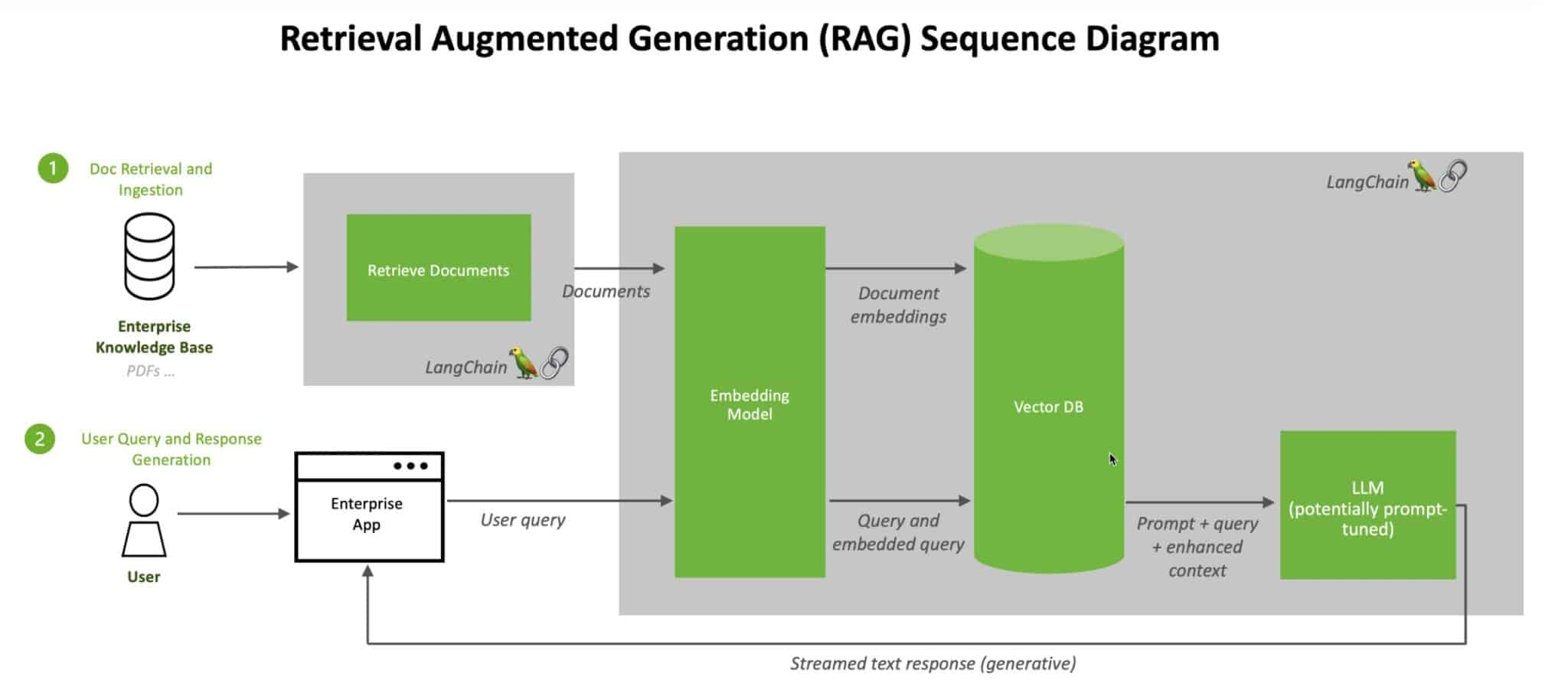
RAG VS SFT
| RAG | SFT | |
| Data | 动态数据。 RAG 不断查询外部源,确保信息保持最新,而无需频繁的模型重新训练。 | (相对)静态数据,并且在动态数据场景中可能很快就会过时。 SFT 也不能保证记住这些知识。 |
| External Knowledge | RAG 擅长利用外部资源。通过在生成响应之前从知识源检索相关信息来增强 LLM 能力。 它非常适合文档或其他结构化/非结构化数据库。 | SFT 可以对 LLM 进行微调以对齐预训练学到的外部知识,但对于频繁更改的数据源来说可能不太实用。 |
| Model Customization | RAG 主要关注信息检索,擅长整合外部知识,但可能无法完全定制模型的行为或写作风格。 | SFT 允许根据特定的语气或术语调整LLM 的行为、写作风格或特定领域的知识。 |
| Reducing Hallucinations | RAG 本质上不太容易产生幻觉,因为每个回答都建立在检索到的证据上。 | SFT 可以通过将模型基于特定领域的训练数据来帮助减少幻觉。 但当面对不熟悉的输入时,它仍然可能产生幻觉。 |
| Transparency | RAG 系统通过将响应生成分解为不同的阶段来提供透明度,提供对数据检索的匹配度以提高对输出的信任。 | SFT 就像一个黑匣子,使得响应背后的推理更加不透明。 |
| Technical Expertise | RAG 需要高效的检索策略和大型数据库相关技术。另外还需要保持外部数据源集成以及数据更新。 | SFT 需要准备和整理高质量的训练数据集、定义微调目标以及相应的计算资源。 |
Promt Engeering
AI Agent
AI Agent是指人工智能代理(Artificial Intelligence Agent),是一种能够感知环境、进行决策和执行动作的智能实体。
举个例子,AI Agent 就像是一个小爱同学,住在你的手机或电脑里,有智慧和观察能力。
当你对它说:“小爱同学,我有点不舒服。”
它会像魔法一样,通过观察你的状态、体温,还有最近 24 小时的行动轨迹,并结合互联网上的数据和信息,通过一系列眼花缭乱的分析,在 1s 钟后得出结论,你「阳」了。
然后主动给你生成请假条,你点点头请假单就发给你 leader 了。
还贴心的告诉你,家里布洛芬和矿泉水已经不够了,已经帮你选好商品,只要你一声令下,30分钟后会送到家门口。
它感知到,现在开车并不是一个好的想法,就顺手把你回家的车也叫好了,10分钟后就到楼下,赶紧撤吧。
这就是一系列的 Agent 协同工作的结果。
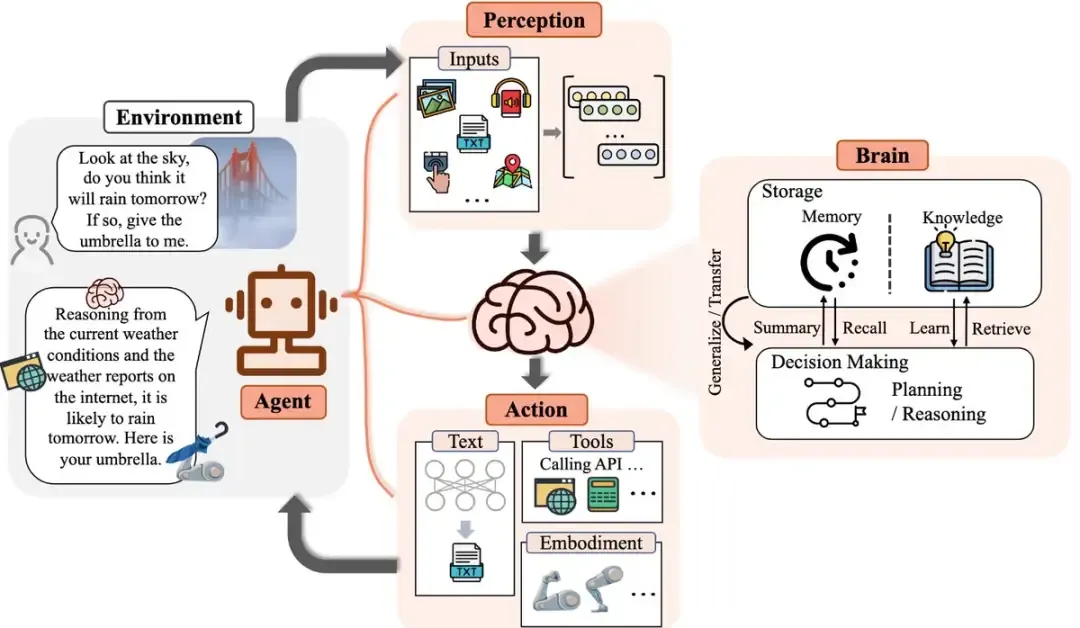
- AI Agent • Supercharge Your Workflows with AI
- AutoGPT Official
- Lilian Weng个人博客: AI Agents即将大爆发 Lilian Weng个人博客: AI Agents即将大爆发 - 知乎
系统课程学习
- 李宏毅 2021 Machine Learning课程
-
- 课程大纲:ML 2021 Spring
- 包含了完整的视频、ppt、homework等资料;
- 李宏毅完整的课程列表:Hung-yi Lee
- hugging face自学课程:https://huggingface.co/learn/nlp-course/chapter0/1?fw=pt
零散资料
- transformers:架构、培训和使用,https://scholar.harvard.edu/sites/scholar.harvard.edu/files/binxuw/files/mlfs_tutorial_nlp_transformer_ssl_updated.pdf
- From Transformer to LLM: Architecture, Training and Usage | Binxu Wang
- Binxu Wang
- 大规模语言模型:从理论到实践 大规模语言模型:从理论到实践
- Andrej Karpathy(openai、tesla)制作的课程:Neural Networks: Zero To Hero
- stanford cs324 course:Home | CS324
- github:https://github.com/mlabonne/llm-course
LF AI & Data Landscape
相关论文
- attension is all you need https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/2205.01068
- model merging, https://huggingface.co/collections/osanseviero/model-merging-65097893623330a3a51ead66
大模型训练对环境的影响
2023 year of LLMs
https://huggingface.co/blog/2023-in-llms
- model merging:合并多个model;

