
- 1智能可视采耳棒耳勺安全吗?揭露六大隐患套路!
- 2R语言使用lm函数构建多元回归模型(Multiple Linear Regression)、使用step函数筛选最合适的回归变量(逐步回归筛选预测变量的最佳子集)_step(lmer
- 3SpringBoot+Vue停车场管理系统的设计与实现(文档+源码)_springboot整合vue停车场管理系统的静态资源以及模板
- 4Linux常用命令整理(适合初学)_linux常用命令大全新手入门
- 5php 时间日期转为时间戳,PHP日期格式转时间戳
- 6从Docker拉取镜像一直失败超时?这些解决方案帮你解决烦恼_docker拉取镜像超时
- 7图像特征提取之--PCA方法_pca图像特征提取实例
- 8两篇 CVPR 2024最佳学生论文|7月26日开讲
- 92024年第十五届蓝桥杯C/C++大学B组题 C传送阵_蓝桥杯2024年第十五届省赛真题-传送阵
- 10都说测试行业饱和了,为啥我们公司给初级测试还能开到了12K?_游戏测试现在饱和吗
关于Mamba和Mamba-2经典论文的学习笔记总结,以及Mamba和Transformer的对比总结,欢迎交流_mamba2论文
赞
踩
1.第一部分 Mamba的提出背景与结构原理
1.1 研究背景和摘要:
翻译过来的意思是:基础模型目前为深度学习中大多数令人兴奋的应用提供动力,它们几乎都基于Transformer 架构及其核心注意力模块。许多亚二次方程时间架构,如线性注意、门控卷积和递归模型,以及结构化状态空间模型(SSM)、门控卷积和递归模型,以及结构化状态空间模型(SSM)等许多亚四元时间架构都是为了解决变压器在长序列上的计算效率低下问题,但它们在语言等重要模态上的表现不如注意力好。但它们在语言等重要模态上的表现并不尽如人意。我们发现,这些模型的一个关键弱点是无法进行基于内容的推理,并做出了几项改进。首先,只需让 SSM 参数成为输入的函数,就能解决它们在离散模态下的弱点。首先,只需让 SSM 参数成为输入的函数,就能解决它们在离散模态方面的弱点,使模型能根据当前标记的长度维度,有选择地传播或遗忘信息。序列长度维度传播或遗忘信息。其次,尽管这种变化妨碍了使用高效的卷积,我们还是设计了一种硬件感知的并行递归模式算法。我们将这些选择性 SSM 集成到一个简化的端到端神经网络中。我们将这些选择性 SSM 集成到一个简化的端到端神经网络架构中,该架构无需关注,甚至无需 MLP 块(Mamba)。Mamba推理速度快(吞吐量比 Transformers 高 5 倍),序列长度呈线性扩展,其性能在百万长度的真实数据上得到了提高。在真实数据上的性能提高了一百万长度的序列。作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模式中实现了最先进的性能。在语言建模方面,我们的 Mamba-3B 模型在语言建模方面,我们的 Mamba-3B 模型在预训练和下游评估中均优于同等规模的 Transformers,并可与两倍于其规模的 Transformers 相媲美。
1.2 回顾Transformer
既然摘要中明确的和Transformer做出了对比,那么这里我们不妨先回顾一下Transformer,作为CV领域的“大红人”,为图像处理质量的提升做出了非常大贡献,经典原文:Attention Is All You Need 原文链接:1706.03762 (arxiv.org)
Transformer是一种深度学习模型架构,它在自然语言处理(NLP)和其他序列建模任务中取得了革命性的成功。Transformer模型的几个关键特点:
-
自注意力机制(Self-Attention):Transformer模型的核心是自注意力机制,它允许模型在处理序列的每个元素时,考虑序列中所有位置的信息。这种机制使得模型能够捕捉到序列内部的长距离依赖关系。
-
并行化处理:由于自注意力机制不依赖于序列中元素的顺序,Transformer可以并行处理整个序列,这与传统的循环神经网络(RNN)形成对比,后者需要按顺序逐步处理序列。
-
可扩展性:Transformer模型的设计允许它很容易地扩展到更大的模型尺寸和更长的序列长度,这使得它能够处理复杂的任务和大量的数据。
-
编码器-解码器架构:在典型的Transformer模型中,包含编码器(Encoder)和解码器(Decoder)两个部分。编码器处理输入序列,而解码器生成输出序列。两者之间通过注意力机制进行交互。
-
位置编码:Transformer模型通过添加位置编码来使模型能够理解序列中单词的顺序。位置编码通常是与时间步长的正弦和余弦函数相关的固定向量。
-
多头注意力:Transformer模型使用多头注意力机制,它允许模型同时从不同的角度和抽象层次捕捉序列的信息。
-
层归一化和残差连接:Transformer模型在每个子层中使用层归一化(Layer Normalization)来稳定训练过程,并通过残差连接(Residual Connections)来帮助梯度流动,从而缓解深度网络中的梯度消失问题。
-
预训练和微调:Transformer模型通常在大量数据上进行预训练,学习通用的语言表示,然后可以在特定任务上进行微调,以提高任务性能。
Transformer的结构:
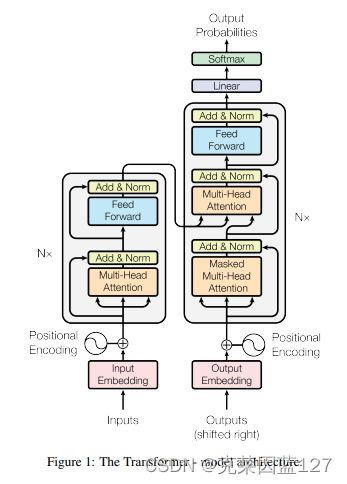

1.3 状态空间模型SSMs(State Space Models,简称SSMs)
继续回归主题:好好好,重点“可与Transformer相媲美”,看来功能确实强大,那我们来看看这个mamba具体结构是怎么样的:
首先提到Mamba,就必须要提及状态空间模型(State Space Models,简称SSMs)
SSMs是一种用于序列建模的深度学习架构。SSMs可以被视为循环神经网络(RNNs)和卷积神经网络(CNNs)的结合体,它们从经典的状态空间模型中获得灵感。SSMs能够有效地以线性或接近线性的复杂度处理序列数据,并且能够模拟某些数据模态中的长期依赖关系。
再来看一下SSMs的结构:

SSMs概述:结构化的ssm独立地映射输入
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

