
- 1【Python】nltk库使用报错之punkt安装_nltk punkt
- 2超简单的Unity AR新手教程|五分钟上手_unity ar开发教程
- 3【安卓-自定义布局】安卓App开发思路 一步一个脚印(十)实现内嵌在app中的webview 腾讯开源X5 高效安全_安卓app webview模板
- 4专业140+总分420+天津大学815信号与系统考研经验天大电子信息与通信工程,真题,大纲,参考书。
- 5react router
- 6数据结构之----栈、队列、双向队列_先入后出的线性结构是
- 7linux 服务器进程、端口查找,nginx 配置日志查找,lsof 命令详解_linux查看nginx端口
- 8Java开源B2B2C商城搭建(H5+app+多端)_java b2b2c
- 9速盾:高防cdn和普通cdn的区别?
- 10每日一题python88:回文链表_判断回文链表python
数据结构(十三)二叉树—— 哈夫曼树和哈夫曼编码译码器_如何将哈弗曼编码组成的密文翻译成明文
赞
踩
哈夫曼树是二叉树的一种经典应用,哈夫曼树和哈夫曼编码经常搭配使用,用来创建一篇文章对应的加密编码,并且能够对这篇
文章进行加密和解密,通过哈夫曼编码加密后的文章完全通过01构成,并且每一篇文章因为内容的不同,即使是相同的字符所对应的的哈夫曼编码也是不同的,所以,既是单纯的得到一篇文章的密文结构,没有得到对应的哈夫曼编码表,也是无法进行解密的。所以哈夫曼树和哈夫曼编码在密码学当中具有非常高的学术研究价值。
一、前缀编码和非前缀编码
在学习哈夫曼树和哈夫曼编码之前,我们先来学习一下什么是前缀编码和非前缀编码
前缀编码:如果一个字符的加密编码有可能出现在其他字符的加密编码的前面,那么这一整套编码结构就称之为前缀编码
举个例子:加入字符a的编码是10,字符b的编码是1000,那么我们称字符a的编码是字符b的编码的前缀编码。前缀编码在解密过程中很可能出现歧义,比如以上面ab的编码为例,字符串ba的编码结果为:100010,但是在解密过程中,我们既可以把这个密文解密为ba,也可以解密为a00a,那么这样就产生了歧义。
非前缀编码:与前缀编码相反的是,非前缀编码指的就是在编码集中,任意两个字符的编码之间都不可能产生前缀编码的情况
也就是说,如果使用非前缀编码的话,在解密过程中是不可能出现歧义的
二、构建哈夫曼树
对一篇文章构建哈夫曼树的过程如如下:
步骤1:首先将这个文章当成一个字符串,遍历这个字符串中所有的字符,并且统计每一个字符出现的次数;
步骤2:根据字符出现的次数对字符进行排序;
步骤3:选取排序后出现次数最少的两个字符加入哈夫曼树,并将两个字符的出现次数取值相加,合并成为一个中间节点中间节点仅记录两个节点取值的加和,但是不记录任何字符;
步骤4:将中间节点加入字符排序序列中,删除已经使用过的节点,对序列重新排序,重复步骤2-4,构建过程中贺词能够产生的 中间节点也算作在内
步骤5:当所有的字符和中间节点全部合成完毕时,序列中只剩余一个节点,就是哈夫曼树的根节点,哈夫曼树创建完毕。
哈夫曼树的构建过程如下图所示:
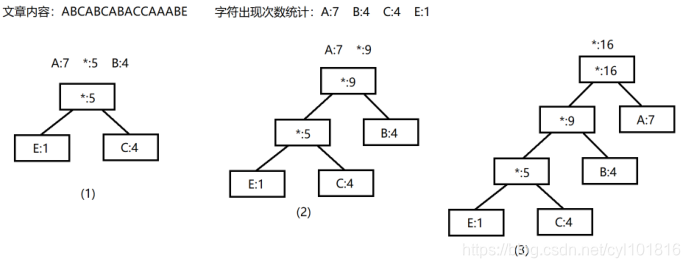
从哈夫曼树的构建过程我们不难看出如下规律:
1.哈夫曼树的构建过程是自底向上的;
2.在一个哈夫曼树中所有具有实际意义的字符,最终一定会存在于叶子结点中。上述这两个步骤也为我们后面生成非前缀的哈夫曼编码打下了基础。
三、构建字符哈夫曼编码
在上面创建的哈夫曼树的基础上,来为每一个存储字符的节点分配哈夫曼编码每一个字符节点创建哈夫曼编码的过程如下:
步骤1:从根节点开始,向下寻找每一个叶子节点;
步骤2:如果向左孩子方向走一步,则记0;
步骤3:如果向右孩子方向走一步,则记1;
步骤4:重复上面步骤2-3,直到遍历完成整个哈夫曼树为止,最终得到根节点通往每一个叶子节点的路径字符串,就是这个叶子节点对应字符的哈夫曼编码。
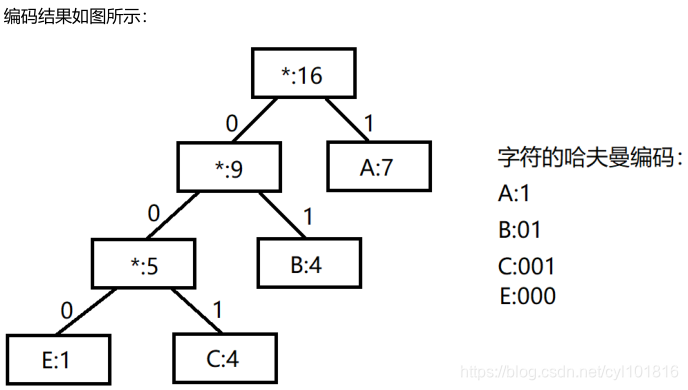
从上图不难看出:文章中出现的任何字符的编码,都不会过程其他字符编码的前缀编码
四、文本内容的加密
加密的过程,就是将文章中所有的字符使用其对应的哈夫曼编码进行替换的过程。
如上文图中提供的字符串,最终的编码结果为:101001101001101100100111101000
五、加密内容的加密
密文解密的时候,必须同时得到密文和所有字符对应的哈夫曼编码表两部分内容。因为每一个文章中,即使是相同的字符,出现的次数也有可能是不相同的所以只要是通过不同文章得到的哈夫曼编码表之间也是不通用的
解密过程步骤如下:
步骤1:顺序取得密文的一个字符,在编码表中比对,有没有这个密文对应的密码字符串;
步骤2:如果没有,则在保留当前密文字符的基础上,获取下一位密文并拼接到这一位密文的后面;
步骤3:重复步骤1-2,直到能够在编码表中找到对应的密文字符串,使用编码表中的密文字符串对应的明文替换这一段密文;
步骤4:重复步骤1-4,直到密文中所有的内容被翻译成为明文为止。
上述步骤如下图所示:

六、代码实现
- package com.oracle.huffmantree;
-
- import java.util.HashMap;
- import java.util.LinkedList;
- import java.util.List;
- import java.util.Map;
- import java.util.Map.Entry;
- import java.util.Set;
-
- public class HuffmanTree {
-
- public static class Node {
-
- public char data; //存储字符
- public int count; //存储字符出现的次数
-
- public Node leftChild; //左孩子指针域
- public Node rightChild; //右孩子指针域
-
- }
-
-
- /**
- * 创建哈夫曼树的方法
- * @param content 文章内容
- * @return 哈夫曼树的根节点
- */
- public Node createHuffmanTree(String content) {
-
- //[1]创建一个用来存储节点的集合,因为节点的增删比较频繁,所以我们使用LinkedList
- List<Node> nodeList = new LinkedList<>();
-
- //[2]遍历整个文章结构,统计每一个字符的出现次数,为了方便起见,统计过程中我们使用一个HashMap键值对记录每一个字符的出现次数
- HashMap<Character, Integer> countMap = new HashMap<>();
- char[] charArray = content.toCharArray(); //将字符串打碎成为字符数组
- for(int i = 0; i < charArray.length; i++) {
- if(countMap.containsKey(charArray[i])) { //如果这个字符已经在Map中存在,那么在这个字符已经出现次数的基础上+1
- int newCount = countMap.get(charArray[i]) + 1;
- countMap.put(charArray[i], newCount);
- }else { //如果这个字符尚未出现过,那么僵这个字符加入Map中,并且次数记为1
- countMap.put(charArray[i], 1);
- }
- }
-
- //[3]创建一个循环,将Map中的统计结果转换为哈夫曼树的节点,存储在节点集合中。存储过程使用插值添加,升序有序
- Set<Entry<Character, Integer>> entrySet = countMap.entrySet();
- for (Entry<Character, Integer> entry : entrySet) {
- Node node = new Node();
- node.data = entry.getKey();
- node.count = entry.getValue();
-
- addNode(nodeList, node);
- }
-
- //[4]创建一个循环,开始创建哈夫曼树
- while(nodeList.size() > 1) {
-
- //首先获取最小值和第二小的值,并且从节点列表中删除掉
- Node n1 = nodeList.get(0);
- nodeList.remove(0);
-
- Node n2 = nodeList.get(0);
- nodeList.remove(0);
-
- //将n1和n2节点的出现次数合并为一个数,并且创建一个中间节点
- Node tmp = new Node();
- tmp.count = n1.count + n2.count;
-
- tmp.leftChild = n1;
- tmp.rightChild = n2;
-
- //中间节点加入节点列表
- addNode(nodeList, tmp);
-
- }
-
- //[5]哈夫曼树创建完毕,最终节点列表中剩下的唯一一个节点就是哈夫曼树的根节点
- return nodeList.get(0);
-
- }
-
- /**
- * 将一个新的哈夫曼树节点以插值的方式加入节点列表中的方法
- * 添加之后的节点列表,按照字符的出现次数升序有序
- * @param nodeList 节点列表
- * @param node 新的哈夫曼树节点
- */
- private void addNode(List<Node> nodeList, Node node) {
-
- //如果是第一次向节点列表中添加节点,则不需要进行判断,直接添加即可
- if(nodeList.isEmpty()) {
- nodeList.add(node);
- return;
- }
-
- int i;
- for(i = 0; i < nodeList.size(); i++) {
- if(node.count > nodeList.get(i).count) {
- continue;
- }else {
- nodeList.add(i, node);
- break;
- }
- }
-
- if(i == nodeList.size()) {
- nodeList.add(node);
- }
-
- }
-
- /**
- * 创建哈夫曼编码表的方法
- * @param codeMap 存储每一个字符的哈夫曼编码的编码表
- * @param node 哈夫曼树中的一个节点
- * @param path 从根节点到达当前节点的路径,即字符的编码
- */
- public void createHuffmanCode(Map<Character, String> codeMap, Node node, String path) {
-
- //实际上创建哈夫曼编码表的过程就是一个深度优先递归遍历哈夫曼树的过程
- if(node.data != 0) { //如果当前节点不是一个中间节点
- codeMap.put(node.data, path); //那么在编码表中存储这个节点所记录字符对应的编码
- }
-
- if(node.leftChild != null) { //如果向左走一步,则路径添加0
- String leftPath = path + "0";
- createHuffmanCode(codeMap, node.leftChild, leftPath);
- }
-
- if(node.rightChild != null) { //如果向右走一步,则路径添加1
- String rightPath = path + "1";
- createHuffmanCode(codeMap, node.rightChild, rightPath);
- }
-
- }
-
- /**
- * 对明文进行加密的方法
- * @param content 加密之前的明文
- * @param codeMap 编码表
- * @return 加密之后的密文
- */
- public String encode(String content, Map<Character, String> codeMap) {
-
- String result = "";
-
- for(int i = 0; i < content.length(); i++) { //遍历整个文章字符串
- String charCode = codeMap.get(content.charAt(i)); //从密码表中获取当前字符对应的密码编码
- result += charCode; //拼接密码编码
- }
-
- return result;
-
- }
-
- /**
- * 催密文进行解密的方法
- * @param ciphertext 密文文本字符串
- * @param codeMap 编码表
- * @return 解密之后的内容
- */
- public String decode(String ciphertext, Map<Character, String> codeMap) {
-
- String result = "";
-
- //[1]首先将编码表中的键和值进行调换,调换结果的Map中,键是密码,值是字符,这样方便后序解码操作
- Map<String, Character> newCodeMap = new HashMap<>();
- Set<Entry<Character, String>> entrySet = codeMap.entrySet();
- for (Entry<Character, String> entry : entrySet) {
- newCodeMap.put(entry.getValue(), entry.getKey());
- }
-
- //[2]遍历密文字符串,进行解码
- String tmp = ""; //用来临时存储部分密文字符串的临时变量
- for(int i = 0; i < ciphertext.length(); i++) {
- tmp += ciphertext.charAt(i);
- if(newCodeMap.containsKey(tmp)) {
- result += newCodeMap.get(tmp);
- tmp = "";
- }else {
- continue;
- }
- }
-
- return result;
-
- }
-
- }

- package com.oracle.huffmantree;
-
- import java.util.HashMap;
- import java.util.Map;
-
- public class TestHuffmanTree {
-
- public static void main(String[] args) {
-
- HuffmanTree ht = new HuffmanTree();
- String content = "ABCABCABACCAAABE";
-
- HuffmanTree.Node root = ht.createHuffmanTree(content);
-
- Map<Character, String> codeMap = new HashMap<>();
- ht.createHuffmanCode(codeMap, root, "");
-
- System.out.println("哈夫曼编码表:");
- System.out.println(codeMap);
-
- System.out.println("加密结果:");
- String ciphertext = ht.encode(content, codeMap);
- System.out.println(ciphertext);
-
- System.out.println("解密结果:");
- String result = ht.decode(ciphertext, codeMap);
- System.out.println(result);
-
- }
-
- }
结果如下:


