
- 1机器人轨迹规划
- 2Tensorflow神经网络训练(Nan)问题实践分析_tensorflow训练神经网络loss: nan
- 3Android基于讯飞AIUI的聊天Demo_aiui 语音案例 android
- 4原创《基于深度特征学习的细粒度图像分类研究综述》_ma-cnn
- 5[ C++ ] STL---list的模拟实现
- 6【深度学习实战】一、Numpy手撸神经网络实现线性回归_def update(self,x,y,grad_step): y_pred=self.predic
- 7ai写作一键生成,分享6种好用的写作软件,一定要看
- 8Vite 脚手架 搭建 Vue项目_vite脚手架
- 9SpringBoot Gradle 项目创建_springboot gradle项目创建
- 10数组清空函数memset使用方法_memset清空数组
ICCV 2023 | 基于预训练视觉语言模型和大语言模型的零样本图像到文本生成
赞
踩

©作者 | Elysia
单位 | 南科大VIP Lab
和大家分享一下我们组 ICCV 2023 中稿的零样本图像-文本(I2T)生成工作 ViECap。该任务目前的一个主流做法是结合预训练的视觉语言模型(VLMs)和大语言模型(LLMs)来完成 I2T 的生成,然而我们发现在微调 VLMs 和 LLMs 以结合这两个预训练模型时,目前的方法至少存在两个问题:
1. 模态偏置,即在文本生成的过程中,来自 LLMs 的语言先验会占据生成过程的主导地位,这是由于通常情况下 LLMs 的能力更强,且来自视觉的指导的强度弱导致的。
2. 物体混淆,即这些在大量数据上进行过预训练的大模型的泛化能力将会退化到指定的微调数据集,从而导致 I2T 模型生成的文本中出现图像中并不存在的物体(而该物体在微调数据集中非常常见)。
该工作通过实验进一步验证了这两个问题,并基于此提出了 ViECap。不使用任何图像-文本对,ViECap 在多个 I2T 任务上表现出了 SOTA 的迁移性(跨数据集测试,NoCaps),并能够生成用户期望风格的文本(幽默,浪漫)。

论文标题:
Transferable Decoding with Visual Entities for Zero-Shot Image Captioning
论文链接:
https://arxiv.org/abs/2307.16525
代码链接:
https://github.com/FeiElysia/ViECap

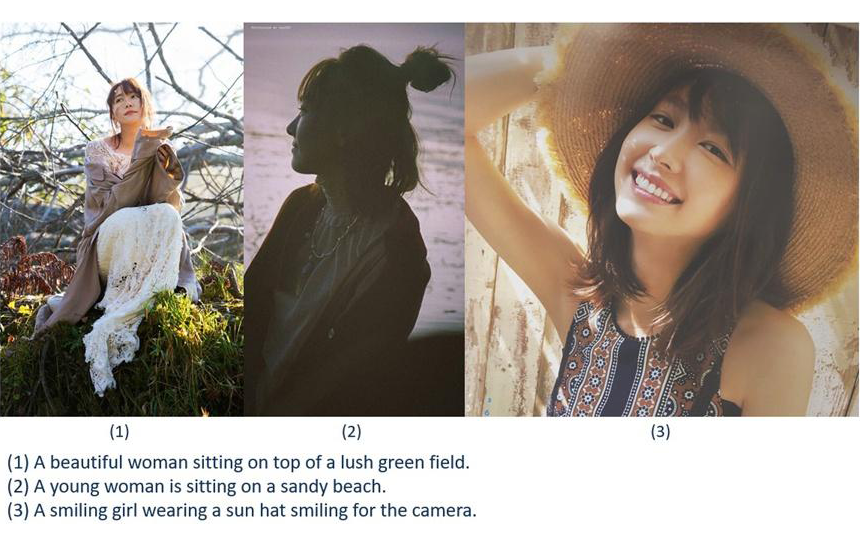
效果展示


任务介绍
零样本图像-文本(I2T)生成任务的主要目的是使模型没有事先在特定的图像-文本对上进行训练的情况下,能够生成与给定图像相关的文本描述。即在模型看到新的图像时(训练时没见过的新物体,训练时没见过的新图像分布),能够根据模型存储的世界知识生成合理的、与图像内容相关的描述。
该任务可以测试模型的泛化能力,即模型能否将训练时学到的知识应用到未见过的图像领域,以生成图像相关的文本描述;该任务允许模型在没有经过特定领域的图像-文本数据训练的情况下,为多种不同类型的图像生成文本描述;该任务可以避免为不同领域收集和标注大量的图像-文本对,从而降低了数据收集和标注的成本。

研究背景和动机
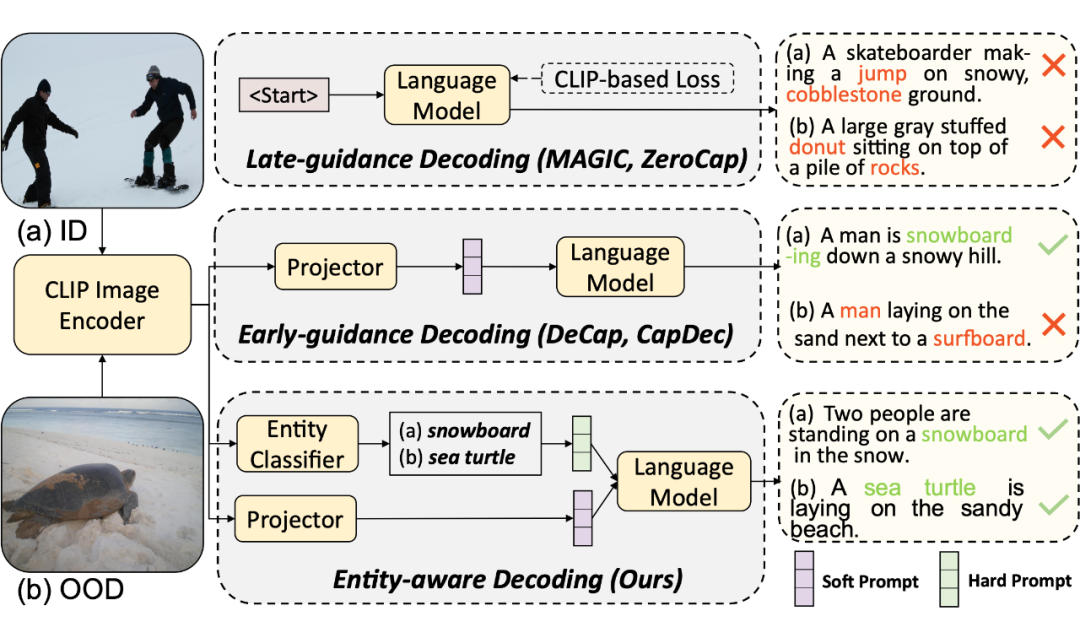
I2T 任务是一个重要的视觉感知任务。传统的 I2T生成方法需要通过在大量的图像-文本对上进行训练以获得感知图像、与文本对齐并生成文本的能力。最近,VLMs 取得了重要进展,在大量带噪的图像-文本对上进行预训练的 CLIP 具备良好的图像感知能力,并能很好的对齐配对的图像和文本。最近一些工作尝试结合 CLIP 和 LLMs 来完成零样本 I2T 生成任务。为了达到这个目的,需要将 CLIP 的输出特征对齐到 LLMs 的隐空间上。
当前有两种方法解决这个问题:
(1)late-guidance的范式在语言模型完成单词预测后再注入视觉信息(如语言模型完成单词预测后使用 CLIP 计算图像-文本相似度来选择单词),这会导致在解码过程中语言模型具备的语言先验占据主导地位(模态偏置),如上图所示,“jump” 虽然与图像无关,但是其与“skateboarder”一起出现的频率较高,进而在预测中出现了这个单词。
(2)early-guidance 的范式通过微调预训练模型来显式的指导文本生成过程,这种方式可以极大的缓解模态偏置的问题。但是,在一个小的数据集上微调预训练模型通常会导致模型产生物体混淆,即在描述图像时,经常生成图像中并不存在的物体(这个物体可能频繁出现在训练集中)。如上图所示,在 COCO 数据集上进行微调的 I2T 模型,因为没有见过海龟这个概念,当来了一张海龟的图时,模型把海龟误认为 “surfboard”(surfboard 在 COCO 数据集里非常常见)。

进一步的验证
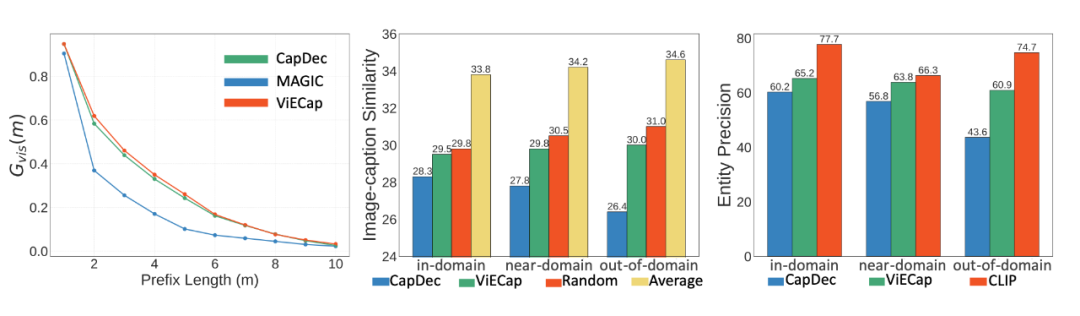
为了进一步验证在利用预训练大模型来实现零样本 I2T 生成任务时存在的模态偏置和物体混淆,我们巧妙的设计几个实验。(1)一个优秀的 I2T 模型应该能够很好的平衡视觉指导和语言指导,为了验证来自视觉指导的强度,我们设计了如下解码策略。我们首先使用训练好的 I2T 模型来生成前 个单词,然后我们将生成的 个单词输入给一个预训练好的语言模型来生成最终的文本。我们将数据指导的强度表示为 :
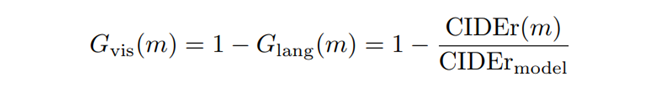
中,CIDErmodel 表示生成的文本完全由 I2T 模型控制(即 等于句子长度), 表示语言指导的重要性。当模型产生模态偏置(偏向于语言)时, 将会较小,因为此时只需要通过语言模型就能够预测文本。如上图所示(最左的图),late-guidance 方法 MAGIC 比起 early-guidance 的方法 CapDec 和我们提出的 ViECap 有一个更小的 ,这进一步证实了 late-guidance 方法存在的模态偏置。
Early-guidance 的方法容易产生物体混淆,为了验证这个假设,我们使用 NoCaps 数据集进行测试。NoCaps 包含三个子数据集:in-domain, near-domain, out-of-domain,用以测试 I2T 模型对于训练时未见过的新物体的描述能力。我们使用 CLIP 来计算图像与生成的文本之间的相似度,如上图所示(中间的图),当从 in-domain 迁移到 out-of-domain 时,CapDec 的性能逐渐下降,而我们提出的 ViECap 对于未见过的物体能够保证良好的迁移性。
因为物体混淆表示生成的文本中出现本身并不在图像中的物体,我们进一步分析了不同 I2T 模型生成的文本中是否能够准确包含图像中存在的物体,可以看到从 in-domain 的 I2T 生成到 out-of-domain 的 I2T 生成,CapDec从60.2 下降到了 43.6,产生了严重的物体混淆。

方法介绍
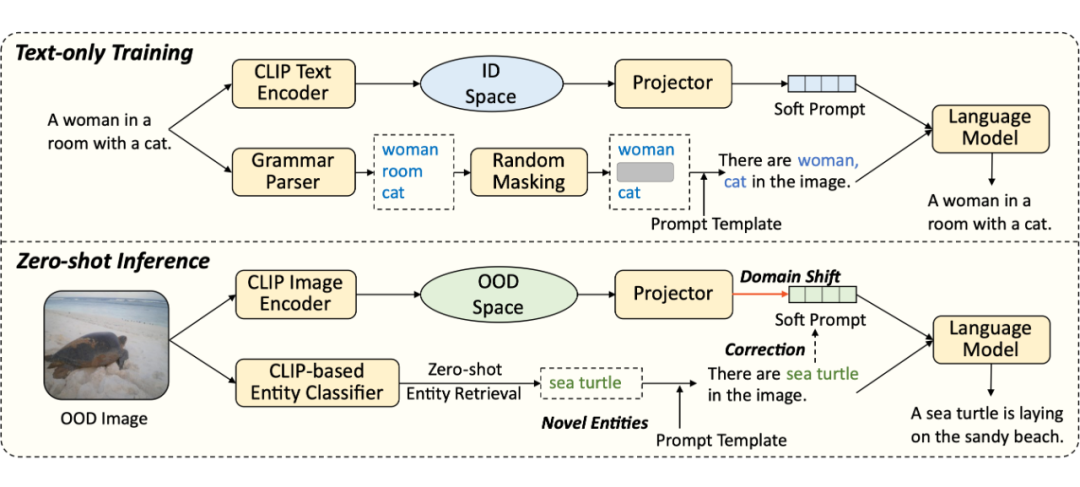
为了避免为不同领域收集和标注大量的图像-文本对,我们只使用文本数据来微调 I2T 模型。具体来说,我们的目标是训练一个解码器,使其在解码的过程中能够更多的去关注到图像中的物体,进而实现良好迁移性。为了达到这个目的,我们构建两种类型的 prompt。
(1)entity-aware hard prompt,训练时,我们通过 NLTK 将文本中的名词提取出来当作从图像中检测得到的物体(即 ),并将之插入到一个 prompt 模板中形成 “There are in the image.” 来构建 entity-aware hard prompt。我们发现简单的使用所有提取得到的名词插入 prompt 会导致 I2T 模型学会一个捷径,即将 hard prompt 中的所有物体直接复制到生成的文本中。
为了规避这种现象,我们提出对每个提取的名词,都按照一定的概率对其进行 mask(即每个提取的名词都有可能不会插入到 prompt 中)。推理时,我们使用冻结的 CLIP 来检测图像中的 ,这样构建的 hard prompt 是训练无关的,不会受到微调数据集的影响,其能够继承 CLIP 的零样本迁移能力。通过这种方式构建 entity-aware hard prompt 的目的是为了使模型在解码过程中能够更多的关注图像中的物体。
(2)soft prompt,训练时,我们只使用文本数据以避免针对不同领域收集和标注大量的图像-文本对,我们使用 CLIP 的文本编码器将文本投射到 CLIP 的特征空间,并给该文本表征添加一个随机高斯噪声使得文本表征尽可能能够表示图像特征(该做法来自 CapDec),然后将之输入给一个可学习的 Transformer 来将该文本表征投射到 GPT-2 的隐空间。
推理时,我们直接使用 CLIP 的图像编码器来将图像投射到 CLIP 的特征空间并直接使用训练过的 Transformer 将之投射到 GPT-2 的隐空间来构建 soft prompt。值得一提的是,在输入 GPT-2 之前,还需要将构建得到的 entity-aware hard prompt 和 soft prompt 在序列维度级联起来,一起输入 GPT-2。

实验
为了验证 ViECap 描述图像中出现的新物体的能力,我们在 NoCaps 数据集上进行测试。具体来说,我们在 COCO 的文本数据上训练 ViECap,然后直接在 NoCaps 上进行验证。如下表所示,对比其他不使用图像-文本对进行训练的方法(DeCap,CapDec),ViECap 在描述新物体时,能够生成更加合理且符合图像的描述。
从 in-domain 到 out-of-domain,DeCap 和 CapDec 的 CIDEr 下降了接近 35,而 ViECap 的 CIDEr 并没有下降,这证明 ViECap 对于新分布的图像具有更强的迁移性。为了进一步的测试 ViECap 的迁移性,我们还在跨数据集的设定下进行了测试(即在一个数据集上进行训练,不进行任何微调,直接在另一个数据集上进行测试),可以看到 ViECap 在大部分文本生成质量的指标上依然能够达到 SOTA 的迁移性。
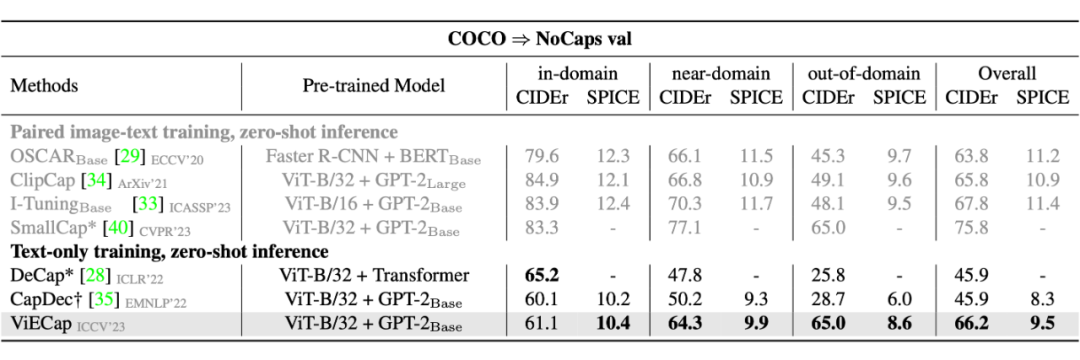
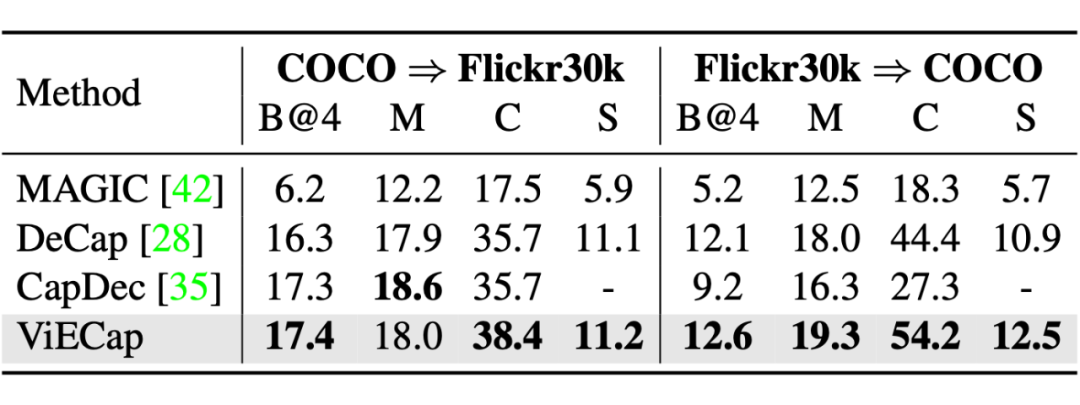
除此之外,我们还在通用的 I2T 数据集 COCO 和 Flickr30k 上测试了 ViECap 的性能,我们分别在这两个数据集的训练集上进行了微调然后再测试集上进行测试。
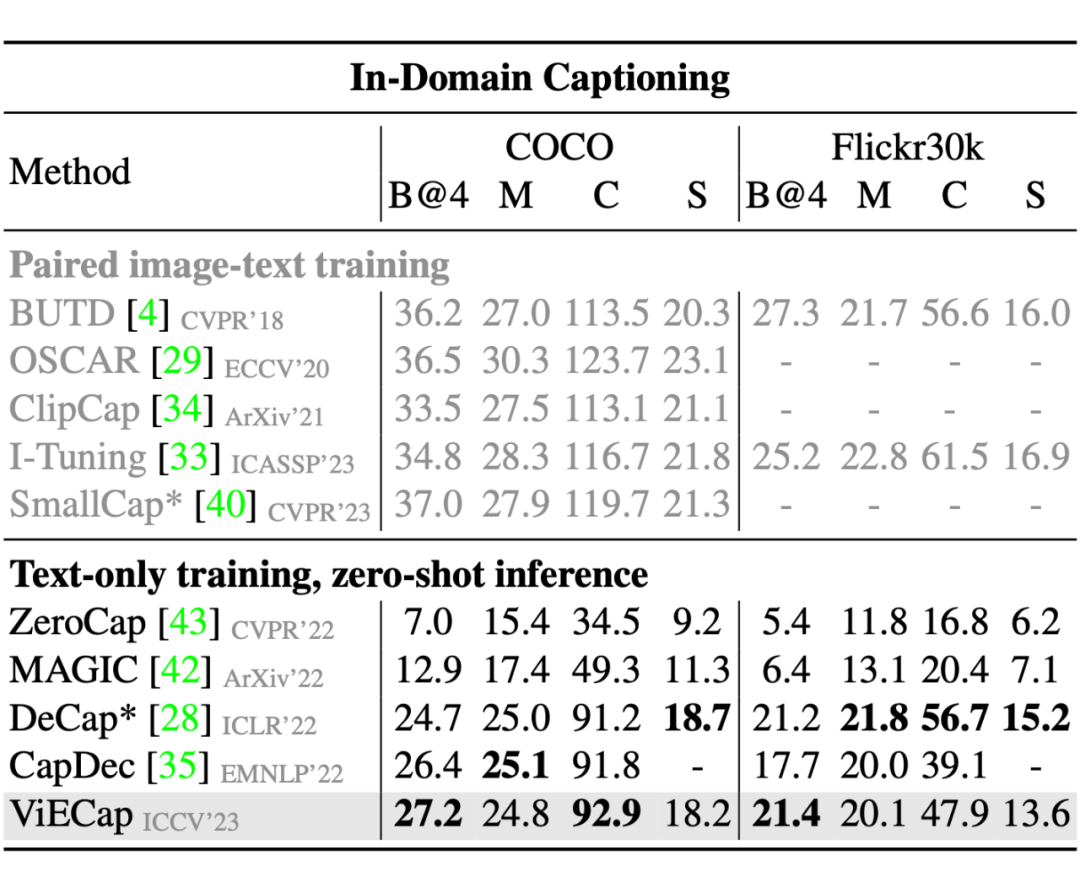
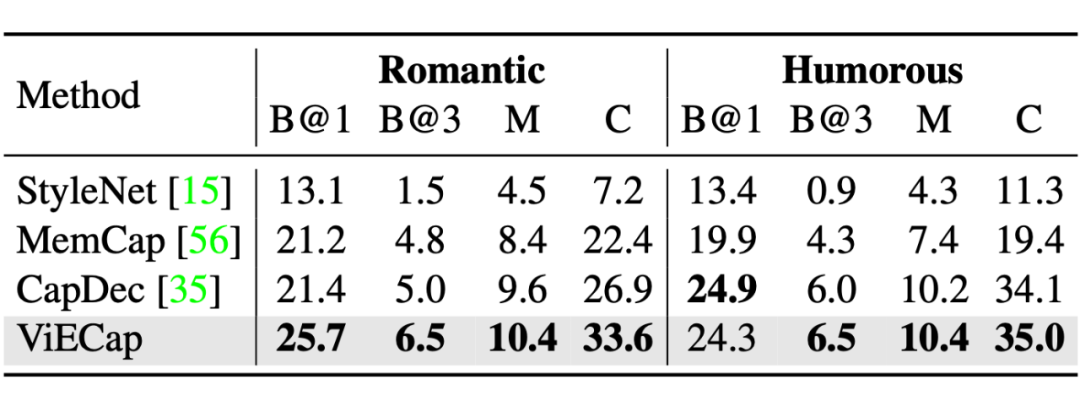
由下表可以看到,ViECap 在保持良好迁移性的同时,还能对训练时见过的概念保持优秀的描述能力。只用文本数据进行训练的一个优势是可以让生成的文本符合用户期望的风格,我们在 FlickrStyle10K 上测试了 ViECap,从结果可以看出 ViECap 能够生成符合用户期望风格的文本(即浪漫,幽默)并在文本生成质量上达到了 SOTA。
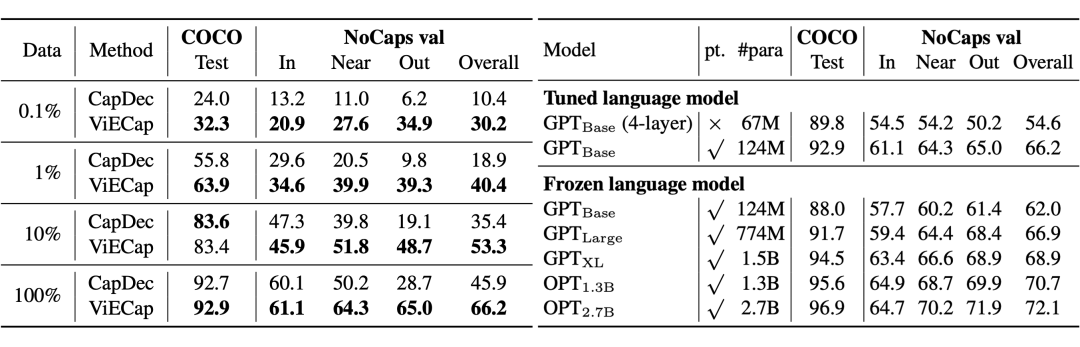
我们还探索了 ViECap 在低数据量情况下的性能,如下表所示,可以看到,在数据量较少的情况下,使用 ViECap是一个不错的选择。此外,我们还逐步增大 ViECap 中语言模型的规模(从 GPT-2 到 OPT),随着模型规模的增大,ViECap 的 I2T 生成性能逐渐变强,表格显示继续增大语言模型,没有看到显著上限!
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

