
- 1List、Map、Set存取元素特点_list存取数据有什么特点
- 2AssetBundle打包基础和相关问题介绍_deterministicassetbundle
- 3销毁该对象的根父级_unity 删掉父节点
- 4谷歌play支付_Google Play的新功能
- 5【FA三维路径规划】萤火虫算法无人机避障三维航迹规划【含Matlab源码 3661期】_无人机规避障碍物的三维路基规划算法
- 6Android-自定义Dialog和其样式以及自定义控件思路详解_adapter dialog 设置style
- 7C#学习笔记3:Windows窗口计时器
- 8鸿蒙原生应用/元服务开发-Stage模型能力接口(四)_鸿蒙应用开发 接口
- 9一键导出PDF文档中的高亮文字以及笔记(Python实现)_python 生成pdf并高亮文字
- 10常见的AI安全风险(数据投毒、后门攻击、对抗样本攻击、模型窃取攻击等)
机器学习——分类树DecisionTreeClassifier
赞
踩
DecisionTreeClassifier——分类树
classsklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
1、DecisionTreeClassifier的参数:
1.1、criterion
要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个“最佳”的指标叫做**“不纯度”**。通常来说,不纯度越低,决策树对训练集的拟合越好。现在使用的决策树算法在分枝方法上的核心大多是围绕在对某个不纯度相关指标的最优化上。
不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
Criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:
1)输入”entropy“,使用信息熵(Entropy)
2)输入”gini“,使用基尼系数(Gini Impurity)
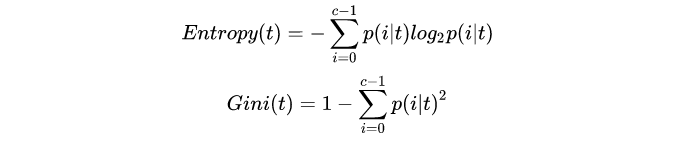
其中t代表给定的节点,i代表标签的任意分类。注意,当使用信息熵时,sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差。
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏感,所以信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵很容易过拟合,基尼系数在这种情况下效果往往比较好。当然,这不是绝对的。

到这里,决策树的基本流程其实可以简单概括如下:

直到没有更多的特征可用,或整体的不纯度指标已经最优,决策树就会停止生长。

