
- 1全自动ai生成视频MoneyPrinterTurbo源码 在线ai生成视频源码
- 2免费小说阅读器(Android版本)全站开源_开源小说阅读器
- 3基于Java的甜品商城系统【附源码】_蛋糕商城源码
- 4spring框架_spring是一个轻量级的javaee
- 5配置微信小程序自动更新_小程序自动更新版本
- 6使用U盘在VMware虚拟机安装Windows和Ubuntu(Linux)系统,非常详细!_u盘配置vmware虚拟机ubuntu
- 7【大数据】一些基本概念_读取型schema
- 8Spring事务与数据库事务之间的关系_spring事务和数据库事务的关系
- 9MongoDB教程:创建用户并添加角色_mongodb 角色
- 10未来已来!AI数字人客服引领服务行业革新潮流_越来越多商圈 数字人客服
基于Hadoop实现的基于协同过滤的就业推荐系统,Hadoop技术在协同过滤就业推荐系统中的应用及推荐原理解析_推荐系统中的应用:介绍推荐系统的基本原理,并讨论如何使用hadoop处理大规模的用户
赞
踩
基于hadoop的协同过滤就业推荐系统
推荐原理:以用户对岗位的评分和用户的收藏行为作为基础数据集,应用hadoop通过mapreduce程序进行协同过滤计算,得出用户对岗位的预测评分,根据评分高低对岗位进行评分排序,进而进而推荐
ID:93480671683045254
苹果大大个
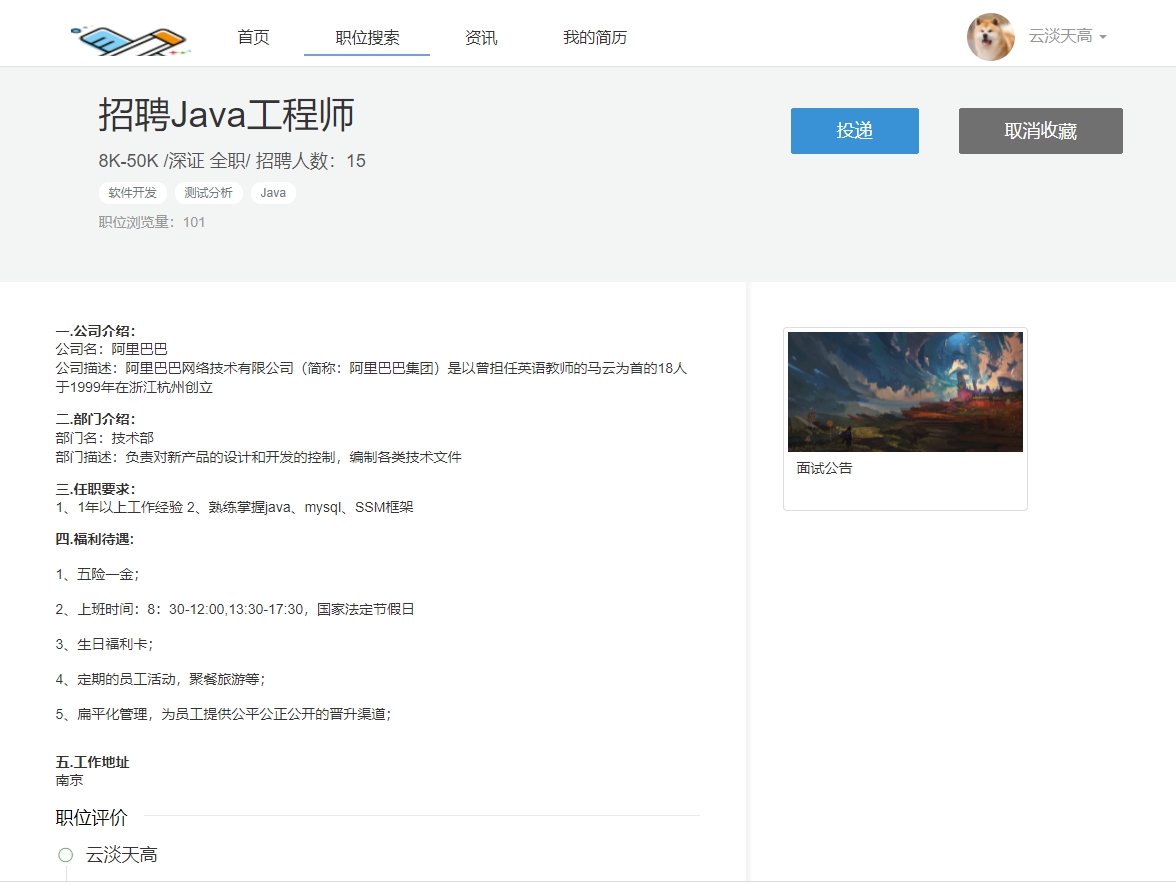

基于Hadoop的协同过滤就业推荐系统
推荐系统作为人工智能领域中的一个重要研究方向,旨在根据用户的兴趣和行为,向其推荐符合其偏好的信息或商品。基于Hadoop的协同过滤就业推荐系统,是一种应用Hadoop大数据处理框架和协同过滤算法的就业推荐系统。本文将从推荐原理、数据处理、协同过滤计算、排序策略等方面介绍该系统的设计与实现。
推荐原理是协同过滤算法的核心。在该系统中,我们以用户对岗位的评分和用户的收藏行为作为基础数据集。利用Hadoop的MapReduce程序,我们首先将用户的评分和收藏行为进行清洗和预处理,得到一份高质量的数据集。然后,我们通过协同过滤算法计算用户对岗位的预测评分。协同过滤算法根据用户之间的相似性来推断用户对某个岗位的评分,从而进行推荐。
在数据处理阶段,我们需要将原始数据进行清洗和转换,以满足后续的计算需求。通过Hadoop的分布式数据处理能力,我们可以高效地处理大规模的用户评分和收藏数据。清洗和转换的过程中,我们需要解决数据缺失、噪声数据和数据冗余等问题,以提高数据质量和计算效果。
在协同过滤计算阶段,我们将利用Hadoop的MapReduce程序进行计算。首先,我们将用户对岗位的评分和用户的收藏行为进行处理,构建用户-岗位评分矩阵和用户-岗位收藏矩阵。然后,通过MapReduce程序计算用户之间的相似性,并预测用户对未评分岗位的评分。相似性计算可以基于余弦相似度、皮尔逊相关系数等方法来实现。通过并行计算,我们可以加快计算速度,并处理大规模的数据。
排序策略是对推荐结果进行排序和展示的重要环节。在本系统中,我们根据用户对岗位的预测评分对岗位进行排序。评分高的岗位将被推荐给用户,以满足用户的兴趣和需求。通过排序策略,我们可以将推荐结果呈现给用户,并提高推荐准确度和用户体验。
本系统基于Hadoop的协同过滤算法,能够高效地处理大规模的用户评分和收藏数据,并利用用户之间的相似性进行推荐。通过MapReduce程序的并行计算和排序策略的优化,该系统能够提供准确、个性化的就业推荐结果,满足用户的就业需求。
综上所述,基于Hadoop的协同过滤就业推荐系统是一种应用Hadoop大数据处理框架和协同过滤算法的就业推荐系统。该系统通过清洗和预处理数据,利用协同过滤算法计算用户对岗位的预测评分,并通过排序策略对推荐结果进行排序和展示。该系统能够高效地处理大规模的用户数据并提供个性化的就业推荐服务。在实际应用中,该系统有着广阔的发展前景和应用场景。
注:本文所述基于Hadoop的协同过滤就业推荐系统为虚构产品,仅作为例子展示技术应用和系统设计原理。实际中,需根据具体需求和技术条件进行系统设计与实现。
相关的代码,程序地址如下:http://wekup.cn/671683045254.html

