
- 1系统集成项目管理工程师笔记_备考常见英文词汇汇总_中级集成项目管理工程师主要公式及英文缩写
- 2AI算力专题:海外科技启示录,英伟达超级工厂是怎样炼成的
- 3聊聊 Buck-Boost 升/降压电路_boostbuck电路应用场景
- 4Android Gradle 基础知识概括_mustrunafter
- 5charles修改请求参数_charles 参数替换
- 6在 AdventureX,我们看到这些语音 AI 的创新
- 7CentOS7远程登录(ssh)无法使用别名(alias)的解决方法_centos7 alias
- 8Yearning-SQL审核平台_yearning sql
- 92023王道考研数据结构笔记第五章——树_王道数据结构--树
- 10gradle打包流程(一)--- 整体把控_gradle项目如何打包
【Day 2】机器阅读理解——常见机器阅读理解模型(上)
赞
踩
引言
本文介绍 了BERT之前的常见机器阅读理解模型,包含机器阅读理解开篇之作的论文解读。
- 上一篇: 机器阅读理解简介
- 下一篇:常见机器阅读理解模型(下)
Glove词向量
Glove1解决word2vec只依赖局部信息的问题,基于全局信息构建词向量。
GloVe(Global Vectors)模型认为语料库中单词出现的统计(共现矩阵)是学习词向量表示的无监督学习算法的重要资料。
问题在于如何基于这些统计生成单词向量表示。
GloVe模型给出了一个答案,它利用了全局(整个)语料库的统计信息。
共现矩阵的例子:
不管语料库有多少篇文档,矩阵的表示考虑的是整个语料库的信息。
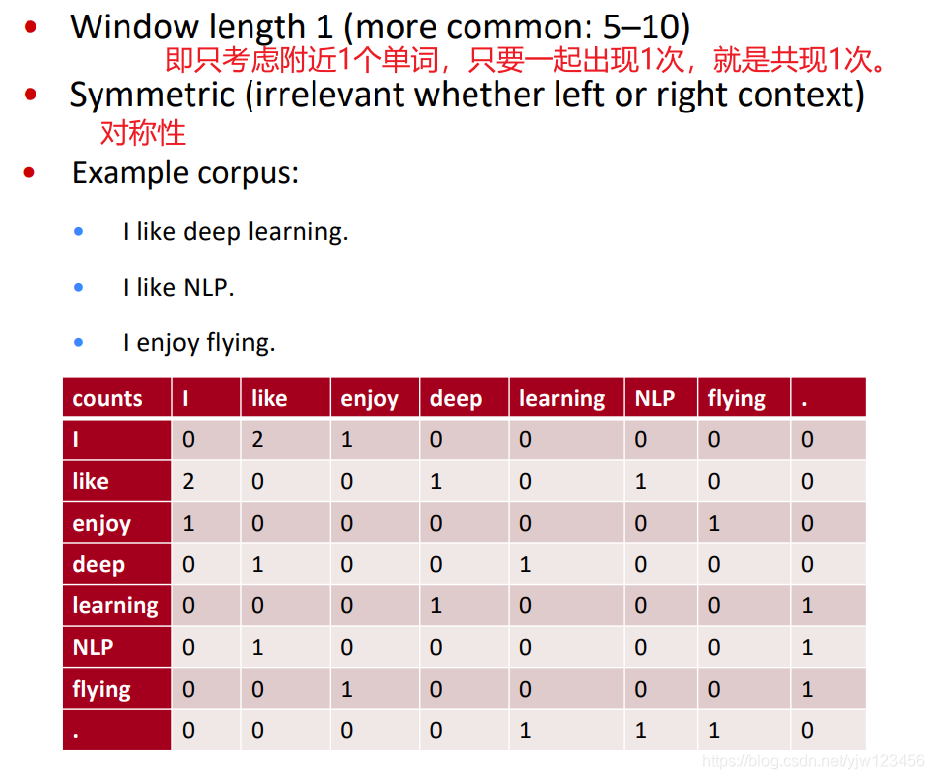
为了得到词向量表示,首先定义一些标记符号。记 X X X为单词-单词的词频共现矩阵。
其中的元素
X
i
j
X_{ij}
Xij表示单词
j
j
j 出现在单词
i
i
i上下文(context)的次数;
并且令
X
i
=
∑
k
X
i
k
X_i = \sum_k X_{ik}
Xi=∑kXik为任意单词出现在单词
i
i
i上下文的次数之和;
令 P i j = P ( j ∣ i ) = X i j X i P_{ij}=P(j|i)=\frac{X_{ij}}{X_i} Pij=P(j∣i)=XiXij为单词 j j j出现在单词 i i i上下文的概率。
通过一个简单的例子来展示是如何从共现概率抽取出某种语义的。考虑两个单词 i i i和 j j j之间的某种特殊兴趣。具体地,假设我们对热力学感兴趣,然后我们令 i = ice i=\text{ice} i=ice(冰)和 j = steam j=\text{steam} j=steam(蒸汽)。这两个单词之间的关系能通过研究它们基于不同单词 k k k得到的共现矩阵概率之比。对于与ice有关但与steam无关的单词,比如说 k = solid k=\text{solid} k=solid(固体),我们期望比值 P i k / P j k P_{ik}/P_{jk} Pik/Pjk会很大;类似地,对于与steam有关但与ice无关的单词,比如 k = gas k=\text{gas} k=gas(气体),该比值应该很小; 而对于那些与两者都相关或都不相关的单词,比如water(水)或fashion(时尚),比值应该接近于 1 1 1。

上表显示了在大语料库中的这些概率值,以及它们的比值,这些比值肯定了我们的期望。与原始概率相比,比值更能区分相关的单词(比如solid与gas)和不相关的单词(water与fashion),并且也能更好地区分这两个相关的单词。
上面的论述说明词向量学习的好的开端是从共现矩阵概率的比值开始,而不是从共现矩阵概率本身。接下来我们来设计模型,注意,下面很长一部分都是模型的设计阶段,没有严格的论证。
注意到比值
P
i
k
/
P
j
k
P_{ik}/P_{jk}
Pik/Pjk依赖于三个单词
i
,
j
i,j
i,j和
k
k
k,那么最常见的模型应该是如下形式:
F
(
w
i
,
w
j
,
w
∼
k
)
=
P
i
k
P
j
k
(1)
F(w_i,w_j,\overset{\sim}{w}_k) = \frac{P_{ik}}{P_{jk}} \tag{1}
F(wi,wj,w∼k)=PjkPik(1)
其中
w
∈
R
d
w \in R^d
w∈Rd是词向量,
w
∼
∈
R
d
\overset{\sim}{w} \in R^d
w∼∈Rd是区分上下文词向量。然后
F
F
F可能依赖于现在还未指定的参数。
可能的 F F F还是很广,但只要加入一些想法进去我们就能得到唯一的 F F F。
首先,我们希望
F
F
F能编码信息在词向量空间中表示比值
P
i
k
/
P
j
k
P_{ik}/P_{jk}
Pik/Pjk。因为向量空间是天然的线性结构,进行向量差计算是很自然的。基于此,我们可以限制函数
F
F
F只依赖于两个目标词的向量差,将
(
1
)
(1)
(1)式改写为
F
(
w
i
−
w
j
,
w
∼
k
)
=
P
i
k
P
j
k
(2)
F(w_i -w_j, \overset{\sim}{w}_k) = \frac{P_{ik}}{P_{jk}} \tag{2}
F(wi−wj,w∼k)=PjkPik(2)
现在,我们注意到上式中
F
F
F的参数是向量,而等式右边是标量。那么
F
F
F可以由一个复杂的函数,比如,神经网络表示,这样做会我们想要捕获的线性结构冲突。为了避免这个问题,我们让左边也变成标量,可以尝试取这些参数的点积。
F
(
(
w
i
−
w
j
)
T
w
∼
k
)
=
P
i
k
P
j
k
(3)
F((w_i-w_j)^T \overset{\sim}{w}_k) = \frac{P_{ik}}{P_{jk}} \tag{3}
F((wi−wj)Tw∼k)=PjkPik(3)
这样可以防止
F
F
F 以不想要的方式混合向量维度。
接下来,注意到单词-单词的共现矩阵是对称的,即改变单词和上下文词位置得到的值是一样的。我们的最终模型应该在这转换下保持不变。要满足这种对称性,需要做以下几步。
第一步,把减法的函数变成函数的除法。
F
(
(
w
i
−
w
j
)
T
w
∼
k
)
=
F
(
w
i
T
w
∼
k
−
w
j
T
w
∼
k
)
=
F
(
w
i
T
w
∼
k
)
F
(
w
j
T
w
∼
k
)
(4)
F((w_i-w_j)^T \overset{\sim}{w}_k) = F(w^T_i \overset{\sim}{w}_k - w_j^T \overset{\sim}{w}_k)=\frac{F(w^T_i \overset{\sim}{w}_k)}{F(w^T_j \overset{\sim}{w}_k)} \tag{4}
F((wi−wj)Tw∼k)=F(wiTw∼k−wjTw∼k)=F(wjTw∼k)F(wiTw∼k)(4)
联立(3)式,可得
F
(
w
i
T
w
∼
k
)
=
P
i
k
=
X
i
k
X
i
(5)
F(w_i^T\overset{\sim}{w}_k) = P_{ik} = \frac{X_{ik}}{X_i} \tag{5}
F(wiTw∼k)=Pik=XiXik(5)
要想让
(
4
)
(4)
(4)式成立,可以让
F
F
F为指数函数,然后取
l
o
g
log
log。
w
i
T
w
∼
k
=
log
(
P
i
k
)
=
log
(
X
i
k
)
−
log
(
X
i
)
(6)
w_i^T\overset{\sim}{w}_k = \log(P_{ik}) = \log(X_{ik}) - \log(X_i) \tag{6}
wiTw∼k=log(Pik)=log(Xik)−log(Xi)(6)
下面,我们注意到等式
(
6
)
(6)
(6)
如
果
没
有
如果没有
如果没有
log
(
X
i
)
\log(X_i)
log(Xi) ,就会满足对称的可交换性。然而,该项是与
k
k
k独立的,所以它可以吸收到
w
i
w_i
wi的偏差
b
i
b_i
bi中。最终,增加
w
∼
k
\overset{\sim}{w}_k
w∼k的偏差
b
∼
k
\overset{\sim}{b}_k
b∼k以保证可交换性。得到下面的等式:
w
i
T
w
∼
k
+
b
i
+
b
∼
k
=
log
(
X
i
k
)
(7)
w_i^T\overset{\sim}{w}_k +b_i + \overset{\sim}{b}_k = \log(X_{ik}) \tag{7}
wiTw∼k+bi+b∼k=log(Xik)(7)
此时如果把
i
i
i和
k
k
k对调,那么上式也成立。等式
(
7
)
(7)
(7)是等式
(
1
)
(1)
(1)的极大简化,但它实际上是有问题的,因为当它的参数为零时,对数就没发散了(
log
0
\log 0
log0)。一种解决方案类似拉普拉斯平滑,即增加一个小偏移,
log
(
X
i
k
)
→
log
(
1
+
X
i
k
)
\log(X_{ik}) \rightarrow \log(1+X_{ik})
log(Xik)→log(1+Xik),这样既维持了
X
X
X的稀疏性,又避免对数发散。
这样我们用词向量和偏差项表达了两个词共现的词频的对数。但是该模型的一个缺点是,它将所有的共现概率看成平等的,即使那些很少共现的情况。这些稀有的共现情形可能是噪音或者携带的信息不多。
同时我们希望等式
(
7
)
(7)
(7)两边越接近越好,因此我们利用均方误差(最小二乘法)计算损失,并引入了权重函数
f
(
X
i
j
)
f(X_{ij})
f(Xij)。
J
=
∑
i
,
j
=
1
V
f
(
X
i
j
)
(
w
i
T
w
∼
j
+
b
i
+
b
∼
j
−
log
X
i
j
)
2
(8)
J = \sum^{V}_{i,j=1} f(X_{ij})(w_i^T\overset{\sim}{w}_j +b_i + \overset{\sim}{b}_j - \log X_{ij} )^2 \tag{8}
J=i,j=1∑Vf(Xij)(wiTw∼j+bi+b∼j−logXij)2(8)
其中 V V V是词典大小,权重函数应该满足下面条件:
- f ( 0 ) = 0 f(0)=0 f(0)=0,也就是说如果两个词如果没有共同出现过,权重就是0。
- f ( x ) f(x) f(x)应该是非递减函数,所以经常出现的单词权重要大于很少一起出现的单词。
- f ( x ) f(x) f(x)对于较大的 x x x不能取太大的值,所以一些经常出现的词权重不会太大,比如一些停止词。
满足以上条件的函数很多,作者采用了下面的分段函数:
f
(
x
)
=
{
(
x
/
x
m
a
x
)
α
if
x
<
x
m
a
x
1
otherwise
.
(9)
f(x) = {(x/xmax)αif x<xmax1otherwise .
当
α
\alpha
α取
3
/
4
3/4
3/4时,函数图像如下:

模型的表现有一点点依赖于 x m a x x_{max} xmax的取值,在作者的实验中都取 x m a x = 100 x_{max}=100 xmax=100。作者发现 α \alpha α取 3 / 4 3/4 3/4要优于取 1 1 1时的线性函数。
该模型生成两组词向量, W W W和 W ∼ \overset{\sim}{W} W∼。当 X X X是对称的时候,这两组词向量是等价的,唯一不同的是它们随机初始化的结果;另一方面,有证据表明,对于某些类型的神经网络,训练神经网络的多个实例,然后组合训练结果能有助于减少过拟合和噪声,通常也会改善结果。因此,作者采用 W + W ∼ W + \overset{\sim}{W} W+W∼之和作为词向量。
TextCNN
使用CNN来做句子级分类任务。
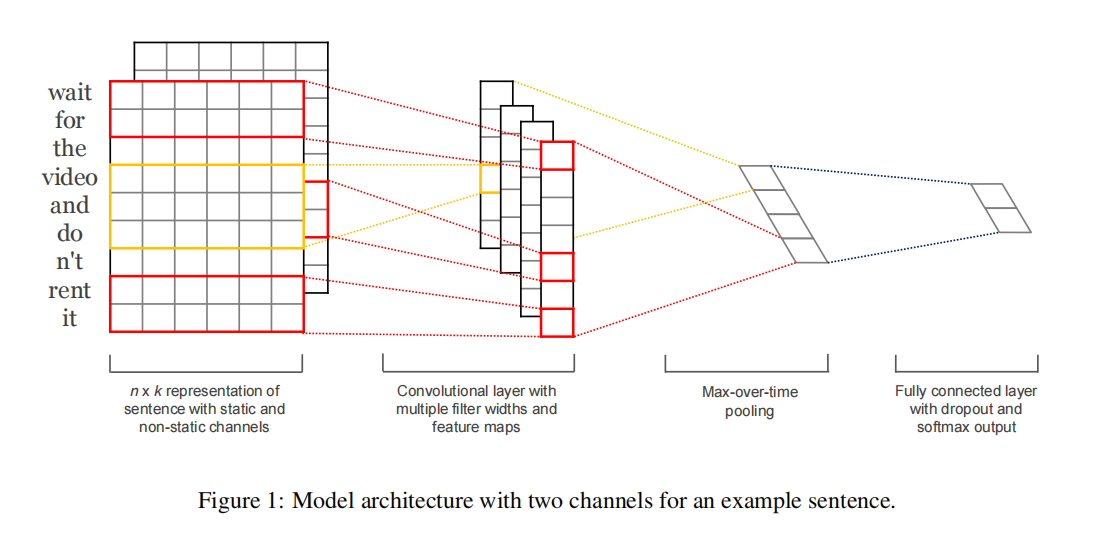
作者提出了一种将简单的CNN应用在无监督方法(word2vec或Glove)得到的词向量上,来完成句子分类任务。
主要思想提现在上图。下面通过符号来描述一下。
令
x
i
∈
R
k
x_i \in \Bbb{R}^k
xi∈Rk表示句子中第
i
i
i个单词对应的
k
k
k维向量,假设句子最大长度为
n
n
n(短的则填充),表示为:
x
1
:
n
=
x
1
⊕
x
2
⊕
⋯
⊕
x
n
x_{1:n} = x_1 \oplus x_2 \oplus \cdots \oplus x_n
x1:n=x1⊕x2⊕⋯⊕xn
其中$\oplus
是
拼
接
操
作
;
是拼接操作;
是拼接操作;x_{i:i+j}
表
示
单
词
序
列
表示单词序列
表示单词序列x_i,x_{i+1},\cdots, x_{i+j}$的拼接。
卷积操作用到的过滤器
w
∈
R
h
k
w \in \Bbb{R}^{hk}
w∈Rhk,应用到
h
h
h个单词的窗口上来产生一个新的特征。比如,特征
c
i
c_i
ci由单词序列
x
i
:
i
+
h
−
1
x_{i:i+h-1}
xi:i+h−1的窗口产生:
c
i
=
f
(
w
⋅
x
i
:
i
+
h
−
1
+
b
)
c_i = f(w \cdot x_{i:i+h-1} + b)
ci=f(w⋅xi:i+h−1+b)
这里
b
∈
R
b \in \Bbb{R}
b∈R是偏置项,
f
f
f是非线性函数,得到的特征
c
i
c_i
ci是一个实数。
重复应用该过滤器到句子中可能的单词窗口
{
x
1
:
h
,
x
2
:
h
+
1
,
⋯
,
x
n
−
h
+
1
:
n
}
\{x_{1:h},x_{2:h+1},\cdots,x_{n-h+1:n}\}
{x1:h,x2:h+1,⋯,xn−h+1:n}上得到特征向量(feature map):
c
=
[
c
1
,
c
2
,
⋯
,
c
n
−
h
+
1
]
c = [c_1,c_2,\cdots, c_{n-h+1}]
c=[c1,c2,⋯,cn−h+1]
其中
c
∈
R
n
−
h
+
1
c \in \Bbb{R}^{n-h+1}
c∈Rn−h+1,接着在特征向量上应用一个max-over time池化操作得到向量中值最大的元素
c
^
=
max
{
c
}
\hat c =\max\{c\}
c^=max{c}作为该过滤器得到的特征,这为了得到最重要的特征。
这样一个过滤器得到了一个特征,通过应用多个过滤器(窗口大小不同)并进行池化后就得到了多个特征。
这些特征构成了模型的倒数第二层,然后传递到一个包含Softmax的全连接层就得到了最终的输出。
Attention机制
注意力(Attention)机制来源于人类的视觉注意力机制,即根据需要关注重要部分。赋予模型对于重要性区分+辨别能力,本质是一系列的权重分配。
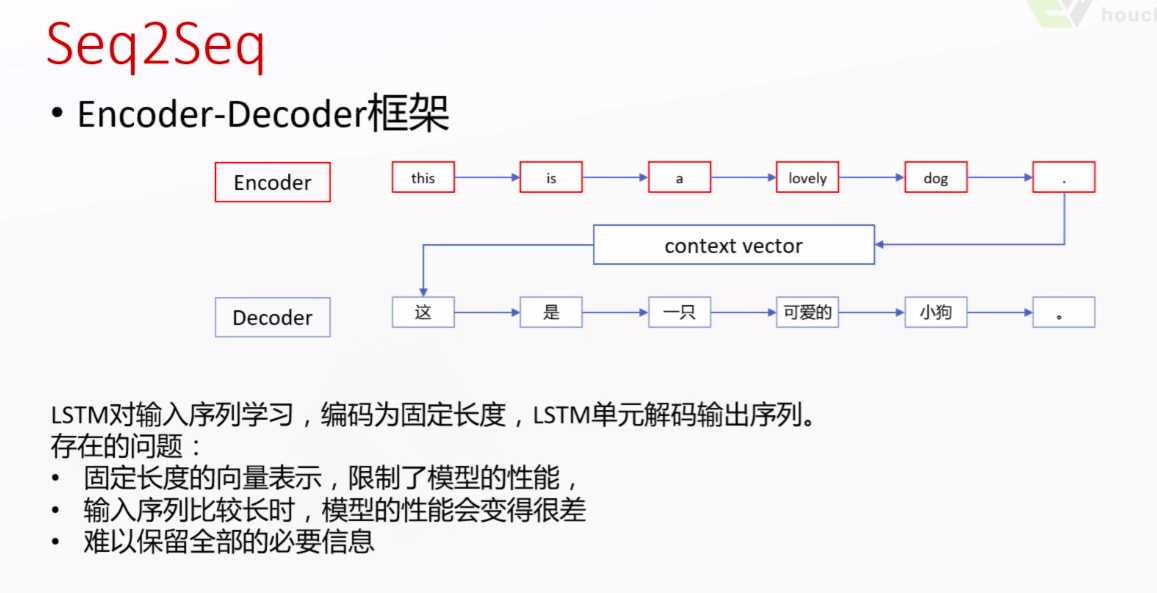
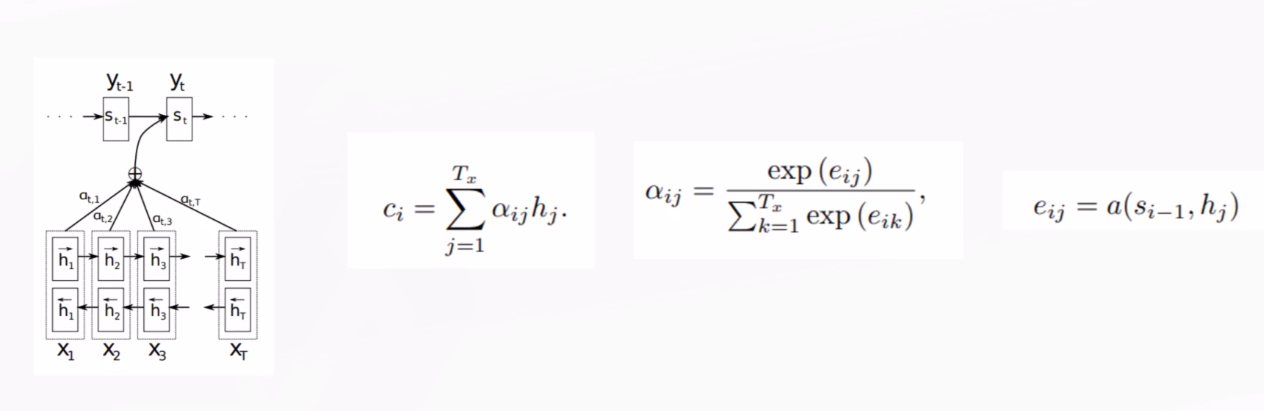
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE2为Seq2Seq引入了注意力机制。
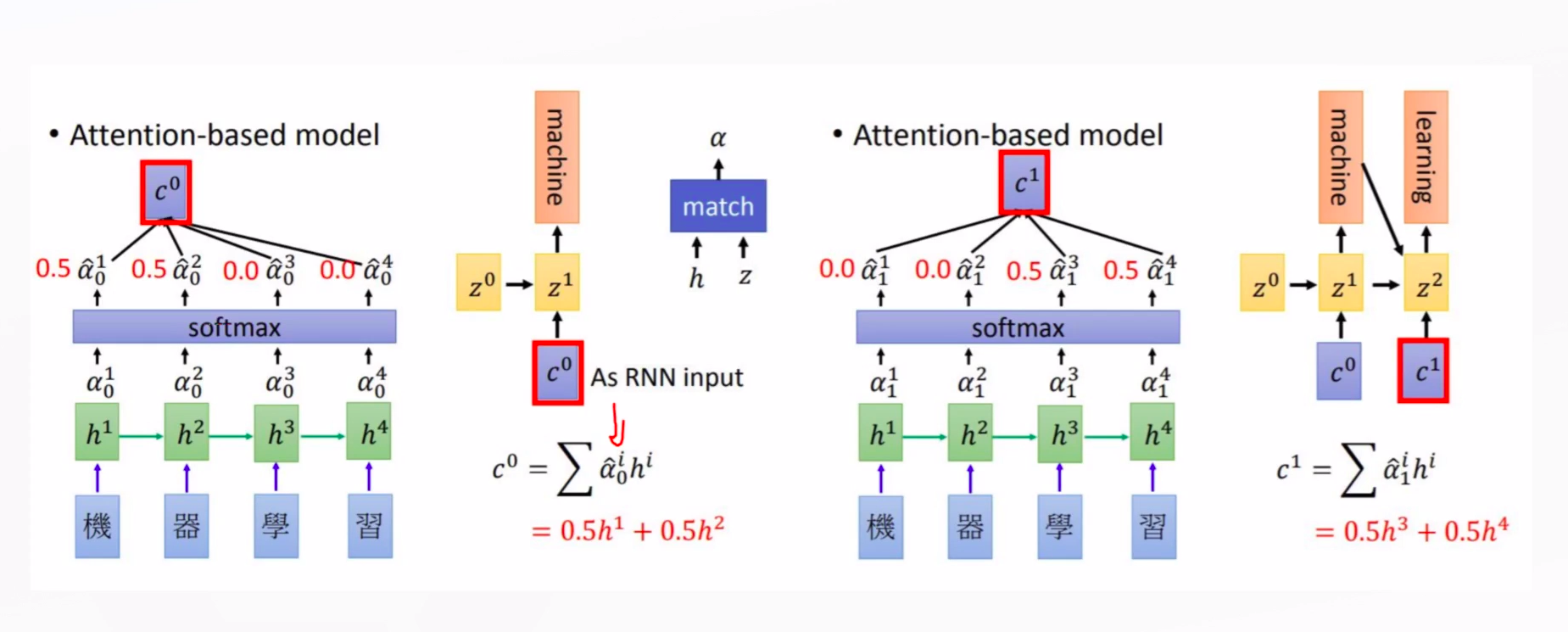
注意力本质上是加权的和,给适当的单词赋予加大的权重。比如在上面的翻译例子中,翻译出单词“learning”的时候要给字“学”和“习”较大的权重,赋予更多的注意力在这两个字上。
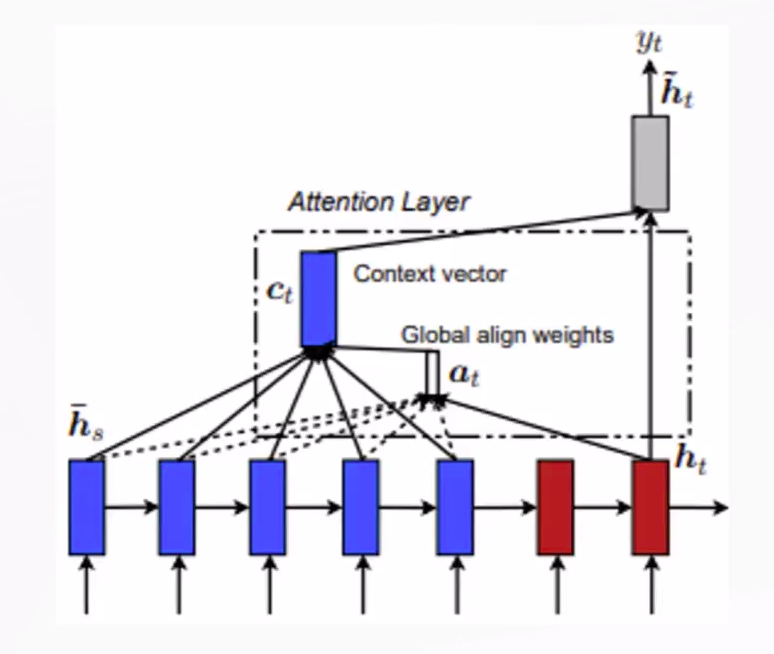
常见的Attention类型:
-
Global Attention:所有的隐藏状态都被用于计算上下文向量的权重。
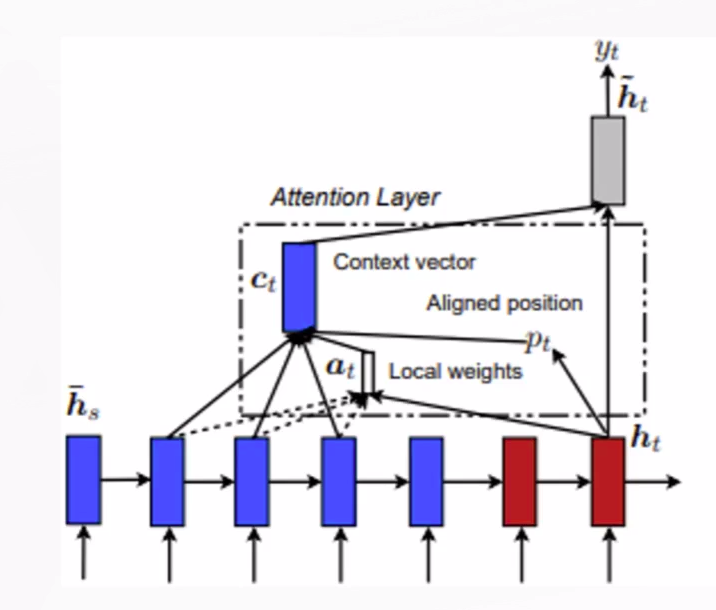
-
Local Attention: 预测source端对齐的位置pt,然后基于pt选择一个窗口,用于计算向量ct。
-
Self-Attention
相似度计算方法
在做Attention的时候,我们需要计算查询 q q q和某个 k k k的相似度(分数),常用方法有:
- 一般形式 s ( q , k ) = q T W k s(q,k) = q^TWk s(q,k)=qTWk (适用于 q q q与 k k k的维度不匹配,加上一个 W W W来匹配维度)
- 点乘 s ( q , k ) = q T k s(q,k)=q^Tk s(q,k)=qTk (适用于 q , k q,k q,k维度匹配)
- 余弦相似度 s ( q , k ) = q T k ∣ ∣ q ∣ ∣ ⋅ ∣ ∣ k ∣ ∣ s(q,k)=\frac{q^Tk}{||q||\cdot ||k||} s(q,k)=∣∣q∣∣⋅∣∣k∣∣qTk
- 串联方式:把 q q q和 k k k拼接起来 s ( q , k ) = W [ q ; k ] s(q,k)=W[q;k] s(q,k)=W[q;k]
- 单层感知机 s ( q , k ) = v a T tanh ( W q + U k ) s(q,k) = v^T_a \tanh(Wq + Uk) s(q,k)=vaTtanh(Wq+Uk)
Attentive Reader & Impatient Reader
Teaching Machines to Read and Comprehend3是阅读理解一维匹配模型和二维匹配模型的开山鼻祖。
发布了CNN&Daily Mail数据集。
Attentive Reader
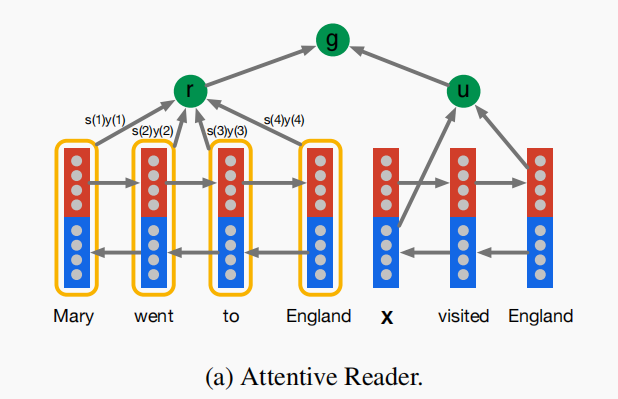
基于双向LSTM模型来编码文档(document)和查询(query)。
分别标记LSTM的正向和反向输出为 y → ( t ) \overrightarrow{y}(t) y (t)和 y ← ( t ) \overleftarrow{y}(t) y (t);
长度为 ∣ q ∣ |q| ∣q∣的查询的编码 u u u由最终的前向和反向输出拼接而成,即 u = y → q ( ∣ q ∣ ) ∣ ∣ y ← q ( 1 ) u = \overrightarrow{y}_q(|q|) || \overleftarrow{y}_q(1) u=y q(∣q∣)∣∣y q(1),其中 ∣ ∣ || ∣∣是拼接操作。
文档由每个时刻
t
t
t内的双向输出拼接而成,其中
y
d
(
t
)
=
y
→
d
(
t
)
∣
∣
y
←
d
(
t
)
y_d(t)= \overrightarrow{y}_d(t) || \overleftarrow{y}_d(t)
yd(t)=y
d(t)∣∣y
d(t),文档的表示
r
r
r是由这些输出进行加权和而得。权重可以看成是回答查询
q
u
e
r
y
query
query时关于文档中每个单词的注意力,首先计算问题表示
u
u
u和文档表示中每个单词的相似度,相似度越多表示赋予的注意力越多:
m
(
t
)
=
tanh
(
W
y
m
y
d
(
t
)
+
W
u
m
u
)
s
(
t
)
∝
exp
(
w
m
s
T
m
(
t
)
)
m(t) =\tanh(W_{ym}y_d(t) + W_{um}u) \\ s(t) ∝ \exp(w^T_{ms}m(t))
m(t)=tanh(Wymyd(t)+Wumu)s(t)∝exp(wmsTm(t))
接着进行归一化,注意还有一个计算相似度的权重移动到了
e
x
p
exp
exp函数里面。
上式就是我们上节中介绍的相似度计算方法里面的最后一种。
得到注意力得分,我们把所有时刻的
y
d
(
t
)
y_d(t)
yd(t)放到一起,组成了矩阵
y
d
y_d
yd。然后文档编码
r
r
r就是所有时刻的
y
d
(
t
)
y_d(t)
yd(t)的加权和:
r
=
y
d
s
r = y_ds
r=yds
模型的输出同时联合了
r
r
r和
u
u
u:
g
A
R
(
d
,
q
)
=
tanh
(
W
r
g
r
+
W
u
g
u
)
g^{AR}(d,q) = \tanh(W_{rg}r + W_{ug}u)
gAR(d,q)=tanh(Wrgr+Wugu)
该输出可用于计算答案的单词概率分布。
Attentive Reader可以看成是内存网络做问答任务的一般应用,属于一维匹配模型:问题编码成固定长度的向量,计算文档 D D D每个词在特定问题上下文向量中作为答案的概率
Impatient Reader
Impatient Reader不是拿 u u u和文档中每个单词去计算权重,而是直接拿查询中的每个单词去计算文档中每个单词的权重。对于查询中每个单词 i i i,模型都会使用查询单词 i i i的双向嵌入向量拼接的结果, y q ( i ) = y → q ( i ) ∣ ∣ y ← q ( i ) y_q(i) = \overrightarrow{y}_q(i) || \overleftarrow{y}_q(i) yq(i)=y q(i)∣∣y q(i),去计算一个文档表示向量 r ( i ) r(i) r(i),同时在计算相似度和 r ( i ) r(i) r(i)时都依赖 r ( i − 1 ) r(i-1) r(i−1)。
首先初始化
r
(
0
)
=
r
0
r(0)=r_0
r(0)=r0,
r
(
i
)
r(i)
r(i)的计算为:
r
(
i
)
=
y
d
T
s
(
i
)
+
tanh
(
W
r
r
r
(
i
−
1
)
)
1
≤
i
≤
∣
q
∣
r(i) = y_d^T s(i) + \tanh(W_{rr}r(i − 1)) \,\,\,\, 1 ≤ i ≤ |q|
r(i)=ydTs(i)+tanh(Wrrr(i−1))1≤i≤∣q∣
s
(
i
)
s(i)
s(i)是查询中的单词
i
i
i对文档中每个单词的注意力(权重),计算为:
s
(
i
,
t
)
∝
exp
(
w
m
s
T
m
(
i
,
t
)
)
s(i, t) ∝ \exp (w^T_{ms}m(i, t))
s(i,t)∝exp(wmsTm(i,t))
m
(
i
,
t
)
m(i,t)
m(i,t)计算为:
m
(
i
,
t
)
=
tanh
(
W
d
m
y
d
(
t
)
+
W
r
m
r
(
i
−
1
)
+
W
q
m
y
q
(
i
)
)
,
1
≤
i
≤
∣
q
∣
m(i, t) = \tanh (W_{dm}y_d(t) + W_{rm}r(i − 1) + W_{qm}y_q(i)), 1 ≤ i ≤ |q|
m(i,t)=tanh(Wdmyd(t)+Wrmr(i−1)+Wqmyq(i)),1≤i≤∣q∣
可以看到计算
m
(
i
,
t
)
m(i,t)
m(i,t)时也融入了
r
(
i
−
1
)
r(i-1)
r(i−1)的信息。
最后的输出是用最后一个
r
(
∣
q
∣
)
r_(|q|)
r(∣q∣)与
u
u
u综合得到的结果:
g
I
R
(
d
,
q
)
=
tanh
(
W
r
g
r
(
∣
q
∣
)
+
W
q
g
u
)
g^{IR}(d,q) = \tanh(W_{rg}r(|q|) + W_{qg}u)
gIR(d,q)=tanh(Wrgr(∣q∣)+Wqgu)
Impatient Reader属于二维匹配模型:问题 Q Q Q每个词编码,计算问题 Q Q Q中每个词对 D D D中每个词的注意力,形成词-词的二维匹配结构,模型效果要稍微优于一维匹配模型。
Bi-DAF
BiDAF4是阅读理解的开山之作。
作者提出了双向注意力流网络(Bi-Directional Attention Flow,BiDAF),是一种层级架构的多粒度文本表示建模方法,可以表示不同粒度级别的上下文,使用双向注意流机制获取查询感知(query-aware)的上下文表示,而不是压缩上下文到定长向量。
核心思想
BiDAF包含字符级、单词级和上下文嵌入,并使用双向注意力流获取查询感知的上下文表示。
-
这里的注意力层没有将上下文压缩到定长向量,而是在每个时间步上计算注意力,并允许每层的向量表示能传递到后续层,减少了信息损失。
-
采用无记忆的注意力机制,在当前时间步的注意力并不依赖之前(时间步)的注意力的值。这可以强制注意力层专注于在查询和上下文间学习注意力,并使建模层专注于学习查询感知的上下文表示内的交互(注意层的输出)。
-
采用的注意力是双向的,既有从上下文(文章)到查询(问题)的注意力,又有从查询到上下文的注意力。
作者提出的模型是一种多阶段的层级架构,由六层组成(如上图所示)。我们来详细看下每层。
字符级嵌入层(Character Embedding Layer)
使用字符级CNN映射每个单词到高维向量空间。主要用于解决未登陆词问题,和BERT时代的BBPE有异曲同工之妙。
假设 { x 1 , ⋯ , x T } \{x_1,\cdots,x_T\} {x1,⋯,xT}和 { q 1 , ⋯ , q J } \{q_1,\cdots,q_J\} {q1,⋯,qJ}分别代表输入的上下文和查询中的单词。使用CNN网络获取每个单词的字符级嵌入向量。
把上下文和查询中的每个单词输入到1D-CNN后,我们会分别得到下上文和查询的嵌入矩阵,这些矩阵的长度与上下文或查询的长度相同,矩阵的高度依赖于1D-CNN中应用的卷积核数量。
本小节图片来自于https://nlp.seas.harvard.edu/slides/aaai16.pdf
为了更好的理解字符级CNN,我们一起看一个例子。
假设我们想要在单词“absurdity”(荒谬)上应用1D-CNN。首先单词中的每个字符表示为 d d d维的向量,这些向量可以是随机初始化的。单词中的所有字符会形成一个 d × l d \times l d×l的矩阵 C C C, l l l是单词中字符数量。
假设我们这里的 d = 4 d=4 d=4,我们刚开始得到如下矩阵。
然后,我们应用一个卷积核 H H H来扫描单词,卷积核的高度与 C C C相同,它的宽度通常小于 l l l,并且不同的卷积核是不同的。卷积核中的值也是随机初始化,并且可学习的。这里假设该卷积核的宽度为 w = 3 w=3 w=3。
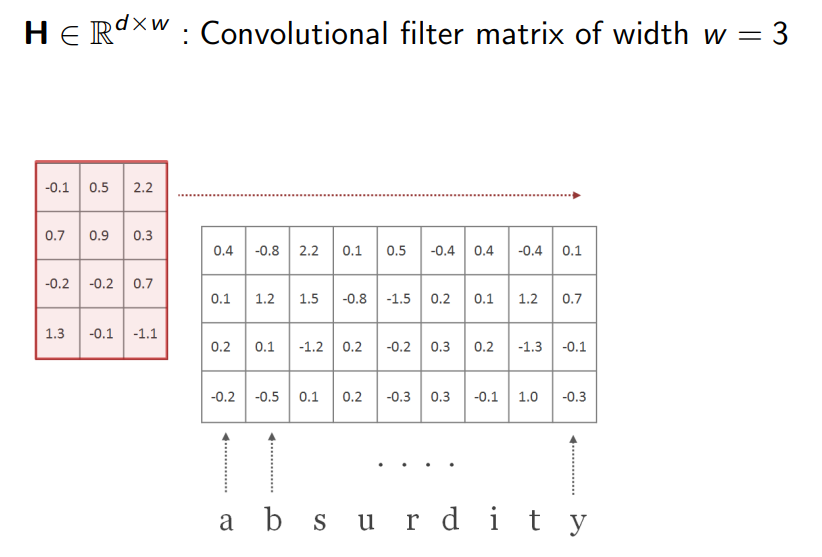
把卷积核 H H H覆盖到矩阵 C C C的最左边,应用卷积运算得到一个标量。
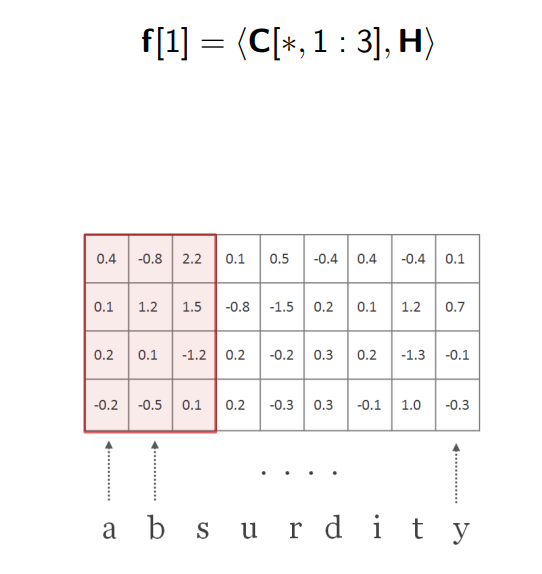
如上图所示,我们框住了该矩阵中前三个字符,经过卷积运算得到标量 0.1 0.1 0.1,作为输出的新向量 f f f的第一个元素值。
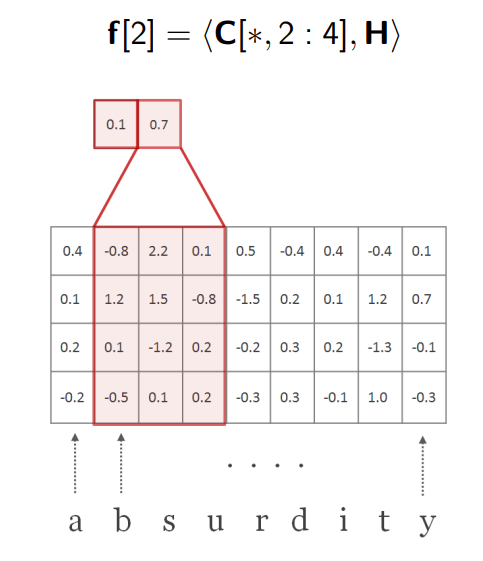
把卷积核向右移动一步,得到第二个标量 0.7 0.7 0.7,作为 f f f向量的第二个元素。
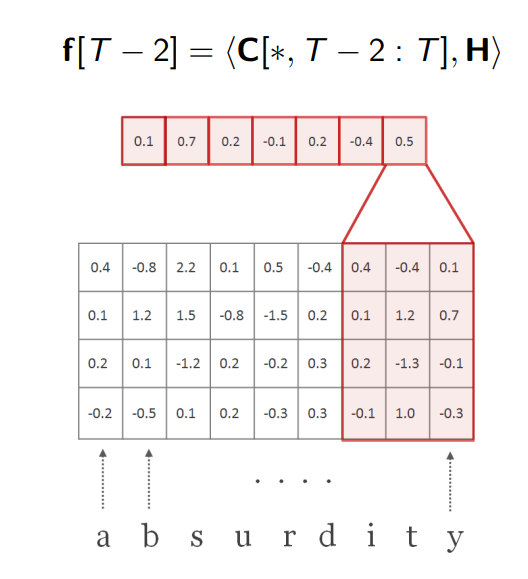
重复该步骤,直到卷积核移动到了最右端,这样就得到完整的 f f f向量,它的长度是 l − w + 1 l-w+1 l−w+1。该向量时我们通过这个卷积核得到的单词数值表示。
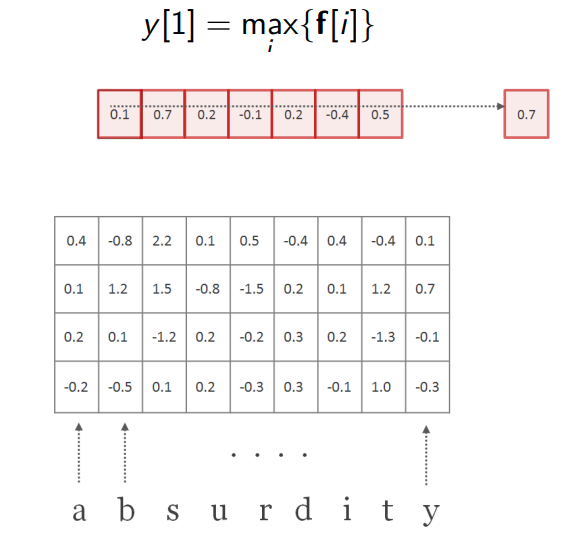
接着,再应用一个最大池化操作到 f f f上,最大池化可以看成是取最重要的信息。我们这里最大池化后的输出为 0.7 0.7 0.7。
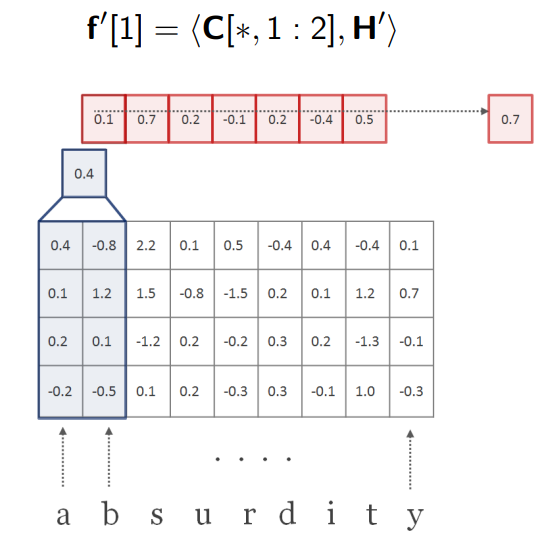
假设我们再应用另一个宽度 w = 2 w=2 w=2的卷积核 H ′ H^\prime H′,又可以得到另一个向量 f ′ f^\prime f′。
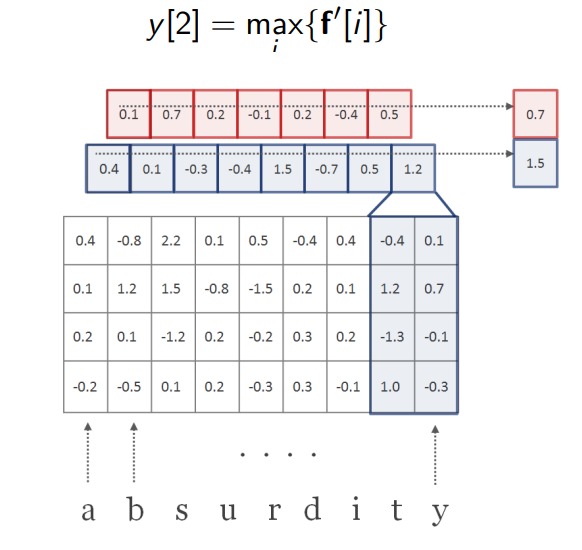
虽然 f ′ f^\prime f′的长度和 f f f不同,但是经过最大池化后还是得到一个标量。
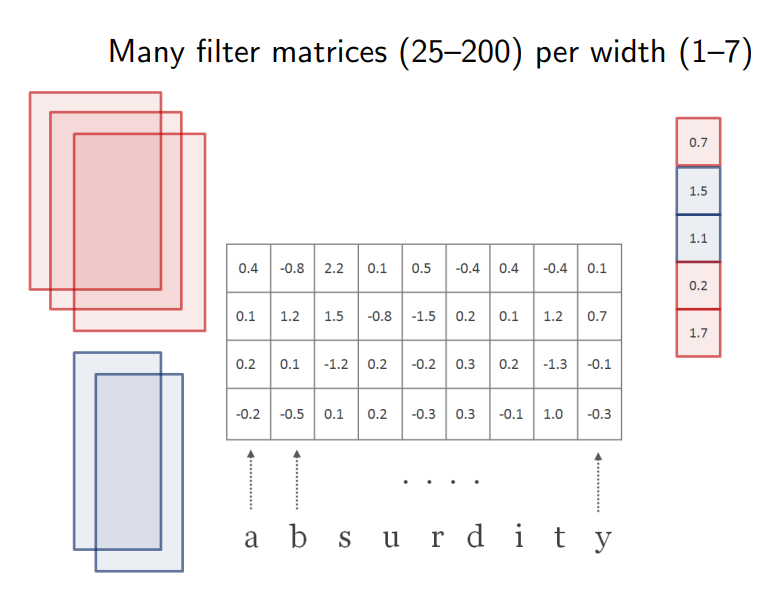
我们可以使用不同宽度的卷积核重复这种扫描操作,每个卷积核可以得到一个标量。把这些标量拼在一起就可以看成是该单词的嵌入向量。
这里获得了一个单词的嵌入向量,把整个上下文或问题的单词都操作一遍,就可以得到它们的嵌入矩阵。嵌入矩阵的高度和卷积核的数量相同,宽度等同于上下文或问题中的单词数量。
至此,字符级嵌入层分析完毕,我们来看单词级嵌入层。
单词级嵌入层(Word Embedding Layer)
使用预训练的词嵌入模型映射单词到高维向量空间。作者使用的预训练词嵌入模型是GloVe。
得到了GloVe输出的定长词嵌入向量之后。燃料后将上面得到的字符级嵌入和这里的单词级嵌入进行垂直拼接(叠加),输入到一个两层的高速网络(Highway network)5,该网络的输出是两个矩阵,分别是对应上下文的 X ∈ R d × T X \in \Bbb{R}^{d \times T} X∈Rd×T和对应问题的 Q ∈ R d × J Q \in \Bbb{R}^{d \times J} Q∈Rd×J。
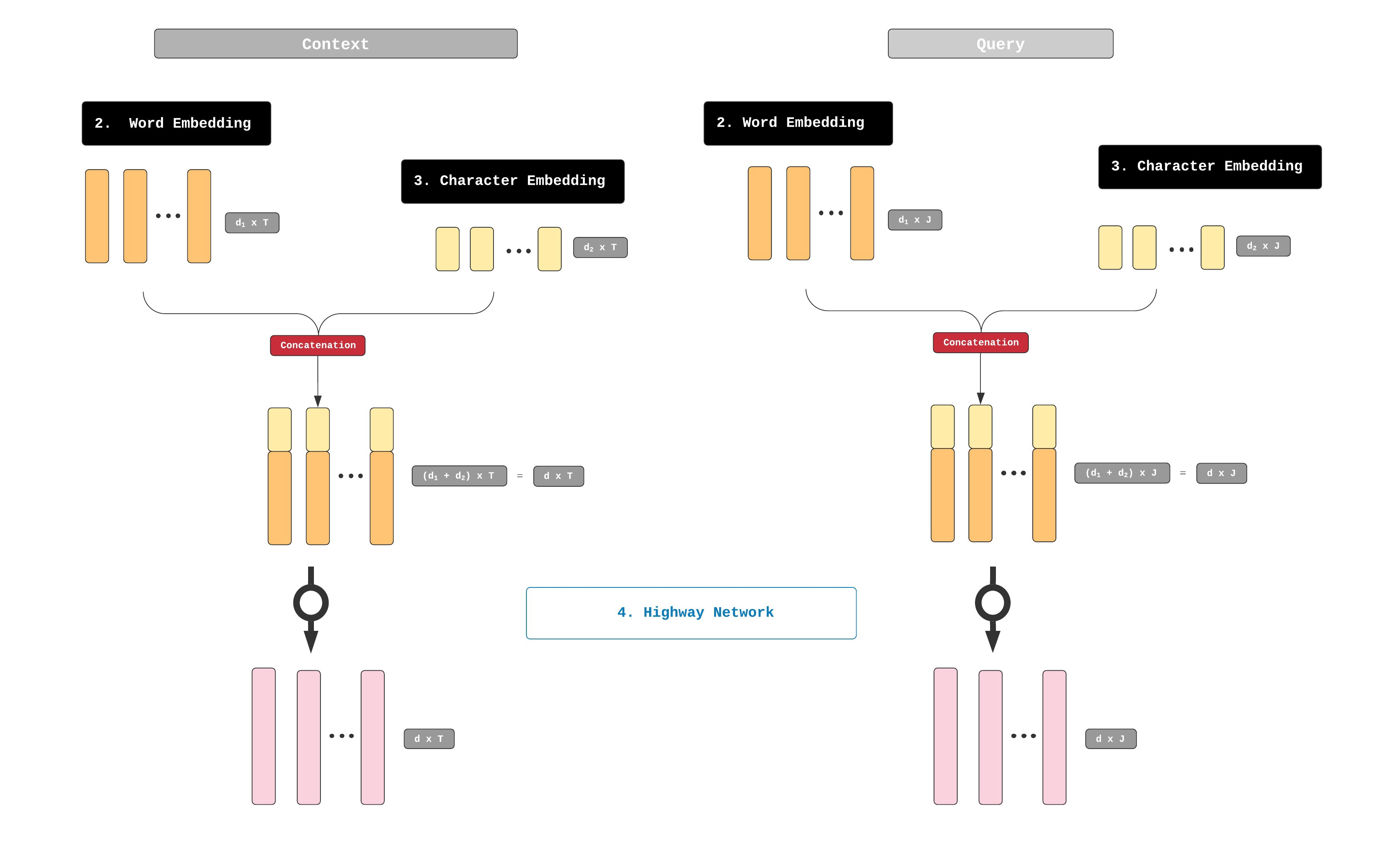
整个过程如上图所示,我们来看下高速网络。
其实思想很简单,启发于LSTM中,使用门阀函数来选择性的传递信号到下一层。
y
=
H
(
x
,
W
H
)
y = H(x,W_H)
y=H(x,WH)
通常
H
H
H是普通前馈神经网络中的仿射变换(affine transform),然后输入到非线性激活函数中。
x x x是输入, W H W_H WH是权重。
仿射变换:线性变换+平移
如果此时将该值输入到非线性激活函数然后继续传递到下一层,就是普通的前馈网络。
而高速网络引入了一个门 T ( x ) = σ ( W T T x + b T ) T(x)=\sigma(W^T_T x + b_T) T(x)=σ(WTTx+bT),与LSTM中的门一样,经过Sigmoid函数将输出压缩到 [ 0 , 1 ] [0,1] [0,1]之间。
引入了
T
T
T之后,上式
y
y
y的计算方式变成了:
y
=
H
(
x
,
W
H
)
⋅
T
(
x
,
W
T
)
+
x
⋅
(
1
−
T
(
x
,
W
T
)
)
y = H(x, W_H) \cdot T(x,W_T) + x \cdot (1 - T(x,W_T))
y=H(x,WH)⋅T(x,WT)+x⋅(1−T(x,WT))
使用高速网络,可以让模型学习到在遇到未登录词的时候,抑制GloVe的输出,而增强CNN的输出。
上下文嵌入层(Contexual Embedding Layer)
使用来自周围单词的上下文来改善单词的嵌入。前三层同时应用于查询和上下文。
使用LSTM在第二层提供的词嵌入之上来模拟单词之间的时间交互。这里使用了双向LSTM,同时拼接了两个方向上的输出。因此,我们基于下文词向量 X X X上得到 H ∈ R 2 d × T H \in \Bbb{R}^{2d \times T} H∈R2d×T,基于问题词向量 Q Q Q得到了 U ∈ R 2 d × J U \in R^{2d \times J} U∈R2d×J。
这里的 2 d 2d 2d是拼接两个方向上的输出得来的。
值得一提的是,模型的前三层是基于查询和上下文从不同层级、不同粒度计算特征表示,类似于计算机视觉领域中卷积网络多阶段特征计算。
注意力流层(Attention Flow Layer)
融合查询和上下文向量,并为上下文中的每个单词生成一组查询感知特征向量。
注意力流层负责连接并融合上下文和查询中单词的信息,注意力流层并没有将查询和上下文编码到单个特征向量中,而是在每个时间步,和来自前一层的嵌入向量,都可以流向后续的建模层。这减少了由于过早压缩导致的信息丢失。
该层的输入是下上文 H H H和查询 U U U的向量表示。该层的输出是上下文单词 G G G的查询感知的向量表示,以及来自前一层的嵌入向量。
在本层中,我们以两个方向计算注意力:从上下文到查询以及从查询到上下文。这些注意力都是由上下文嵌入向量
H
H
H和查询嵌入向量
U
U
U计算的共享相似矩阵
S
∈
R
T
×
J
S \in \Bbb{R}^{T \times J}
S∈RT×J计算而来的。其中
S
t
j
S_{tj}
Stj表示第
t
t
t个上下文单词和第
j
j
j个查询单词之间的相似度。相似度矩阵计算公式为:
S
t
j
=
α
(
H
:
t
,
U
:
j
)
∈
R
S_{tj} = \alpha(H_{:t},U_{:j}) \in \Bbb{R}
Stj=α(H:t,U:j)∈R
其中
α
\alpha
α是可学习的基于两个输入向量的编码函数;
H
:
t
H_{:t}
H:t是
H
H
H的第
t
t
t列向量;
U
:
j
U_{:j}
U:j是
U
U
U的第
j
j
j列向量。
作者选择的函数 α ( h , u ) = w ( S ) T [ h ; u ; h ∘ u ] \alpha(h,u)=w^T_{(S)}[h;u;h \circ u] α(h,u)=w(S)T[h;u;h∘u],其中 w ( S ) ) ∈ R 6 d w_{(S)}) \in \Bbb{R}^{6d} w(S))∈R6d是可训练的权重向量, ∘ \circ ∘是元素相乘; [ ; ] [;] [;]是沿着行的向量拼接。这里 h = H : t ∈ R 2 d × 1 h=H_{:t} \in \Bbb{R}^{2d \times 1} h=H:t∈R2d×1; u = U : j ∈ R 2 d × 1 u=U_{:j} \in \Bbb{R}^{2d \times 1} u=U:j∈R2d×1; [ h ; u ; h ∘ u ] ∈ R 6 d × 1 [h;u;h\circ u] \in \Bbb{R}^{6d \times 1} [h;u;h∘u]∈R6d×1,与 w ( S ) T w_{(S)}^T w(S)T相乘刚好得到一个标量。
我们就可以使用 S S S来计算两个方向上的注意力。
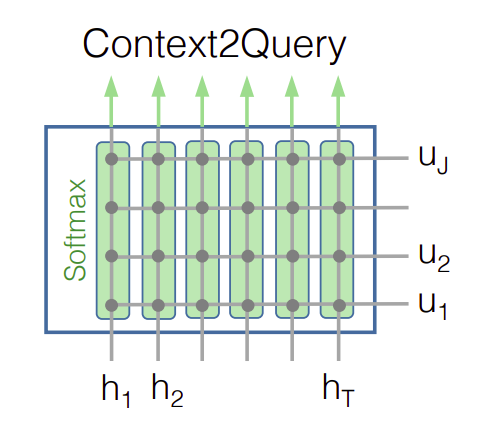
上下文到查询注意力(Context-to-query Attention, C2Q) C2Q注意力代表对于每个上下文单词,哪个查询单词与之最相关。令 a t ∈ R J a_t \in \Bbb{R}^J at∈RJ表示第 t t t个上下文单词上所有查询单词的注意力权重, ∑ j a t j = 1 \sum_{j}a_{tj}=1 ∑jatj=1。注意力权重计算为: a t = softmax ( S t : ) ∈ R J a_t =\text{softmax}(S_{t:}) \in \Bbb{R}^J at=softmax(St:)∈RJ,接着用 a t a_t at与 U U U计算加权和,得到注意的查询向量 U ~ : t = ∑ j a t j U : j \tilde U_{:t} =\sum_j a_{tj} U_{:j} U~:t=∑jatjU:j。因此 U ~ \tilde U U~是一个 2 d × T 2d \times T 2d×T的矩阵,包含整个上下文的注意的查询向量,我们相当于把查询信息融入到上下文当中了。
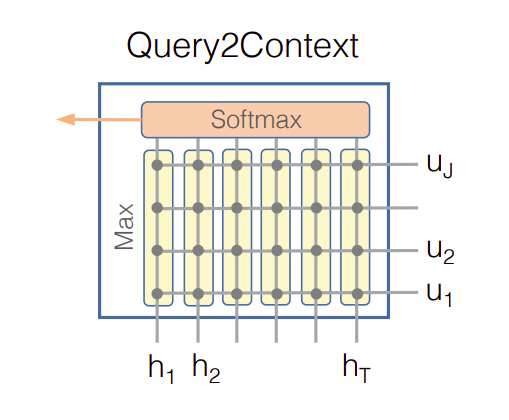
查询到上下文注意力(Query-to-context Attention,Q2C) Q2C注意力代表哪个上下文单词与某个查询单词最相关,然后对回答查询(问题)最重要。我们基于上下文单词获得注意力权重为 b = softmax ( max c o l ( S ) ) ∈ R T b= \text{softmax}(\max_{col}(S)) \in \Bbb R^{T} b=softmax(maxcol(S))∈RT,其中 max c o l \max_{col} maxcol是沿着 S S S矩阵列的方向计算最大值。然后注意的上下文向量是 h ~ = ∑ t b t H : t ∈ R 2 d \tilde h=\sum_t b_t H_{:t} \in \Bbb{R}^{2d} h~=∑tbtH:t∈R2d。该向量表示上下文中与查询相关的最重要单词的加权和。 h ~ \tilde h h~沿着列复制 T T T次,得到 H ~ ∈ R 2 d × T \tilde H \in \Bbb{R}^{2d \times T} H~∈R2d×T。
最终,上下文嵌入向量和注意力权重结合生成
G
G
G,其中每列向量可以看成每个上下文单词查询感知的表示。我们定义
G
G
G为:
G
:
t
=
β
(
H
:
t
,
U
~
:
t
,
H
~
:
t
)
∈
R
d
G
G_{:t} = \beta(H_{:t},\tilde U_{:t},\tilde H_{:t}) \in \Bbb{R}^{d_G}
G:t=β(H:t,U~:t,H~:t)∈RdG
其中
G
:
t
G_{:t}
G:t是第
t
t
t列向量(对应第
t
t
t个上下文单词),
β
\beta
β是可学习的向量函数,融合了它的三个输入向量,
d
G
d_G
dG是
β
\beta
β函数的输出维度。尽管
β
\beta
β函数可以用任意的神经网络,比如多层感知机,但如下这种简单的拼接仍然可得到好的表现:
β
(
h
,
u
~
,
h
~
)
=
[
h
;
u
~
;
h
∘
u
~
;
h
∘
h
~
]
∈
R
8
d
×
T
\beta(h,\tilde u, \tilde h) = [h;\tilde u;h \circ \tilde u;h \circ \tilde h] \in \Bbb{R}^{8d \times T}
β(h,u~,h~)=[h;u~;h∘u~;h∘h~]∈R8d×T
这里
d
G
=
8
d
d_G=8d
dG=8d
建模层(Modeling Layer)
应用一个RNN来提取上下文中的信息。
输入到建模层的是 G G G,它编码了上下文单词查询感知的表示。该层的输出捕获了基于查询的上下文单词之间的交互。这与上下文嵌入层不同,上下文嵌入层捕获的是独立于查询的上下文单词之间的交互。这里使用了两层双向LSTM,每个方向上的输出大小为 d d d。因此我们得到了一个矩阵 M ∈ 2 d × T M \in \Bbb{2d \times T} M∈2d×T,它会传递到输出层去预测答案。
M的每个列向量包含关于关于整个上下文和查询信息的上下文信息表示。
输出层(Output Layer)
生成基于查询的答案。
输出层是应用相关的。BiDAF 的模块化特性允许我们轻松地基于任务改变输出层,而保存其他层不变。这和现在的BERT有点像了。
这里我们以问答任务为例来描述输出层,问答任务需要模型从文章中找到一个连续的片段来回答问题,通过预测答案的开始和结束位置来从文章中抽取答案。我们通过一下公式在整个文章上计算开始位置的概率分布:
p
1
=
softmax
(
w
(
p
1
)
T
[
G
;
M
]
)
p^1 = \text{softmax}(w^T_{(p^1)}[G;M])
p1=softmax(w(p1)T[G;M])
其中
w
(
p
1
)
∈
R
10
d
w_{(p^1)} \in \Bbb{R}^{10d}
w(p1)∈R10d是可训练的权重向量。对于答案的结束位置,我们将
M
M
M传递到另一个双向LSTM以得到
M
2
∈
R
2
d
×
T
M^2 \in \Bbb{R}^{2d \times T}
M2∈R2d×T。然后以类似的方式用
M
2
M^2
M2来获得结束位置的概率分布:
p
2
=
softmax
(
w
(
p
2
)
T
[
G
;
M
2
]
)
p^2 = \text{softmax}(w^T_{(p^2)}[G;M^2])
p2=softmax(w(p2)T[G;M2])
训练 定义训练损失为预测分布对应的真实开始和结束位置的负对数似然的之和,并求所有样本上的均值:
L
(
θ
)
=
−
1
N
∑
i
N
log
(
p
y
i
1
1
)
+
log
(
p
y
i
2
2
)
L(\theta) = -\frac{1}{N} \sum_i ^N \log(p^1_{y^1_i}) + \log(p^2_{y_i^2})
L(θ)=−N1i∑Nlog(pyi11)+log(pyi22)
其中
θ
\theta
θ是模型的可训练权重参数集合,
N
N
N是数据集的样本总数,
y
i
1
y^1_i
yi1和
y
i
2
y_i^2
yi2是第
i
i
i个样本的真实开始和结束位置,
p
k
p_k
pk表示向量
p
p
p的第
k
k
k个值。
测试 答案片段 ( k , l ) (k,l) (k,l),其中 k ≤ l k \leq l k≤l,是最大的 p k 1 p l 2 p_k^1p_l^2 pk1pl2,可以用动态规划以线性时间计算出来。

