
热门标签
热门文章
- 1“知识图谱+”系列:知识图谱+强化学习_图强化学习
- 2real-time-emotion-detection 排坑记录_emotiondetection_realtime
- 3我用 ChatGPT,造了一个「水母机器人」
- 4智慧旅游中数据可视化的革新作用
- 5vue项目打包成桌面安装软件_python vue django封装成桌面应用
- 6001-Windows下PyTorch极简开发环境配置
- 7阿里云快照是什么?_阿里云快照是什么意思
- 8Notion AI 进阶【help me write】_notion prompt
- 9python基础_petrel_client
- 10pythonmax函数数组_Python中用max()方法分享最大值的介绍
当前位置: article > 正文
如何用OpenAI的形式流式访问ChatGLM2-6B?30行代码简单解决!_azureopenai 可以使用chatglm
作者:Monodyee | 2024-04-01 10:42:47
赞
踩
azureopenai 可以使用chatglm
最近我正在开发基于LangChain的知识库。为了降低tokens的费用,需要完成接口替换。将原来调用OpenAI接口的方式改为使用ChatGLM2-6B接口。这样的改变不仅可以节省成本,还能提高文本输出速度。以下是我们在实践中取得的成果,现在与大家分享!
一、环境配置:
下载chatglm2-6B库:https://github.com/THUDM/ChatGLM2-6B.git
启动python openai_api.py
监听端口为8000。
二、代码编写:
1、首先要有一个“openai.api_key”,这里直接输入个test进行测试即可。
2、还要有一个域名,这里设置的是“http://localhost:8000/v1”

3、用chatglm2-6b查询输入的文字
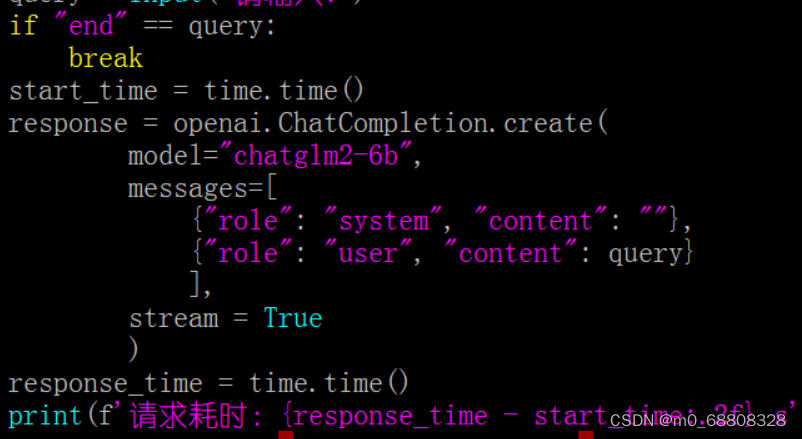
(4、输出总耗时)

总代码如下:
- import openai
- import time
- import json
-
- openai.api_key = 'test'
- openai.api_base = "http://localhost:8000/v1"
- start_time = time.time()
- while True:
- query = input("请输入:")
- if "end" == query:
- break
- start_time = time.time()
- response = openai.ChatCompletion.create(
- model="chatglm2-6b",
- messages=[
- {"role": "system", "content": ""},
- {"role": "user", "content": query}
- ],
- stream = True
- )
- response_time = time.time()
- print(f'请求耗时:{response_time - start_time:.2f} s')
- for i in response:
- t = time.time()
- if "content" in i.choices[0].delta:
- msg = i.choices[0].delta.content
- print(msg, end='', flush=True)
- print(f'\n总耗时: {t - start_time:.2f} s')
- print("===结束===")

三、运行此文件即可进行测试,效果如下:
请输入:讲一个笑话
请求耗时:0.00 s
下面是一个简短的笑话:
为什么小鸟站在电线上不会被电到呢?
因为它们不接地啊!
总耗时: 0.67 s
===结束===

以上就是我在配置并使用OpenAI的形式流式访问ChatGLM2-6B的简单方法,希望可以帮到大家。欢迎发私信与我共同讨论更多该领域的知识!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/348537
推荐阅读
相关标签

