
热门标签
热门文章
- 1全自动ai生成视频MoneyPrinterTurbo源码 在线ai生成视频源码
- 2免费小说阅读器(Android版本)全站开源_开源小说阅读器
- 3基于Java的甜品商城系统【附源码】_蛋糕商城源码
- 4spring框架_spring是一个轻量级的javaee
- 5配置微信小程序自动更新_小程序自动更新版本
- 6使用U盘在VMware虚拟机安装Windows和Ubuntu(Linux)系统,非常详细!_u盘配置vmware虚拟机ubuntu
- 7【大数据】一些基本概念_读取型schema
- 8Spring事务与数据库事务之间的关系_spring事务和数据库事务的关系
- 9MongoDB教程:创建用户并添加角色_mongodb 角色
- 10未来已来!AI数字人客服引领服务行业革新潮流_越来越多商圈 数字人客服
当前位置: article > 正文
Hadoop分布式集群环境搭建(三节点)_hadoop三节点集群yarn node -list显示0节点
作者:Li_阴宅 | 2024-06-21 02:14:15
赞
踩
hadoop三节点集群yarn node -list显示0节点
一、安装准备
- 创建hadoop账号
- 更改ip
安装Java 更改/etc/profile 配置环境变量
export $JAVA_HOME=/usr/java/jdk1.7.0_71修改host文件域名
172.16.133.149 hadoop101 172.16.133.150 hadoop102 172.16.133.151 hadoop103- 1
- 2
- 3
- 4
- 安装ssh 配置无密码登录
解压hadoop
/hadoop/hadoop-2.6.2
二、修改conf下面的配置文件
依次修改hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves文件。
1.hadoop-env.sh
`#添加JAVA_HOME:`
`export JAVA_HOME=/usr/java/jdk1.7.0_71`
- 1
- 2
2.core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.6.2/hdfs/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop101:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoop/hadoop-2.6.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hadoop/hadoop-2.6.2/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:9001</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6.slaves
hadoop102
hadoop103
- 1
- 2
- 3
7.最后,将整个hadoop-2.6.2文件夹及其子文件夹使用scp复制到两台Slave(hadoop102、hadoop103)的相同目录中:
scp -r \hadoop\hadoop-2.6.2\ hadoop@hadoop102:\hadoop\
scp -r \hadoop\hadoop-2.6.2\ hadoop@hadoop103:\hadoop\
- 1
- 2
- 3
- 4
三、启动运行Hadoop(进入hadoop文件夹下)
格式化NameNode
dfs namenode -format启动Namenode、SecondaryNameNode和DataNode
[hadoop@hadoop101]$ start-dfs.sh启动ResourceManager和NodeManager
[hadoop@hadoop101]$ start-yarn.sh最终运行结果
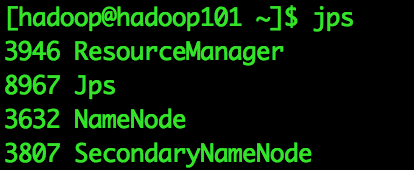
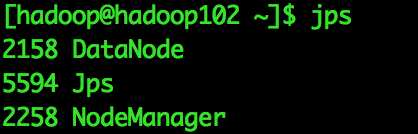
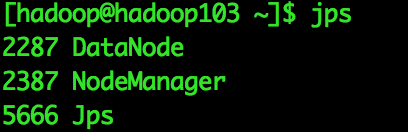
四、测试Hadoop
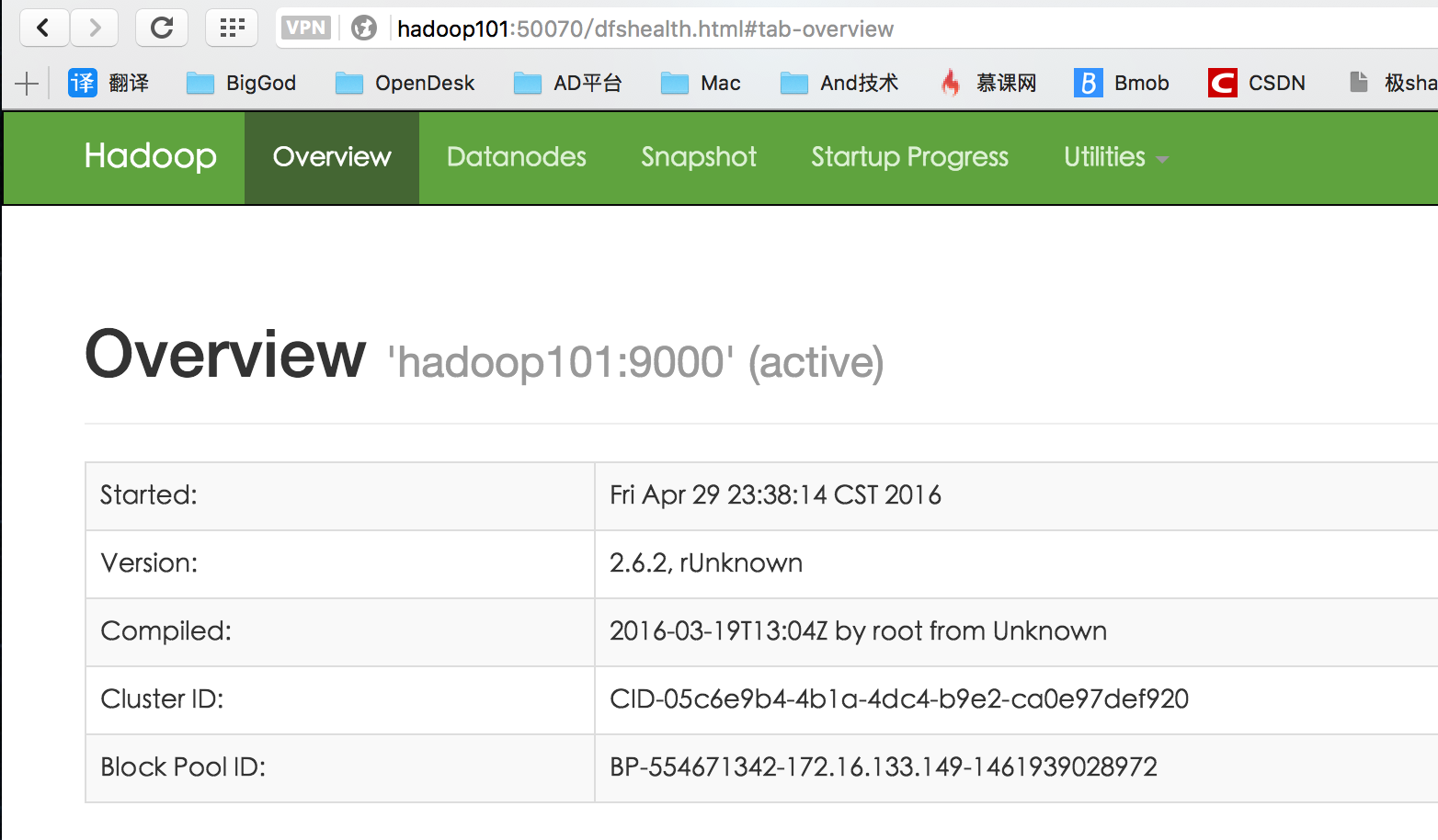
测试HDFS
浏览器输入http://<-NameNode主机名或IP->:50070
测试ResourceManager
浏览器输入http://<-ResourceManager所在主机名或IP->:8088
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

