
热门标签
热门文章
- 1【 香橙派 AIpro评测】烧系统运行部署LLMS大模型跑开源yolov5物体检测并体验Jupyter Lab AI 应用样例(新手入门)
- 2linux的重要知识点_linux中的重要知识点
- 3深度学习:05 卷积神经网络介绍(CNN)_tride 池化
- 4sequoiadb java使用_Java开发基础_Java驱动_开发_JSON实例_文档中心_SequoiaDB巨杉数据库...
- 5AI时代,人工智能是开发者的助手还是替代者?
- 6大模型之SORA技术学习_sora模型csdn
- 7风险评估:IIS的安全配置,IIS安全基线检查加固
- 8pytorch之torch基础学习_torch 学习
- 9heic图片转换_heic-convert
- 10SpringCloud实战【九】: SpringCloud服务间调用_springcloud服务与服务之间的调用
当前位置: article > 正文
FSMN,一种能替代RNN的新结构?
作者:Li_阴宅 | 2024-07-17 08:28:50
赞
踩
fsmn
FSMN
前言
FSMN全称:Feedforward Sequential Memory Networks,是国内知名的讯飞公司所提出,据笔者所知可能应用到了阿里的语音识别以及唤醒的,作为一种可以和RNN比较的网络,我觉得大家有必要的去学习以及了解一下
网络结构
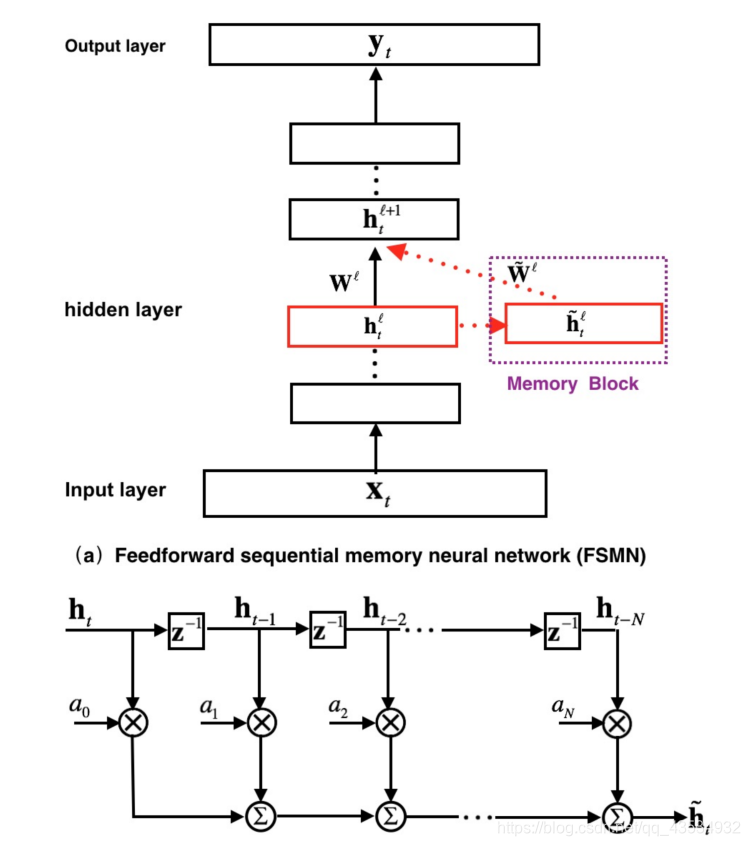
在论文中的结构如图所示,其实FSMN是改进了DNN的算法,也就是在DNN网络中相应的某一层中加入了Memory block,这种结构分解起来就像是数字信号处理中的FIR。
其中当a为常数是sFSMN,当a为向量时,为vFSMN。
当没有时延时,公式可定义为:
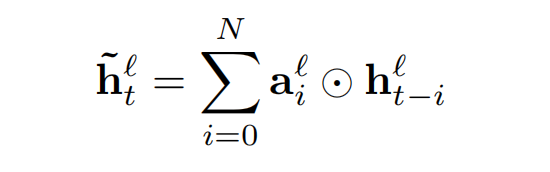
h为输入特征,a为权重系数。
引入时延后,网络可改写为:
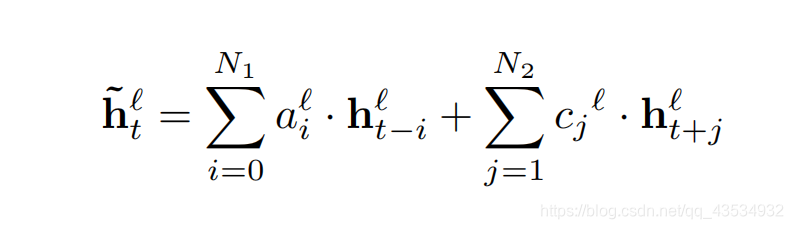
最后这一层的总的输出可以表示为:
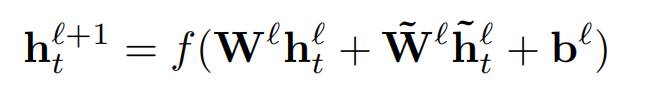
模块搭建
语音数据输入,参数,以及模块的调用
length=50#帧长
input=39#MFCC特征维数
x = tf.placeholder(tf.float32,[None,length,input])#输入数据
FSMN1=memory_block(x,10,15,50,50)
- 1
- 2
- 3
- 4
搭建menory_block模块:
def memory_block(x,front,delay,input_size, output_size): #############pad 0 x_pad_front=tf.pad(x,[[0,0],[front,0],[0,0]],"CONSTANT") x_pad_delay=tf.pad(x,[[0,0],[0,delay],[0,0]],"CONSTANT") h_memory=tf.random_normal([-1,1,39], 0) print(h_memory) print(x_pad_front) print(x_pad_delay) #############sum(a*h)+sum(c*h) for step in range(input_size): memory_block_front=x_pad_front[:,step:step+front,:] #print(memory_block_front) memory_block_delay=x_pad_front[:,step:step+delay,:] #print(memory_block_delay) FIR_1=tf.layers.conv1d(memory_block_front,39,1,strides=1, padding='same') FIR_1 = tf.reduce_sum(FIR_1, 1) FIR_2=tf.layers.conv1d(memory_block_delay,39,1,strides=1, padding='same') FIR_2 = tf.reduce_sum(FIR_2, 1) FIR = FIR_1+FIR_2 FIR = tf.reshape(FIR,[-1,1,39]) h_memory=tf.concat([h_memory,FIR],1) h_memory=h_memory[:,1:,:] print(h_memory) ############ all h_memory=tf.layers.conv1d(h_memory,output_size,1,strides=1, padding='same') x=tf.layers.conv1d(x,output_size,1,strides=1, padding='same') h_next=h_memory+x h_next=tf.layers.conv1d(h_next,output_size,1,strides=1, padding='same') print(h_next) return h_next

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
代码解析:
memory_block(x,front,delay,input_size, output_size)
- 1
参数x代表输入语音,front代表前向多少帧的输入,delay代表后向时延,input_size输入语音的帧长,output_size输出语音特征大小。
x_pad_front=tf.pad(x,[[0,0],[front,0],[0,0]],"CONSTANT") x_pad_delay=tf.pad(x,[[0,0],[0,delay],[0,0]],"CONSTANT") h_memory=tf.random_normal([-1,1,39], 0) print(h_memory) print(x_pad_front) print(x_pad_delay) #############sum(a*h)+sum(c*h) for step in range(input_size): memory_block_front=x_pad_front[:,step:step+front,:] #print(memory_block_front) memory_block_delay=x_pad_front[:,step:step+delay,:] #print(memory_block_delay) FIR_1=tf.layers.conv1d(memory_block_front,39,1,strides=1, padding='same') FIR_1 = tf.reduce_sum(FIR_1, 1) FIR_2=tf.layers.conv1d(memory_block_delay,39,1,strides=1, padding='same') FIR_2 = tf.reduce_sum(FIR_2, 1) FIR = FIR_1+FIR_2 FIR = tf.reshape(FIR,[-1,1,39]) h_memory=tf.concat([h_memory,FIR],1) h_memory=h_memory[:,1:,:] print(h_memory)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
x_pad_front和x_pad_delay分别代表前向补零和后向补零,对应第一个公式,sum(ah)+sum(ch)分别计算前向和后向
输出结果:
x_pad_front:Tensor("Pad_21:0", shape=(?, 60, 39), dtype=float32)
x_pad_delay:Tensor("Pad_22:0", shape=(?, 65, 39), dtype=float32)
前向得到的结果:Tensor("strided_slice_925:0", shape=(?, 10, 39), dtype=float32)
后向得到的结果:Tensor("strided_slice_926:0", shape=(?, 15, 39), dtype=float32)
h_memory=Tensor("strided_slice_1157:0", shape=(?, 50, 39), dtype=float32)
- 1
- 2
- 3
- 4
- 5
############ all
h_memory=tf.layers.conv1d(h_memory,output_size,1,strides=1, padding='same')
x=tf.layers.conv1d(x,output_size,1,strides=1, padding='same')
h_next=h_memory+x
h_next=tf.layers.conv1d(h_next,output_size,1,strides=1, padding='same')
print(h_next)
return h_next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果:
h_next:Tensor("conv1d_1107/BiasAdd:0", shape=(?, 50, 50), dtype=float32)
- 1
最后all代表了公式2的计算
完整代码
import tensorflow as tf length=50#帧长 input=39#MFCC特征维数 def memory_block(x,front,delay,input_size, output_size): #############pad 0 x_pad_front=tf.pad(x,[[0,0],[front,0],[0,0]],"CONSTANT") x_pad_delay=tf.pad(x,[[0,0],[0,delay],[0,0]],"CONSTANT") h_memory=tf.random_normal([-1,1,39], 0) print(h_memory) print(x_pad_front) print(x_pad_delay) #############sum(a*h)+sum(c*h) for step in range(input_size): memory_block_front=x_pad_front[:,step:step+front,:] #print(memory_block_front) memory_block_delay=x_pad_front[:,step:step+delay,:] #print(memory_block_delay) FIR_1=tf.layers.conv1d(memory_block_front,39,1,strides=1, padding='same') FIR_1 = tf.reduce_sum(FIR_1, 1) FIR_2=tf.layers.conv1d(memory_block_delay,39,1,strides=1, padding='same') FIR_2 = tf.reduce_sum(FIR_2, 1) FIR = FIR_1+FIR_2 FIR = tf.reshape(FIR,[-1,1,39]) h_memory=tf.concat([h_memory,FIR],1) h_memory=h_memory[:,1:,:] print(h_memory) ############ all h_memory=tf.layers.conv1d(h_memory,output_size,1,strides=1, padding='same') x=tf.layers.conv1d(x,output_size,1,strides=1, padding='same') h_next=h_memory+x h_next=tf.layers.conv1d(h_next,output_size,1,strides=1, padding='same') print(h_next) return h_next x = tf.placeholder(tf.float32,[None,length,input])#输入数据 FSMN1=memory_block(x,10,15,50,50)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Li_阴宅/article/detail/838993
推荐阅读
相关标签

