
- 1DDIM原理及代码(Denoising diffusion implicit models)
- 2来自硅谷企业级ChatGPT大模型开发入门实战直播试听课
- 3四川成龙师范大学计算机专业,四川师范大学成龙校区有哪些专业
- 4鸿蒙和安卓,到底有什么区别?
- 5MathType软件免费激活码秘钥7.6版本_mathtype7免费产品密钥
- 6烽火HG680-LY/HG680-LV/HG680-LC_S905L3(B)_安卓9_线刷固件包_烽火hg680lc精简固件
- 7前端学习笔记(四):js语法进阶笔记_js进阶语法
- 8快速体验DevEco Studio 3.0 Beta4应用服务开发_使用deveco studio模板快速开发应用
- 9Subscriber class xxx.xxx.xxx and its super classes have no public methods with the@Subscribe annotat_subscriber class com.topdon.tool.mainactivity and
- 10MFC中CDC、CClientDC、CWindowDC、CPaintDC、CMetaFileDC 的区别_cclientdc cdc
文本识别CRNN模型介绍以及pytorch代码实现
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
文本识别是图像领域的一个常见任务,场景文字识别OCR任务中,需要先检测出图像中文字位置,再对检测出的文字进行识别,文本介绍的CRNN模型可用于后者, 对检测出的文字进行识别。

An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
原论文地址:论文地址
一、CRNN模型介绍
1.模型结构
CRNN模型结合了CNN模型与RNN模型,CNN用于提取图像特征,RNN将CNN提取的特征进行处理得到输出,对应最终的标签。
CRNN包含三层,卷积层,循环层和转录层,由于每张图像中英文单词的长度不一致,但是经过CNN之后提取的特征长度是一定的,所以就需要一个转录层处理,得到最终结果。
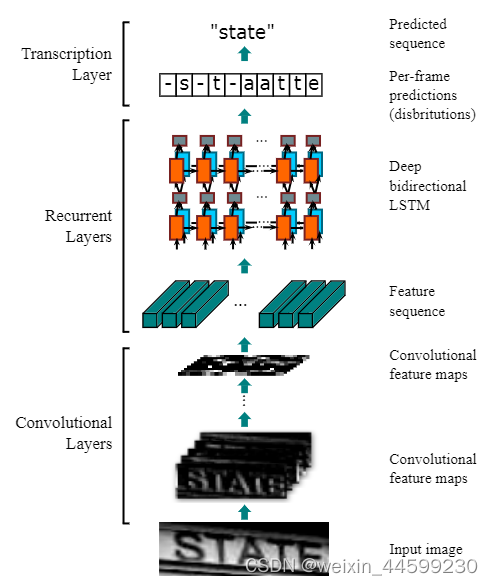
该图为模型的大体结构。
输入模型的是一张图像,其shape是(1,32,100) (channel,width,height),
经过一个卷积神经网络之后,其shape变成(512,1,24)(new_channel,new_height,new_width),把channel和height这两个维度合并,合并后shape(512,24),再将这两个维度交换位置,(24,512)(new_width,new_height*new_channel),由于后续需要将提取的特征输入循环神经网络,这个24就相当于是时间步了,24个时间步。输出特征图shape是(24,512)可以理解为,把原图分成24列,每一列用512维的特征向量表示。如下图所示
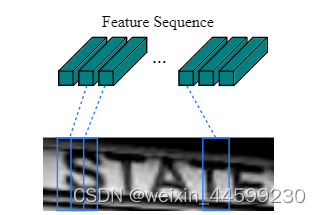
将24个特征向量输入进循环神经网络,论文中循环神经网络层是两个LSTM堆叠而成的,经过后就得到24个时间步的输出,再经过全连接层以及softmax层得到一个概率矩阵,形状为(T,num_class),T是时间步,num_class是要分类的类别数,是0-9数字以及a-z字母组合,还有一个blank标识符,总共37类。时间步输出是24个,但是图片中字符数不一定都是24,长短不一,经过转录层将其处理。
2.CTCLoss
如果使用传统的loss function,需要对齐训练样本,有24个时间步,就需要有24个对应的标签,在该任务中显然不合适,除非可以把图片中的每一个字符都单独检测出来,一个字符对应一个标签,则需要很强大的文字检测算法,CTCLoss不需要对齐样本。
还是24个时间步得到24个标签,再进行一个β变换,才得到最终标签。24个时间步可以看作原图中分成24列,每一列输出一个标签,有时一个字母占据好几列,例如字母S占据三列,则这三列输出类别都应该是S,有的列没有字母,则输出空白类别,可以这么理解。得到最终类别时将连续重复的字符去重(空白符两侧的相同字符不去重,因为真实标签中可能存在连续重复字符,例如green,中的两个连续的e不应该去重,则生成标签的时候就该是类似e-e这种,则不会去重),最终去除空白符即可得到最终标签。
β变换定义如下
β
:
L
′
T
→
L
<
=
T
\beta :L^{'T} →L^{<=T}
β:L′T→L<=T
T代表时间步,长度,由于对连续重复字符去重,则处理后的长度一定小于T
举几个β变换的例子,空白用-表示
β
(
−
−
s
s
t
a
a
a
t
−
e
e
)
=
s
t
a
t
e
\beta(--sstaaat-ee)=state
β(−−sstaaat−ee)=state
β
(
−
−
s
−
t
t
−
a
−
t
−
e
)
=
s
t
a
t
e
\beta(--s-tt-a-t-e)=state
β(−−s−tt−a−t−e)=state
β
(
−
s
−
s
t
−
a
a
t
−
e
)
=
s
s
t
a
t
e
\beta(-s-st-aat-e)=sstate
β(−s−st−aat−e)=sstate
β
(
−
s
−
t
t
a
−
t
t
−
e
e
)
=
s
t
a
t
e
\beta(-s-tta-tt-ee)=state
β(−s−tta−tt−ee)=state
可以看出若想要输出state,不止一条路径可以实现输出state.
经过LSTM后的结果需要送入转录层处理,设LSTM的输出标签序列为x,输出标签为l的概率为:
p
(
l
∣
x
)
=
∑
π
∈
β
−
(
l
)
p
(
π
∣
x
)
p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
p(l∣x)=π∈β−(l)∑p(π∣x)
π
∈
β
−
(
l
)
\pi \in \beta ^{-}(l)
π∈β−(l)表示经过β变换后为l的路径集合
π
\pi
π
对于每一条路径
π
\pi
π有
p
(
π
∣
x
)
=
∏
t
=
1
T
y
π
t
t
p(\pi |x)=\prod_{t=1}^{T}y_{\pi ^{t}}^{t }
p(π∣x)=t=1∏Tyπtt
y
π
t
t
y_{\pi ^{t}}^{t }
yπtt表示该路径第t个时间步取得该标签的一个概率,连乘起来就是取得该路径的概率。
CTCLoss的优化目标是使得
p
(
l
∣
x
)
=
∑
π
∈
β
−
(
l
)
p
(
π
∣
x
)
p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
p(l∣x)=∑π∈β−(l)p(π∣x)最大,所以
l
o
s
s
=
−
p
(
l
∣
x
)
=
∑
π
∈
β
−
(
l
)
p
(
π
∣
x
)
loss=-p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
loss=−p(l∣x)=∑π∈β−(l)p(π∣x),使得该loss最小化,来更新前面lstm以及cnn的参数,由于CTCLoss计算有些复杂,暂不讨论。Pytorch中提供了CTCLoss的计算接口,我们直接使用即可。
from torch.nn import CTCLoss
- 1
beam search
训练阶段使用CTCLoss更新参数,测试阶段如果使用暴力解法,算出每条路径的一个概率,最终取最大概率的一个路径,时间复杂度非常大,如果有37个类别,序列长度是24,那么路径总和是 3 7 24 37^{24} 3724,这只是一个样本的路径数 。所以就需要用到beam search来优化计算过程。
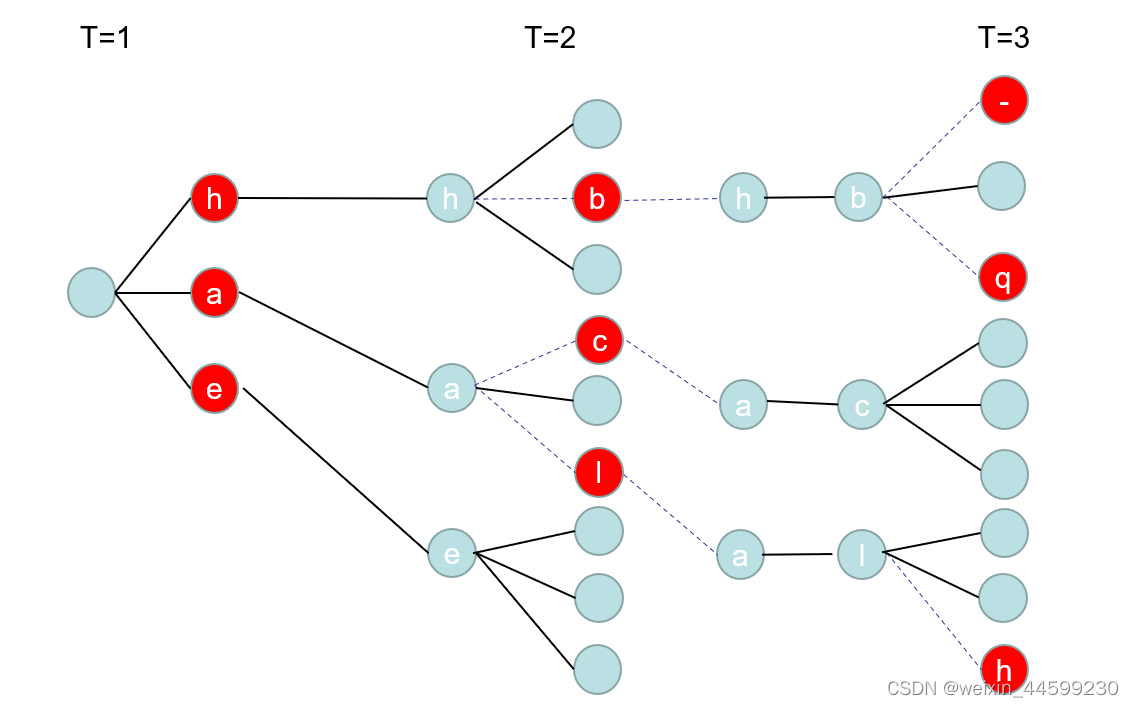
计算过程如图所示,现在第一个时间步中找到概率最大的三(可以自由设置)个标签,以这三个最大概率的标签为基础再往后搜索,在第二步会在第一步的概率基础上(需要以第一步的三个标签的概率乘以后面的标签概率)搜索出九个标签,在这九个标签中取三个最大的 ,继续往后搜索,以此类推,在经过最后一个时间步后会得到三条路径,取概率最大的那条,在经过CTC decode即可得到最终label。
二、使用pytorch实现crnn
数据集
将好几个数据集合并并做了相关处理,得到八千多张图片
只在这里展示关键部分代码
代码以及数据集在链接:https://pan.baidu.com/s/1j1sUFIgdB1qga1Cfrh-jlw
提取码:lf2m
dataset.py
import os import torch from torch.utils.data import Dataset from PIL import Image import numpy as np class Synth90kDataset(Dataset): CHARS = '0123456789abcdefghijklmnopqrstuvwxyz' CHAR2LABEL = {char: i + 1 for i, char in enumerate(CHARS)} LABEL2CHAR = {label: char for char, label in CHAR2LABEL.items()} def __init__(self, root_dir=None,image_dir = None, mode=None, file_names=None, img_height=32, img_width=100): if mode == "train": file_names, texts = self._load_from_raw_files(root_dir, mode) else: texts = None self.root_dir = root_dir self.image_dir = image_dir self.file_names = file_names self.texts = texts self.img_height = img_height self.img_width = img_width def _load_from_raw_files(self, root_dir, mode): paths_file = None if mode == 'train': paths_file = 'train.txt' elif mode == 'test': paths_file = 'test.txt' file_names = [] texts = [] with open(os.path.join(root_dir, paths_file), 'r') as fr: for line in fr.readlines(): file_name, ext = line.strip().split('.') text = file_name.split('_')[-1].lower() file_names.append(file_name + "." + ext) texts.append(text) return file_names, texts def __len__(self): return len(self.file_names) def __getitem__(self, index): file_name = self.file_names[index] file_path = os.path.join(self.image_dir,file_name) image = Image.open(file_path).convert('L') # grey-scale image = image.resize((self.img_width, self.img_height), resample=Image.BILINEAR) image = np.array(image) image = image.reshape((1, self.img_height, self.img_width)) image = (image / 127.5) - 1.0 image = torch.FloatTensor(image) if self.texts: text = self.texts[index] target = [self.CHAR2LABEL[c] for c in text] target_length = [len(target)] target = torch.LongTensor(target) target_length = torch.LongTensor(target_length) # 如果DataLoader不设置collate_fn,则此处返回值为迭代DataLoader时取到的值 return image, target, target_length else: return image def synth90k_collate_fn(batch): # zip(*batch)拆包 images, targets, target_lengths = zip(*batch) # stack就是向量堆叠的意思。一定是扩张一个维度,然后在扩张的维度上,把多个张量纳入仅一个张量。想象向上摞面包片,摞的操作即是stack,0轴即按块stack images = torch.stack(images, 0) # cat是指向量拼接的意思。一定不扩张维度,想象把两个长条向量cat成一个更长的向量。 targets = torch.cat(targets, 0) target_lengths = torch.cat(target_lengths, 0) # 此处返回的数据即使train_loader每次取到的数据,迭代train_loader,每次都会取到三个值,即此处返回值。 return images, targets, target_lengths if __name__ == '__main__': from torch.utils.data import DataLoader from config import train_config as config img_width = config['img_width'] img_height = config['img_height'] data_dir = config['data_dir'] train_batch_size = config['train_batch_size'] cpu_workers = config['cpu_workers'] train_dataset = Synth90kDataset(root_dir=data_dir, mode='train', img_height=img_height, img_width=img_width) train_loader = DataLoader( dataset=train_dataset, batch_size=train_batch_size, shuffle=True, num_workers=cpu_workers, collate_fn=synth90k_collate_fn)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
model.py
import torch.nn as nn class CRNN(nn.Module): def __init__(self, img_channel, img_height, img_width, num_class, map_to_seq_hidden=64, rnn_hidden=256, leaky_relu=False): super(CRNN, self).__init__() self.cnn, (output_channel, output_height, output_width) = \ self._cnn_backbone(img_channel, img_height, img_width, leaky_relu) self.map_to_seq = nn.Linear(output_channel * output_height, map_to_seq_hidden) self.rnn1 = nn.LSTM(map_to_seq_hidden, rnn_hidden, bidirectional=True) # 如果接双向lstm输出,则要 *2,固定用法 self.rnn2 = nn.LSTM(2 * rnn_hidden, rnn_hidden, bidirectional=True) self.dense = nn.Linear(2 * rnn_hidden, num_class) # CNN主干网络 def _cnn_backbone(self, img_channel, img_height, img_width, leaky_relu): assert img_height % 16 == 0 assert img_width % 4 == 0 # 超参设置 channels = [img_channel, 64, 128, 256, 256, 512, 512, 512] kernel_sizes = [3, 3, 3, 3, 3, 3, 2] strides = [1, 1, 1, 1, 1, 1, 1] paddings = [1, 1, 1, 1, 1, 1, 0] cnn = nn.Sequential() def conv_relu(i, batch_norm=False): # shape of input: (batch, input_channel, height, width) input_channel = channels[i] output_channel = channels[i+1] cnn.add_module( f'conv{i}', nn.Conv2d(input_channel, output_channel, kernel_sizes[i], strides[i], paddings[i]) ) if batch_norm: cnn.add_module(f'batchnorm{i}', nn.BatchNorm2d(output_channel)) relu = nn.LeakyReLU(0.2, inplace=True) if leaky_relu else nn.ReLU(inplace=True) cnn.add_module(f'relu{i}', relu) # size of image: (channel, height, width) = (img_channel, img_height, img_width) conv_relu(0) cnn.add_module('pooling0', nn.MaxPool2d(kernel_size=2, stride=2)) # (64, img_height // 2, img_width // 2) conv_relu(1) cnn.add_module('pooling1', nn.MaxPool2d(kernel_size=2, stride=2)) # (128, img_height // 4, img_width // 4) conv_relu(2) conv_relu(3) cnn.add_module( 'pooling2', nn.MaxPool2d(kernel_size=(2, 1)) ) # (256, img_height // 8, img_width // 4) conv_relu(4, batch_norm=True) conv_relu(5, batch_norm=True) cnn.add_module( 'pooling3', nn.MaxPool2d(kernel_size=(2, 1)) ) # (512, img_height // 16, img_width // 4) conv_relu(6) # (512, img_height // 16 - 1, img_width // 4 - 1) output_channel, output_height, output_width = \ channels[-1], img_height // 16 - 1, img_width // 4 - 1 return cnn, (output_channel, output_height, output_width) # CNN+LSTM前向计算 def forward(self, images): # shape of images: (batch, channel, height, width) conv = self.cnn(images) batch, channel, height, width = conv.size() conv = conv.view(batch, channel * height, width) conv = conv.permute(2, 0, 1) # (width, batch, feature) # 卷积接全连接。全连接输入形状为(width, batch, channel*height), # 输出形状为(width, batch, hidden_layer),分别对应时序长度,batch,特征数,符合LSTM输入要求 seq = self.map_to_seq(conv) recurrent, _ = self.rnn1(seq) recurrent, _ = self.rnn2(recurrent) output = self.dense(recurrent) return output # shape: (seq_len, batch, num_class)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
train.py
import os import cv2 import torch from torch.utils.data import DataLoader import torch.optim as optim from torch.nn import CTCLoss from dataset import Synth90kDataset, synth90k_collate_fn from model import CRNN from evaluate import evaluate from config import train_config as config def train_batch(crnn, data, optimizer, criterion, device): crnn.train() images, targets, target_lengths = [d.to(device) for d in data] logits = crnn(images) log_probs = torch.nn.functional.log_softmax(logits, dim=2) batch_size = images.size(0) input_lengths = torch.LongTensor([logits.size(0)] * batch_size) target_lengths = torch.flatten(target_lengths) loss = criterion(log_probs, targets, input_lengths, target_lengths) optimizer.zero_grad() loss.backward() optimizer.step() return loss.item() def main(): epochs = config['epochs'] train_batch_size = config['train_batch_size'] lr = config['lr'] show_interval = config['show_interval'] valid_interval = config['valid_interval'] save_interval = config['save_interval'] cpu_workers = config['cpu_workers'] reload_checkpoint = config['reload_checkpoint'] img_width = config['img_width'] img_height = config['img_height'] data_dir = config['data_dir'] device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') print(f'device: {device}') train_dataset = Synth90kDataset(root_dir=data_dir,image_dir='../data/images', mode='train', img_height=img_height, img_width=img_width) train_loader = DataLoader( dataset=train_dataset, batch_size=train_batch_size, shuffle=True, num_workers=cpu_workers, collate_fn=synth90k_collate_fn) num_class = len(Synth90kDataset.LABEL2CHAR) + 1 crnn = CRNN(1, img_height, img_width, num_class, map_to_seq_hidden=config['map_to_seq_hidden'], rnn_hidden=config['rnn_hidden'], leaky_relu=config['leaky_relu']) if reload_checkpoint: crnn.load_state_dict(torch.load(reload_checkpoint, map_location=device)) crnn.to(device) optimizer = optim.RMSprop(crnn.parameters(), lr=lr) criterion = CTCLoss(reduction='sum') criterion.to(device) assert save_interval % valid_interval == 0 or valid_interval % save_interval ==0 i = 1 for epoch in range(1, epochs + 1): print(f'epoch: {epoch}') tot_train_loss = 0. tot_train_count = 0 for train_data in train_loader: loss = train_batch(crnn, train_data, optimizer, criterion, device) train_size = train_data[0].size(0) tot_train_loss += loss tot_train_count += train_size if i % show_interval == 0: print('train_batch_loss[', i, ']: ', loss / train_size) if i % save_interval == 0: save_model_path = os.path.join(config["checkpoints_dir"],"crnn.pt") torch.save(crnn.state_dict(), save_model_path) print('save model at ', save_model_path) i += 1 print('train_loss: ', tot_train_loss / tot_train_count) if __name__ == '__main__': main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
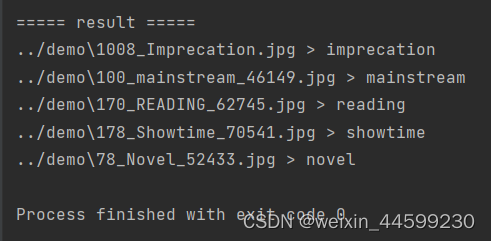
识别效果还算可以

测试效果

