
热门标签
热门文章
- 1低版本Mac OS安装合适xcode的方法_mac 12.6.8支持xcode
- 2清理PostgreSQL磁盘空间 并重新生成空间_poster清理磁盘空间
- 3大专计算机考证基础_专科计算机基础考什么
- 4linux cp和mv命令选项_mv 保留权限
- 5【模板:排序不等式】AcWing913.《排队打水》(C++)
- 6置信区间、P值那点事_置信区间和p值的关系
- 7C#版开源免费的Bouncy Castle密码库_bouncy castle c#
- 8如何拉取 git 仓库中的最新代码?_git拉取最新的代码到本地
- 9Linux命令:wget(下载文件)、ssh(登录及免密登录)、scp(远程文件传输)、sh(脚本)_linux命令下载大文件
- 10JavaScript时间戳判断是否为当天_通过时间戳判断是不是当天
当前位置: article > 正文
【MySQL将字段值逗号分隔的数据分成多行,更新后,再合并为一行】_mysql 字段用,连接的数据分割成多条数据
作者:Monodyee | 2024-03-19 19:02:02
赞
踩
mysql 字段用,连接的数据分割成多条数据
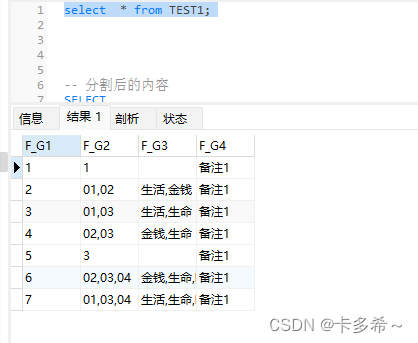
1、如图把TEST1的F_G2替换成TEST2的F_G2,同时更新F_G3

2、两个测试表的sql
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for TEST1
-- ----------------------------
DROP TABLE IF EXISTS `TEST1`;
CREATE TABLE `TEST1` (
`F_G1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,
`F_G2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
`F_G3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
`F_G4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
PRIMARY KEY (`F_G1`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of TEST1
-- ----------------------------
INSERT INTO `TEST1` VALUES ('1', '1', '', '备注1');
INSERT INTO `TEST1` VALUES ('2', '1,2', '', '备注1');
INSERT INTO `TEST1` VALUES ('3', '1,3', '', '备注1');
INSERT INTO `TEST1` VALUES ('4', '2,3', '', '备注1');
INSERT INTO `TEST1` VALUES ('5', '3', '', '备注1');
INSERT INTO `TEST1` VALUES ('6', '2,3,4', '', '备注1');
INSERT INTO `TEST1` VALUES ('7', '1,3,4', '', '备注1');
-- ----------------------------
-- Table structure for TEST2
-- ----------------------------
DROP TABLE IF EXISTS `TEST2`;
CREATE TABLE `TEST2` (
`F_G1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,
`F_G2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
`F_G3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
`F_G4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
PRIMARY KEY (`F_G1`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of TEST2
-- ----------------------------
INSERT INTO `TEST2` VALUES ('1', '01', '生活', '1');
INSERT INTO `TEST2` VALUES ('2', '02', '金钱', '2');
INSERT INTO `TEST2` VALUES ('3', '03', '生命', '3');
INSERT INTO `TEST2` VALUES ('4', '04', '时间', '4');
SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
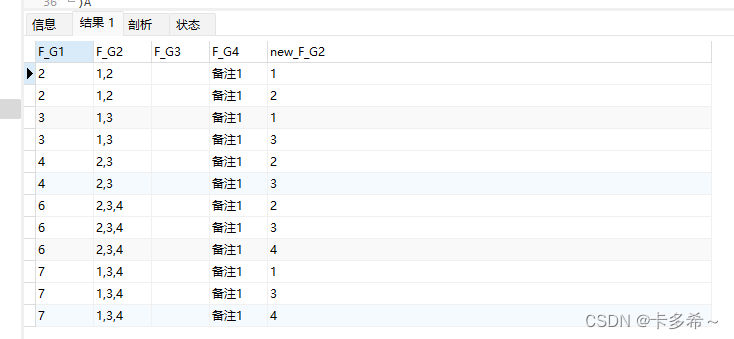
3、先将TEST1的F_G2进行分割,行转列
-- 分割后的内容
SELECT
a.F_G2,
-- /*先正着取出几部分*/,然后在此基础再倒着取出最后那一部分
substring_index( substring_index(a.F_G2,',',b.help_topic_id + 1),',' ,- 1 ) AS new_F_G2
from
-- 将原数据先取出来 like中的符号与实际表里字段中的分割符对应
(select F_G1,F_G2,F_G3,F_G4 from TEST1 where F_G2 like '%,%') a -- 如果表内还存在没有分隔符,就单个值的则直接select sname,sage from student 就行,总之目的是取出要处理的数据
join mysql.help_topic b ON -- mysql帮助表 内含字符等 ,help_topic_id是从0开始的,其实使用的是它的计数功能
b.help_topic_id < ( length(a.F_G2) - length(REPLACE (a.F_G2, ',', '')) + 1 ); -- 实际算出的是分割后总共有几部分(此处是将长度为1的英文状态替换成空)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
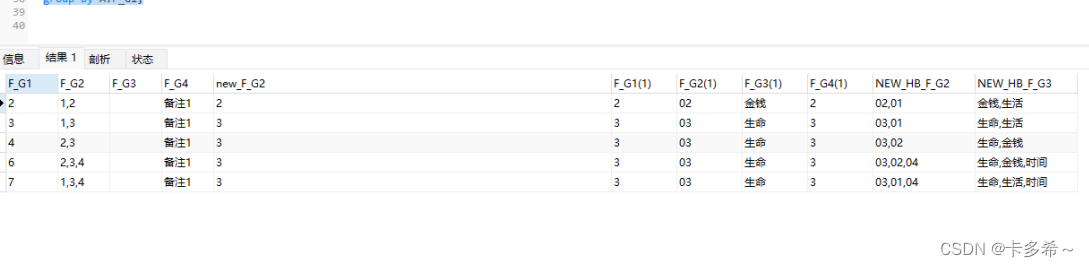
4、根据关联表,查询合并新值
-- 分割后关联Test2表,进行合并更新
select
A.*,
TEST2.*,
group_concat(TEST2.F_G2) NEW_HB_F_G2,
group_concat(TEST2.F_G3)NEW_HB_F_G3
from (
SELECT
a.F_G1,
a.F_G2,
a.F_G3,
a.F_G4,
substring_index( substring_index(a.F_G2,',',b.help_topic_id + 1),',' ,- 1 ) AS new_F_G2
from (select F_G1,F_G2,F_G3,F_G4 from TEST1 where F_G2 like '%,%') a
join mysql.help_topic b ON
b.help_topic_id < ( length(a.F_G2) - length(REPLACE (a.F_G2, ',', '')) + 1 )
)A
left join TEST2 on TEST2.F_G4 = A.new_F_G2
group by A.F_G1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5、把TEST1的F_G2和F_G3更新成新合并的数值
-- 把TEST1的F_G2和F_G3更新成新合并的数值
UPDATE (
select
A.F_G1,
group_concat(TEST2.F_G2) NEW_HB_F_G2,
group_concat(TEST2.F_G3)NEW_HB_F_G3
from (
SELECT
a.F_G1 F_G1,-- 可以关联的列
a.F_G2,-- 被拆分的列
substring_index( substring_index(a.F_G2,',',b.help_topic_id + 1),',' ,- 1 ) AS new_F_G2 -- 需要拿到的值
from (select F_G1,F_G2,F_G3,F_G4 from TEST1 where F_G2 like '%,%') a
join mysql.help_topic b ON
b.help_topic_id < ( length(a.F_G2) - length(REPLACE (a.F_G2, ',', '')) + 1 )
)A
left join TEST2 on TEST2.F_G4 = A.new_F_G2
group by A.F_G1
) B ,TEST1 C SET C.F_G2 = B.NEW_HB_F_G2,C.F_G3 = B.NEW_HB_F_G3 WHERE B.F_G1 = C.F_G1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/268414
推荐阅读

相关标签

