
- 1whoosh全文检索_whoosh全文检索阈值范围
- 2CSS设置滚动样式, 鼠标离开时滚动条隐藏_css 获取焦点显示滚动条,失去焦点隐藏滚动条
- 3阿秀朋友先后折戟腾讯、字节、快手、网易、滴滴、深信服后,终于成功上岸了...
- 4【PyCharm安装和配置(超详细版本教程),可分享!!!】
- 53D-STMN论文阅读_tgnn
- 6mysql 查看表结构数据 语句_查看表结构的sql语句
- 7python数据分析实战12_python数据分析实战---用户行为分析
- 8机器学习——降维算法PCA和SVD(sklearn)
- 9VirtualBox中的Mac系统的使用心得_mac的virtualbox怎么设置
- 10Windows11系统Windows.UI.FileExplorer.dll文件丢失问题
scikit-multilearn 笔记 第五节 如何选择分类器
赞
踩
英文原文: 点我.
声明:此博文为对原英文文章的翻译加个人的理解,一方面为自己学习所用,另一方面为需要中文scikit-multilearn文档的小伙伴提供便利。
侵删
如何选择分类器
这篇文章将会指导你经历为你的问题选择分类器的过程。
请注意,并没有已经建立的,科学地证实的设立的规则,来规定解决一个普遍的多标记分类问题如何选择一个分类器。成功的方法通常来自混合的直觉,关于哪些分类器值得考虑,分解为子问题以及实验模型选择。
在选择分类器之前,你需要考虑两件事情:
- 性能,即泛化质量,模型对特征和标记之间的关系了解的好与不好。对于不同的使用情况,你需要使用不同的策略来测量其质量,之后将讨论它。
- 效率,即,分类器执行的有多快,是否可扩展,是否基于定量的标记,样本和标记联系在你的问题中可以用。
有两个方法来做选择
- 基于渐近性能的直觉和经验研究的结果
- 使用交叉验证参数搜索的数据驱动模型选择
让我们加载一个数据集看首先需要做什么
from skmultilearn.dataset import load_dataset
X_train, Y_train, feature_names, label_names = load_dataset('emotions', 'train')
X_test, Y_test, _, _ = load_dataset('emotions', 'test')
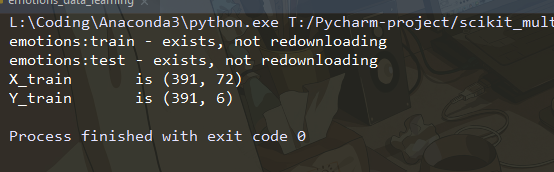
print('X_train is {}'.format(X_train.shape))
print('Y_train is {}'.format(Y_train.shape))
- 1
- 2
- 3
- 4
- 5
运行程序,输出结果如下:
通常分类器的性能取决于三个要素:
- 样本数量
- 标记数量
- 唯一标记类的数量
- 特征数量
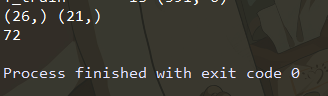
上述代码输出了emotions数据集训练集的矩阵大小。我们可以使用numpy和输出矩阵中具有非零值的行列表来获取唯一标记组合的数量。
import numpy as np
print(np.unique(Y_train.rows).shape, np.unique(Y_test.rows).shape)
print(X_train.shape[1])
- 1
- 2
- 3
5.1 直觉
5.1.1 泛化质量措施
下面有一些方法来测量一个分类器的泛化质量:
- Hamming loss,衡量分类器预测每个标记的程度,样本的平均值以及标记的平均值;
- accuracy score 测量分类器预测标记的联系,样本的平均值;
- jaccard similarity 测量样本的预测标记与正确分配的比例,样本的平均值;
- precision 测量在被判为正样本中,实际为正样本的比例;
- recall 测量在实际为正样本中,被判断为正样本的比例;
- F1 score 测量precision和recall的带全平均值,precision和recall对F1 score有同样的影响;
这些措施可以在sklearn中方便使用:
from skmultilearn.adapt import MLkNN
classifier = MLkNN(k=3)
prediction = classifier.fit(X_train, y_train).predict(X_test)
- 1
- 2
- 3
import sklearn.metrics as metrics
metrics.hamming_loss(y_test, prediction)
- 1
- 2
5.1.2 性能
Scikit-multilearn提供了11种分类器,通过标记分区和集合分类允许用在很多场景,下面看看影响性能的重要因素。 g ( x ) g(x) g(x)在一些分类器中表设计基本分类器的性能。
- BRkNNaClassifier, BRkNNbClassifier
-
- 参数估计:1 个参数
-
- 复杂度:O(n_{labels} * n_{samples} * n_{features} * k),BRkNN分类器为每个标记训练k个最近邻,并在两个变体之一中使用推断标记分配。
-
- 优点:在估计但标记分类器时将标记关系考虑在内,当样本之间的距离是标记分配的良好预测器时起作用,通常用在生物科学。
-
- 弱点:需要为每个标记训练一个分类器,不适合大规模标记,需要参数估计。
- MLKNN
-
- 参数估计:两个参数。
-
- 复杂度:O((n_{samples} * n_{features} + n_{labels}) * k)
MLKNN使用k近邻为测试类找到最近的样本,使用贝叶斯推断选择指定标记。
- 复杂度:O((n_{samples} * n_{features} + n_{labels}) * k)
-
- 优点:估计多类子分类器,当样本之间的距离是标记分配的良好预测器时起作用,通常用在生物科学。
-
- 弱点:需要参数估计
- MLARAM
-
- 参数估计:2个参数。
-
- 复杂度:O(n_{samples})。
一个ART分类器提高性能,它使用已学习原型的聚类到大型聚类中。
- 复杂度:O(n_{samples})。
-
- 优点:线性样本数量,可扩展性好
-
- 弱点:需要参数估计,ART在过去有泛化限制。
- BinaryRelevance
-
- 参数估计:仅适用于基本分类器。
-
- 复杂度:O(n_{labels} * base_single_class_classifier_complexity)
将L个标记的多标记分类问题转化为L个单标记二分类问题。
- 复杂度:O(n_{labels} * base_single_class_classifier_complexity)
-
- 优点: 估计单一标记分类器,可超出可用标记联系泛化。
-
- 弱点:不适合大数量标记,忽略了标记之间的关系。
- ClassifierChain
-
- 参数估计:基本分类器的1个参数。
-
- 复杂度:O(n_{labels} * base_single_class_classifier_complexity)
将多标记问题转化为多类问题,每个标记是一个类。
- 复杂度:O(n_{labels} * base_single_class_classifier_complexity)
-
- 优点: 估计单一标记分类器,可超出可用标记联系泛化,考虑标记相关性。
-
- 弱点:不适合大数量标记,很大程度依赖标记在链中的顺序。
- LabelPowerset
-
- 参数估计:基本分类器。
-
- 复杂度:O(base_multi_class_classifier_complexity(n_classes = n_label_combinations))
将多标记问题转化为多类问题,每个标记是一个类,并且使用多类分类器解决问题。
- 复杂度:O(base_multi_class_classifier_complexity(n_classes = n_label_combinations))
-
- 优点: 仅用一个分类器估计标记依赖,如果训练数据包含所有相关标记组合,则通常是子集准确性的最佳解。
-
- 弱点:要求分类器可预测的所有标记组合都存在于训练数据中 - 非常容易使用大标记空间。
- RakelD
-
- 参数估计:1+ 基本分类器参数。
-
- 复杂度:O(n_{partitions} * base_multi_class_classifier_complexity(n_classes = n_label_combinations_per_partition))
随机分区标记空间,并使用基本多类分类器为每个分区训练Label Powerset分类器。
- 复杂度:O(n_{partitions} * base_multi_class_classifier_complexity(n_classes = n_label_combinations_per_partition))
-
- 优点:可以使用比二元相关性更少的分类器,并且仍然可以泛化标记关系,而不像LabelPowerset那样过拟合。
-
- 弱点:使用随机方法不太可能绘制出最佳的标记空间划分。
- RakelO
-
- 参数估计:2+ 基本分类器参数。
-
- 复杂度:O(n_{partitions} * base_multi_class_classifier_complexity(n_classes = n_label_combinations_per_cluster))
随机绘制标记子空间(可能重叠)并使用基本多类分类器为每个分区训练Label Powerset分类器,根据投票分配标记。
- 复杂度:O(n_{partitions} * base_multi_class_classifier_complexity(n_classes = n_label_combinations_per_cluster))
-
- 优点:可以通过重叠模型提供更好的结果。
-
- 弱点:需要大量分类器来生成改进,不可扩展,随机子空间可能不是最优的。
- LabelSpacePartitioningClassifier
-
- 参数估计:基本分类器参数。
-
- 复杂度:O(n_{partitions} * base_classifier_complexity(n_classes = n_label_combinations_per_partition))
随机分区标记空间,并使用基本多类分类器训练每个分区的基本分类器。
- 复杂度:O(n_{partitions} * base_classifier_complexity(n_classes = n_label_combinations_per_partition))
-
- 优点:适用于不同类型的问题,推断何时划分为子问题,并决定何时使用比二元相关性更少的分类器,可扩展到具有大量标记的数据集,很好地泛化标记关系,而不像LabelPowerset那样过拟合,不需要参数估计。
-
- 弱点:要求训练数据中存在的标记关系可以表示问题,分区可能会阻止某些标记组合被正确分类,这取决于基本分类器。
- MajorityVotingClassifier
-
- 参数估计:基本分类器参数。
-
- 复杂度:O(n_{clusters} * base_classifier_complexity(n_classes = n_label_combinations_per_cluster))
使用聚类方法将标记空间划分为子空间(可能重叠),并使用基本多类分类器为每个分区训练基本分类器,根据投票分配标记。。
- 复杂度:O(n_{clusters} * base_classifier_complexity(n_classes = n_label_combinations_per_cluster))
-
- 优点:适用于不同类型的问题,推断何时划分为子问题,并决定何时使用比二元相关性更少的分类器,可扩展到具有大量标记的数据集,很好地泛化标记关系,而不像LabelPowerset那样过拟合,不需要参数估计。
-
- 弱点:要求训练数据中存在的标记关系可以表示问题。
5.2 数据驱动模型选择
Scikit-multilearn允许使用scikit-learn的模型选择GridSearchCV API来估计参数,以选择用于多标记分类的最佳模型。 在最简单的版本中,它可以查找scikit-multilearn分类器的最佳参数,我们将在估算MLkNN参数的示例情况下显示,在更复杂的问题转换方法的情况下,它可以估计方法的超级参数和基类分类器参数。
5.2.1 为MLkNN估计超参
在估计多标记分类器的超参数的情况下,我们首先导入相关的分类器和scikit-learn的GridSearchCV类。 然后我们定义要评估的参数值。 我们感兴趣的是k(-邻居的数量)和s (平滑参数)的组合效果最好。 我们还需要选择一个我们想要优化的度量 - 我们选择了F1宏观分数。
选择参数后,我们初始化并运行交叉验证网格搜索并打印最佳超参数。
from skmultilearn.dataset import load_dataset
from skmultilearn.adapt import MLkNN
from sklearn.model_selection import GridSearchCV
X_train, Y_train, feature_names, label_names = load_dataset('emotions', 'train')
X_test, Y_test, _, _ = load_dataset('emotions', 'test')
print('X_train is {}'.format(X_train.shape))
print('Y_train is {}'.format(Y_train.shape))
parameters = {'k':range(1,3), 's':[0.5, 0.7, 1.0]}
clf = GridSearchCV(MLkNN(), parameters, scoring='f1_macro')
clf.fit(X_train,Y_train)
print(clf.best_params_, clf.best_score_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行代码结果如下:

得到的值就可以直接用于分类器。
5.2.2 估计嵌入式分类器的超参数k
在问题转换分类器中,我们不仅需要估计超参数,还需要估计基本分类器的参数,甚至可能是问题转换方法。 让我们看一下使用标记空间分区的问题转换分类器集合的三层结构,参数包括:
classifier:它接受一个参数 - 一个用于将多标记分类问题转换为单标记分类的分类器,我们将在Label Powerset和Classifier Chains之间做出决定
classifier__classifier:这是转换策略的基本分类器,我们将在这里使用随机林
classifier__classifier__n_estimators:要在林中使用的树的数量,将传递给随机林对象
clusterer:标签空间分区类,我们将决定NetworkX库提供的两种方法。
from skmultilearn.problem_transform import ClassifierChain, LabelPowerset from sklearn.model_selection import GridSearchCV from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from skmultilearn.cluster import NetworkXLabelGraphClusterer from skmultilearn.cluster import LabelCooccurrenceGraphBuilder from skmultilearn.ensemble import LabelSpacePartitioningClassifier from sklearn.svm import SVC parameters = { 'classifier': [LabelPowerset(), ClassifierChain()], 'classifier__classifier': [RandomForestClassifier()], 'classifier__classifier__n_estimators': [10, 20, 50], 'clusterer' : [ NetworkXLabelGraphClusterer(LabelCooccurrenceGraphBuilder(weighted=True, include_self_edges=False), 'louvain'), NetworkXLabelGraphClusterer(LabelCooccurrenceGraphBuilder(weighted=True, include_self_edges=False), 'lpa') ] } clf = GridSearchCV(LabelSpacePartitioningClassifier(), parameters, scoring = 'f1_macro') clf.fit(X_train, Y_train) print (clf.best_params_, clf.best_score_)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
我运行之后显示如下:

得到这个结果我是迷茫的,经过百度之后,发现需要修改以上代码。、
from skmultilearn.problem_transform import ClassifierChain, LabelPowerset from sklearn.model_selection import GridSearchCV from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier # 修改的地方在这里 from skmultilearn.cluster.networkx import NetworkXLabelGraphClusterer # 修改的地方在这里 from skmultilearn.cluster import LabelCooccurrenceGraphBuilder from skmultilearn.ensemble import LabelSpacePartitioningClassifier from sklearn.svm import SVC parameters = { 'classifier': [LabelPowerset(), ClassifierChain()], 'classifier__classifier': [RandomForestClassifier()], 'classifier__classifier__n_estimators': [10, 20, 50], 'clusterer' : [ NetworkXLabelGraphClusterer(LabelCooccurrenceGraphBuilder(weighted=True, include_self_edges=False), 'louvain'), NetworkXLabelGraphClusterer(LabelCooccurrenceGraphBuilder(weighted=True, include_self_edges=False), 'lpa') ] } clf = GridSearchCV(LabelSpacePartitioningClassifier(), parameters, scoring = 'f1_macro') clf.fit(X_train, Y_train) print (clf.best_params_, clf.best_score_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
然鹅,还是报错ModuleNotFoundError: No module named ‘community’,这时,又经过百度,发现需要安装python-louvain
pip install python-louvain
- 1
安装之后,再运行,成功了。

个人能力有限,望各位批评指正。

