- 1JAVA基础-String对象类的常用方法和应用_练习-java字符串之string类常用方法之
- 2【权威出版/投稿优惠】2024年水利水电与能源环境科学国际会议(WRHEES 2024)
- 35-Kafka中的分区副本机制_kafka 分区 副本
- 4低代码开发的优势与劣势,看这一篇就够了_低代码应用的 利弊
- 5CSDN2024年我的创作纪念日1024天|不忘初心|努力上进|积极向前_csdn创作纪念日
- 6【转载/中文翻译】如何在Mac上创建.txt文件_mac创建txt
- 7互联网四大「天坑」:社交、短视频、搜索、教育谁更难?
- 8数据结构 - 红黑树_红黑树路径
- 9我承认,我低估国产大模型了!_qwen 110b和qwen2 72b 谁更好
- 10SpringCloud项目日志接入ELK实战_如何将log.info日志推送到elk
排序篇:直接插入、希尔、直接选择和堆排序(C语言)_直接插入怎么对希尔插入进行改进 简单选择怎么对堆排序进行改进 直接排序怎么对冒
赞
踩
目录
前言:
排序的重要性:
1.数据存储和检索:对于大规模数据的存储和检索,排序可以提高检索速度。例如,当我们需要在数据库中搜索某个区间内的数据时,如果该区间已被排过序,我们可以使用二分查找算法来快速搜索,而不是一个一个元素地遍历。
2.数据分析:排序也是许多统计分析算法、机器学习算法和数据处理算法的基础。例如,在统计分析中,我们需要对大量数据进行排序后才能找到中位数或计算分位数。
3.算法优化:排序算法优化一直是计算机科学领域的研究热点,一个高效的排序算法可以缩短程序运行的时间,提升计算机系统的性能。
4.实用性:排序算法在许多现实生活中有着广泛的应用,如图书馆对书籍的分类、邮件系统对邮件的分类、商场对商品的重排等。
本文的排序都是升序,降序反过来就行
一:插入排序
(1)直接插入排序
基础思路(有个印象就行,主要看单趟)
1.将待排序的序列分为已排序区间和未排序区间,一开始已排序区间只包含第一个元素,即该序列的第一个元素。
2.对未排序的元素,用顺序依次与已排序区间的元素进行比较,找到其在已排序区间中的插入位置,并将该元素插入到已排序区间中对应的位置。
3.重复步骤 2 直到所有元素都遍历完为止。
单趟排序
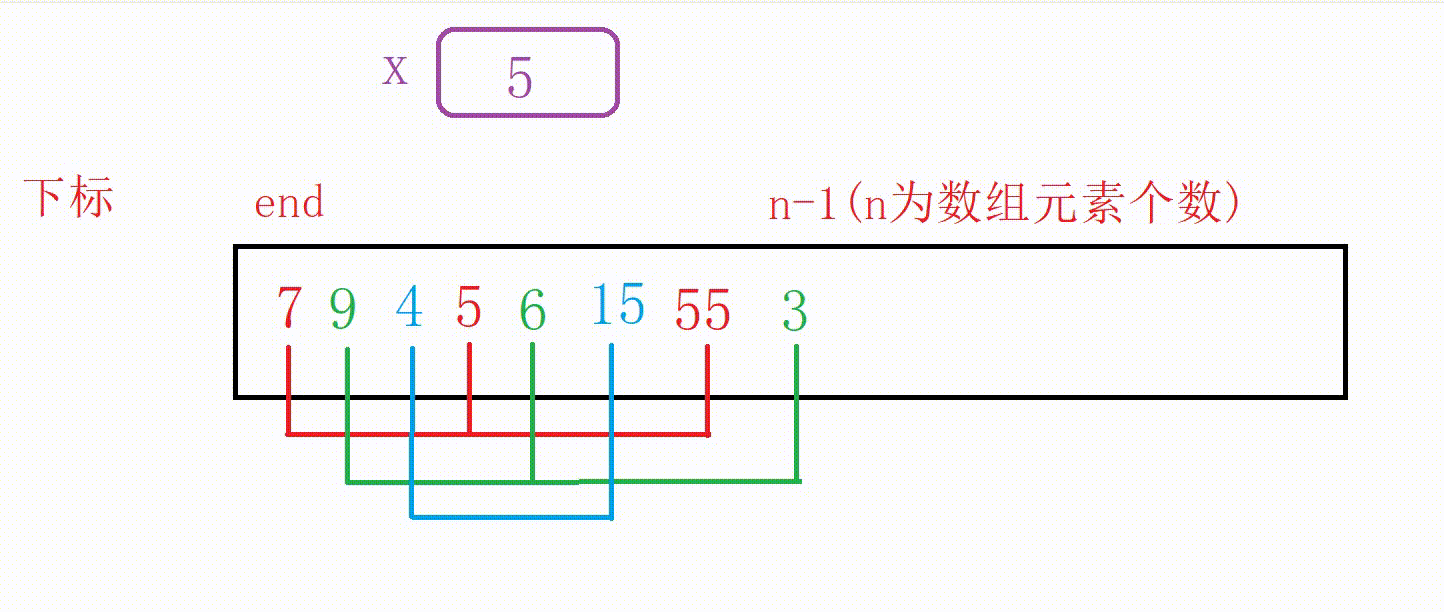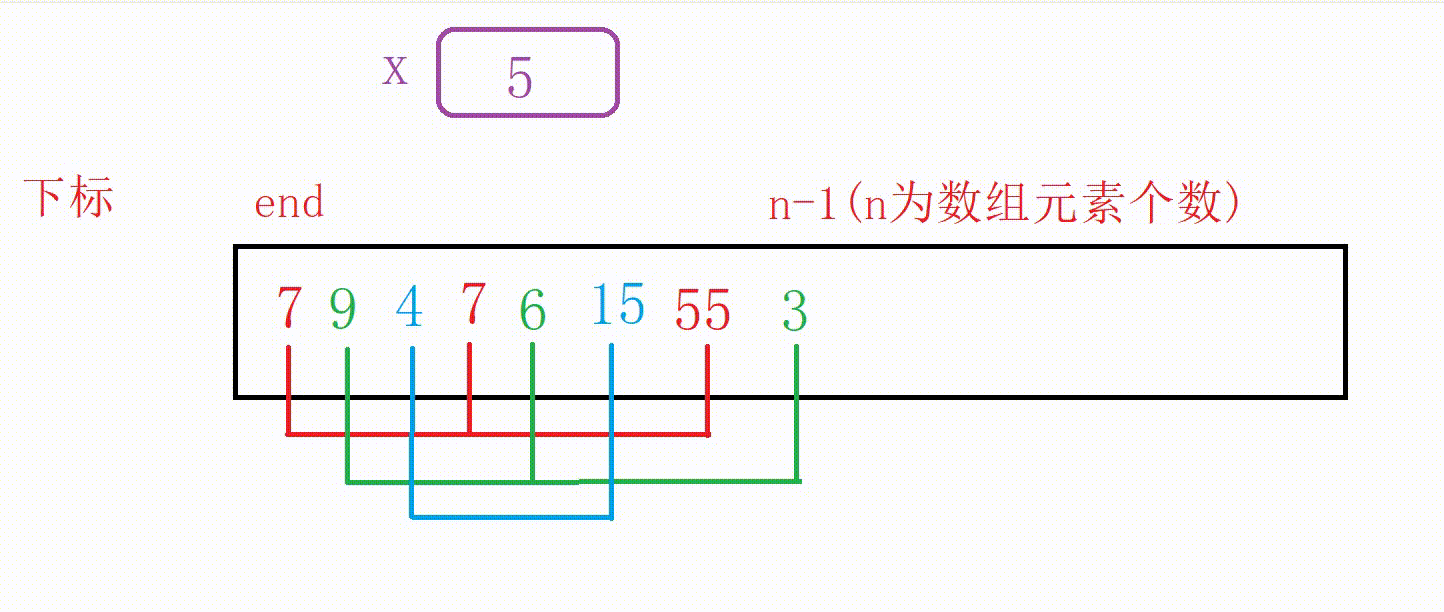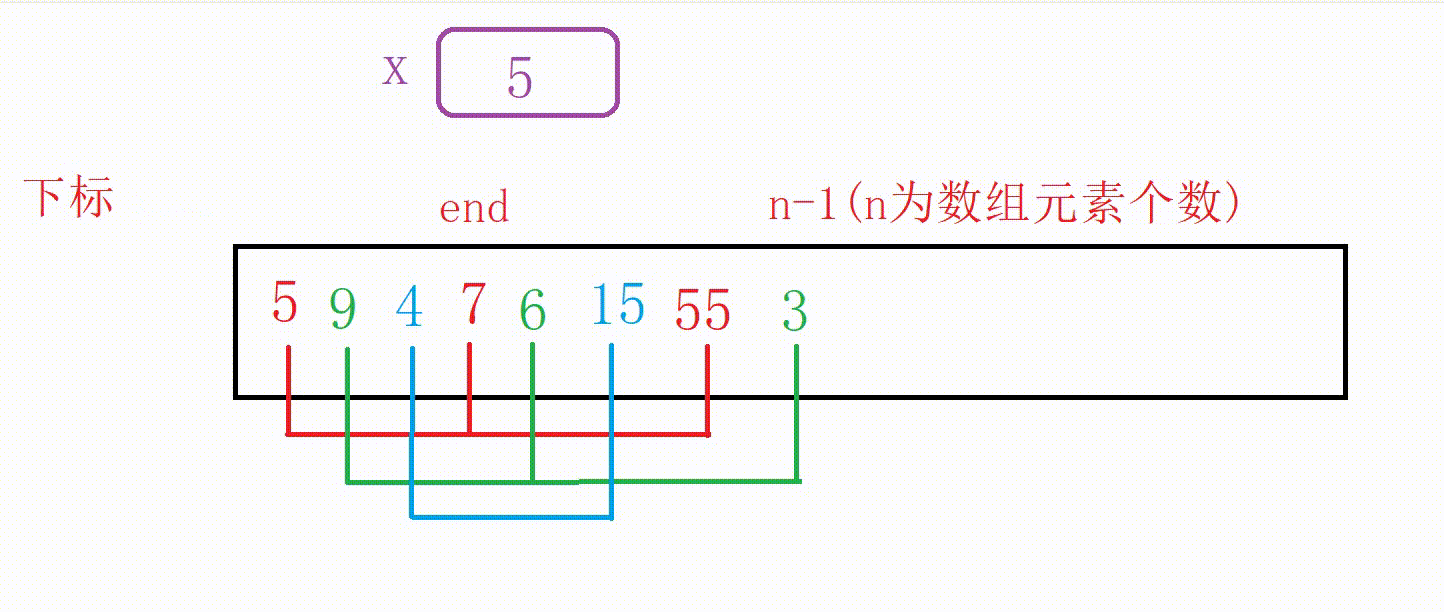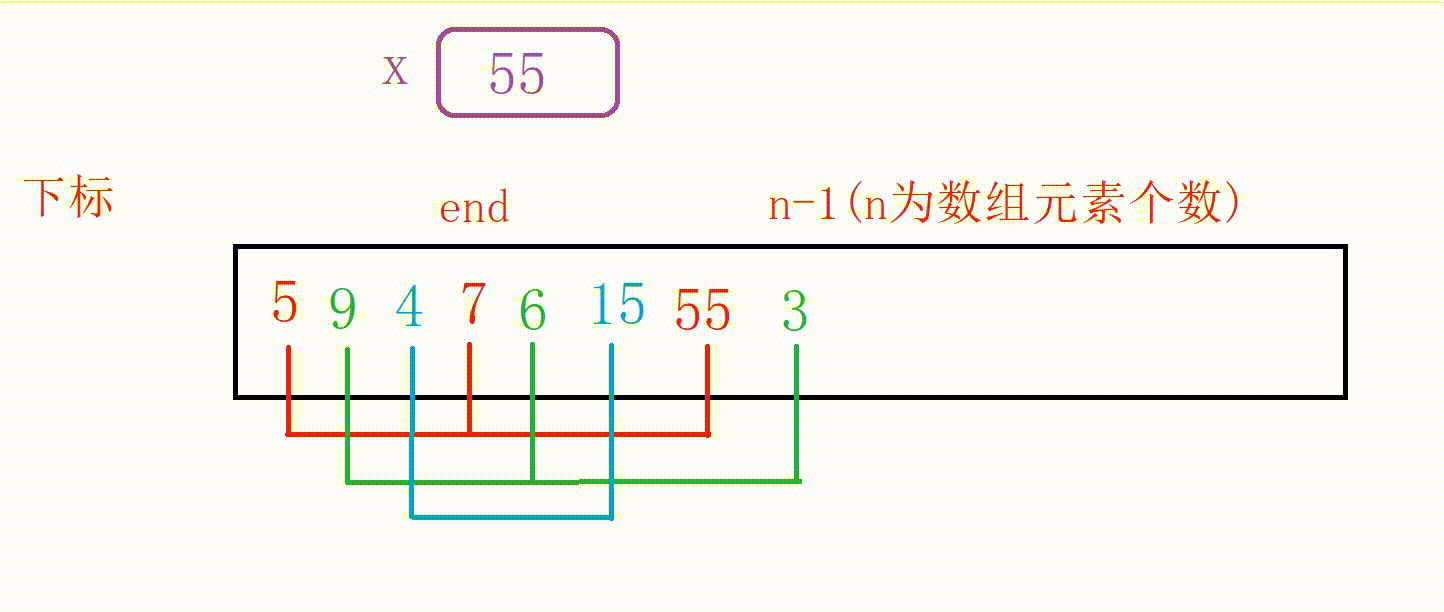
我们看下面这个有序数组a:
如果我们在后面添加一个数字5,应该如何调整为有序数组呢?
通过观察我们知道5应该插入在4后面
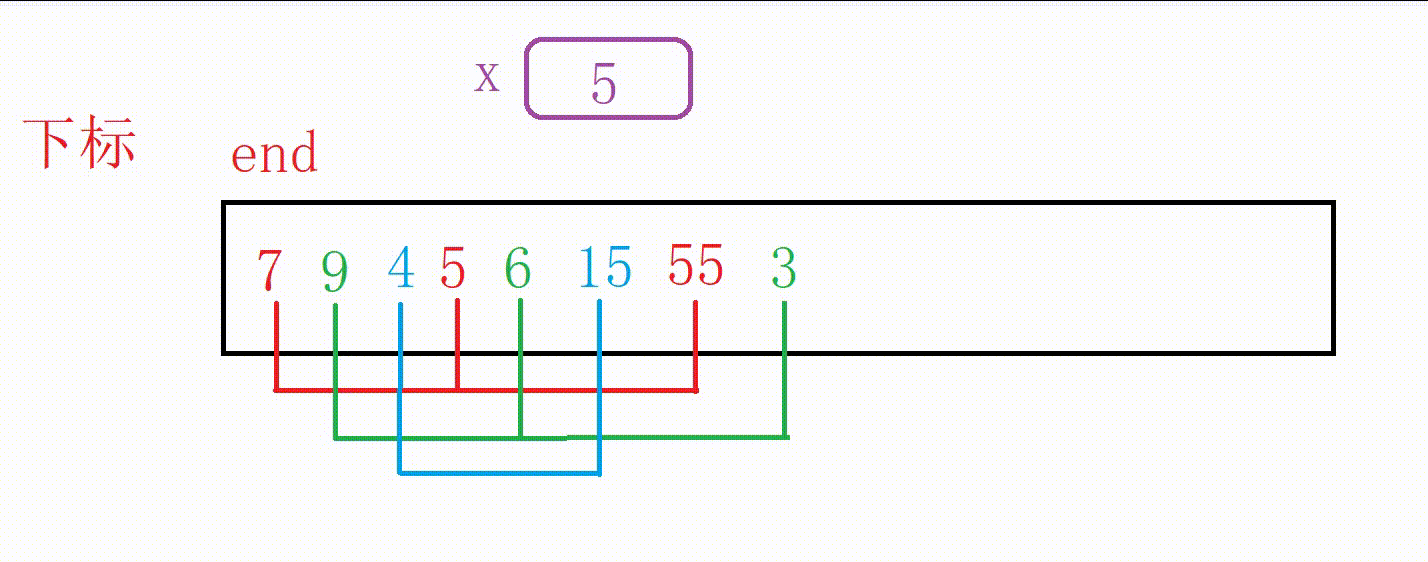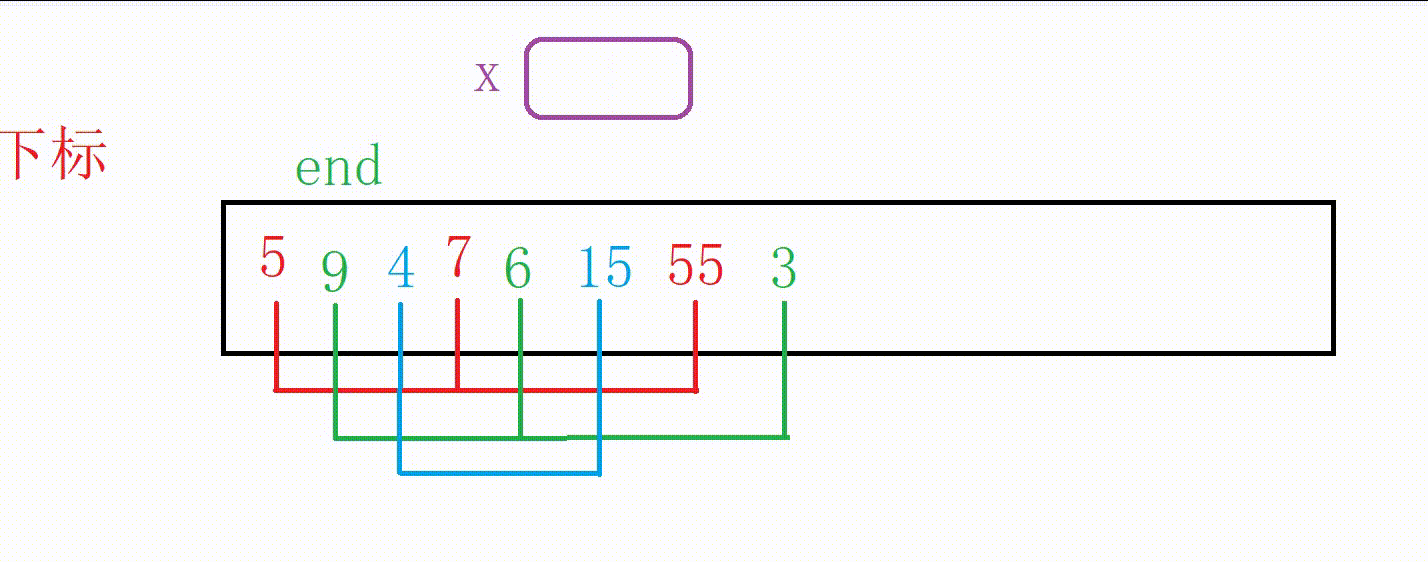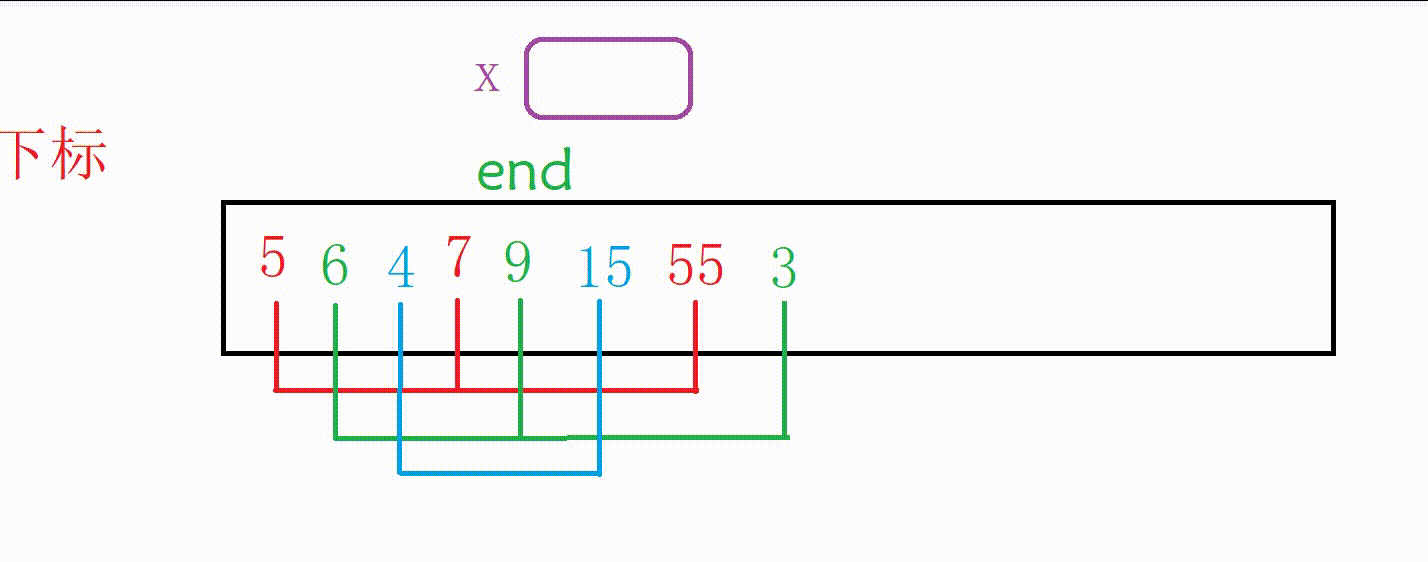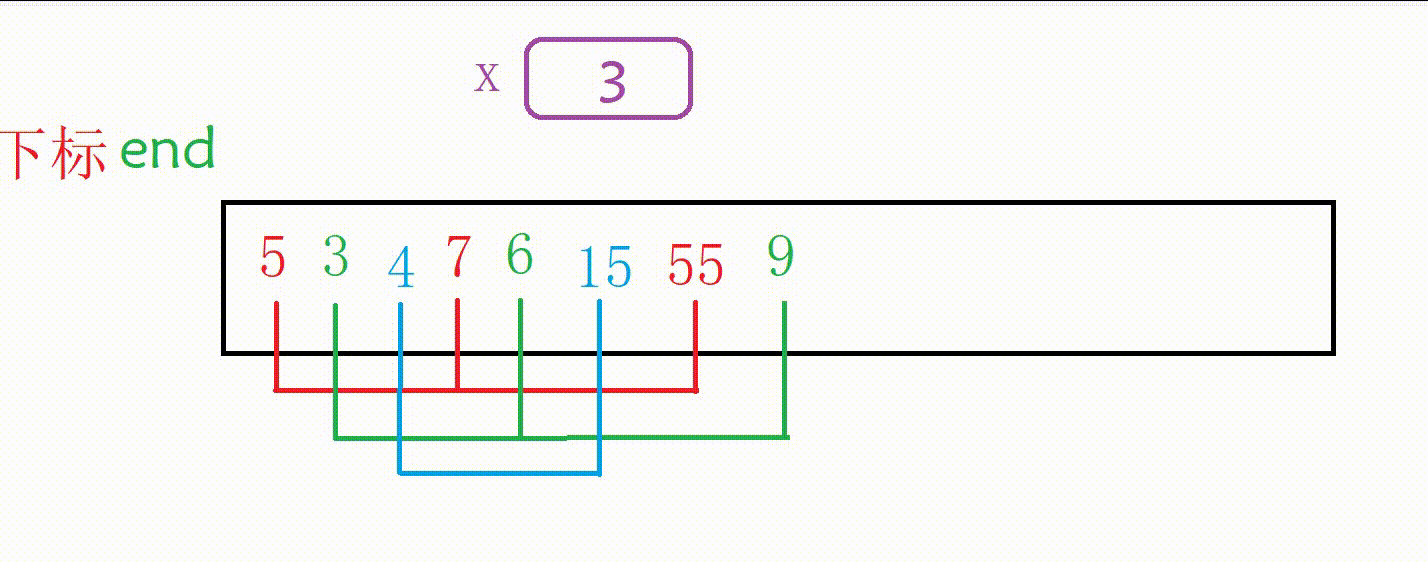
①我们可以设计一个变量end记录原数组尾部下标的位置
②如果a[end]大于5,我们用变量x记录5,然后10向后覆盖5的位置,end减1
③重复上一个步骤一直到找到比5小的数字或者end走到下标-1位置(这个时候整个数组后移一位),结束循环
④把5插入到下标为end+1的位置(无论是找到了跳出还是未找到跳出,都是这个位置)
图解:
代码(单趟):




完整排序
完整排序的思路就是记录数组下标的end从0开始
先让前两个数字有序,然后end+1
然后让前三个数字有序,end+1
重复上述步骤一直到整个数组完成排序
图解:
代码:


时间复杂度分析
①直接插入排序的最好情况是,输入的序列已经是有序的,此时时间复杂度为 O(N)。最坏情况是,输入的序列是倒序的,此时时间复杂度为 O(N^2)。平均情况下的时间复杂度也为O(N^2)
②我们可以通过数学方法对其时间复杂度进行分析。假设待排序的序列长度为N,则外层循环会执行N-1次,内层循环会从第二项开始逐项向前比较,直到找到该元素的插入位置或者找到第一项为止,内层循环平均需要比较一半的元素,即需要比较N/2次。因此总的时间复杂度为:T(N) = (N-1)*(N/2) = (N^2-N)/2 = O(N^2)
③可见,直接插入排序的时间复杂度是O(N^2)的,空间复杂度为O(1),它简单易懂,实现方便,尤其适合对小数列进行排序。但是,对于大规模的数据集,插入排序的性能就有些不尽如人意了,需要采用更高效的排序算法。
(2)希尔排序
希尔排序是对直接插入排序的优化
基础思路(有个印象就行,主要看单趟)
①先选定一个整数gap,把待排序数组中所有数据分成gap组②所有距离为gap的数据分在同一组内,并对每一组内的数据进行排序(这个过程称作预排序,可以让数组接近有序)。③然后,取不同gap重复上述分组和排序的工作。当到达gap=1时,再进行排序就完成整个数组的排序(gap为1时进行排序相当于进行了直接插入排序)。
单趟排序
我们第一次取gap为3,对下面这个数组就行分组
这里对每一组进行排序的思路和前面的直接插入排序基本一致
只是end的变化量由1变成了gap,待插入的数据从a[end+1]变成了a[end+gap],待插入的下标位置由end+1变成了end+gap
这里一共有两种实现方式(本质是一样的)
①我们外层多加一层循环,一组一组进行排序(组数为gap)
图解:
排红色组
排绿色组(蓝色组本来就有序,只判断)
代码:
②不需要分组,直接从从左向右一个个排序就行
代码:


完整排序
完整排序的要点主要在于控制gap的大小进行多次预排序(要确保最后一次循环gap为1)
①gap = n(n为数组元素个数),gap = gap/2
②gap = n(n为数组元素个数),gap = gap/3 + 1
(预排少,也可保证gap最后一次循环为1)
代码(本文用②):

- //希尔排序
- void ShellSort(int* a, int n)
- {
- int gap = n;
-
- 第一种写法,循环层数多一层
- 用来控制循环
- //int i = 0;
- //int j = 0;
- //
- //while (gap > 1)
- //{
- // gap = gap / 3 + 1;
- // //最外层——分成几组预排序
- // for (i = 0; i < gap; i++)
- // {
- // //进行一组的预排序
- // for (j = 0; j < n - gap; j += gap)
- // {
- // int end = j;
- // int x = a[end + gap];
- // while (end >= 0)
- // {
- // if (a[end] > x)
- // {
- // a[end + gap] = a[end];
- // end -= gap;
- // }
- // else
- // {
- // break;
- // }
- // a[end + gap] = x;
- // }
- // }
- // }
- //}
-
- //第二种写法,一锅炖,比较简洁
- //用来控制循环
- int i = 0;
- //最外层——分成gap组预排序
- while (gap > 1)
- {
- gap = gap / 3 + 1;
- //进行预排序
- for (i = 0; i < n - gap; i++)
- {
- int end = i;
- int x = a[end + gap];
- while (end >= 0)
- {
- if (a[end] > x)
- {
- a[end + gap] = a[end];
- end -= gap;
- }
- else
- {
- break;
- }
- }
- a[end + gap] = x;
- }
- }
- }

时间复杂度分析
希尔排序的时间复杂度与增量序列(gap)的选取有很大关系。
目前没有一种增量序列的选取方法可以使希尔排序的时间复杂度一定优于O(N*logN),但是实验表明,在大多数情况下,增量序列选取为Knuth序列时(gap = gap/3 +1),希尔排序的时间复杂度约为O(N^1.3)。这个时间复杂度优于插入排序的O(N^2),但是还不如快速排序和归并排序。
理论上,希尔排序最坏情况下的时间复杂度为O(N^2),与插入排序相同。最好情况下的时间复杂度与增量序列的选取有关。

二:选择排序
(1)直接选择排序
基础思路
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
单趟排序
单趟排序的思路比较简单,我们可以稍微优化一下,一次遍历同时找出最大和最小,可以提高一倍的效率。
图解:
然后这里交换的时候我们会发现有一个问题,那就是end和mini(最小值下标)重叠了
最小值和最大值位置交换了,这个时候应该把mini调整为maxi
代码:


完整排序
完整排序的要点是一次遍历完成后end和begin的范围应该收缩(end-1,begin+1)
当end和begin相同时排序完成
图解:
代码:

时间复杂度分析
直接选择排序的时间复杂度为O(N^2),其中N是待排序数组的长度。
在直接选择排序中,每个元素都需要和剩余未排序的元素进行比较
所以比较次数为 N+(N−1)+(N−2)+⋯+1
即第一轮需要进行 N-1次比较,第二轮需要进行N-2次比较
以此类推,最后一轮需要进行 1 次比较。这个等差数列的和为 N*(N-1)/2,所以总的比较次数为 O(N^2)。
另外,直接选择排序需要进行N次交换操作,因为每次找到最小元素后都需要将其与当前位置进行交换。但是交换操作的时间复杂度相对于比较操作来说比较低,为O(N),因此不影响总的时间复杂度。
总的来说,直接选择排序虽然比较简单,但是时间复杂度不够优秀,对于大规模的数据集合,效率会比较低下。
(2)堆排序
堆排序的实现以及时间复杂度分析之前一期讲的已经比较清楚了
之前一期链接:https://blog.csdn.net/2301_76269963/article/details/130157994?spm=1001.2014.3001.5501
这里简单讲讲实现思路:
1.构建堆:从待排序的数组中构建堆,可以使用二叉堆的构建算法,从最后一个有子节点的元素开始向下调整,使其满足堆的性质。
2.查找堆顶元素:堆的堆顶元素即为最大元素(或最小元素),将它取出并放到已排序的数组的末尾。
3.重新构建最大堆:将剩余未排序的元素重新构建成最大堆(或最小堆),重复上述过程,直到所有元素都排序完毕。
代码:
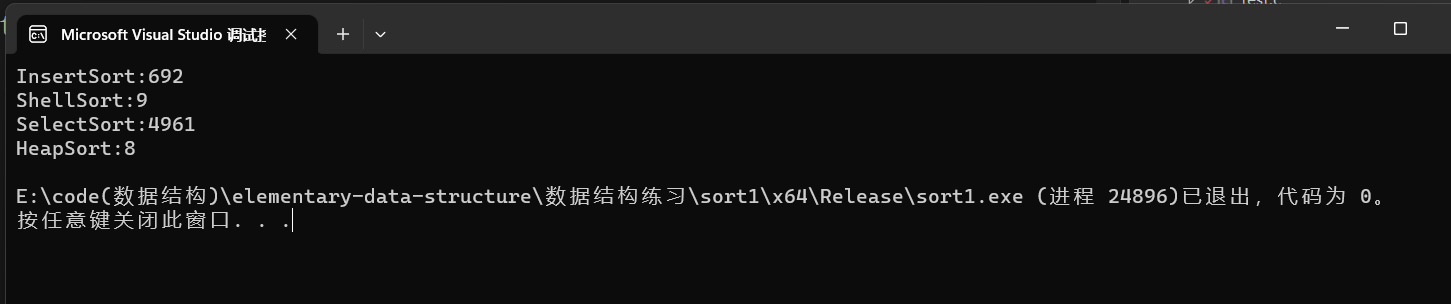
三:性能测试
代码:
效率对比: