
- 1全网首发!Golang实现的Githack与原理详解_gitstats golang
- 2安卓/鸿蒙手机使用termux安装mariaDB,Centos搭载jdk,Tomcat制作个人移动版服务器_termux centos
- 3rabbitmq 工作模式(未完全版只demo)
- 4git配置ssh key_git配置sshkey
- 5NAIC2021-AI+视觉特征编码第一阶段开源方案
- 6自然语言处理(NLP)之三:语言模型_生成式语言模型文本特征
- 7使用 OpenCV 进行 YOLO 对象检测_opencv识别yolo模型
- 8【机器学习】:判别式模型与生成式模型_区分度训练是判别式模型吗
- 9Hadoop之“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform“问题解决办法
- 10Android SeekBar宽度填充全屏_android seekbar两端填满
Lora:Low-Rank Adapation of Large Language models_low-rank adaptation of large language models
赞
踩
Introduction
这篇论文最初与21.06上传与arXiv,作者指出在当时,NLP的一个重要范式是先训练一个通用领域的模型然后在通过微调适应不同的领域与数据,但是对于当时的大模型来说,是十分昂贵的,于是作者提出了一个叫Low-Rank- Adaptation的方法,也叫Lora,它冻结了Pre-Train model ,然后在Transformer的每一层注入了可训练的 rank decomposition matrices,作者指出与 用了Adam的GPT-3相比,需要更新的参数量少了10000倍,显存少了三倍,性能也有略微提升。
作者假设在微调时,Pre-train model的权重矩阵在过度更新参数时,它的权重矩阵的秩是很低的,于是作者的想法就是把 一些Dense layer的权重替换成低秩分解矩阵,然后作者发现效果也不错。
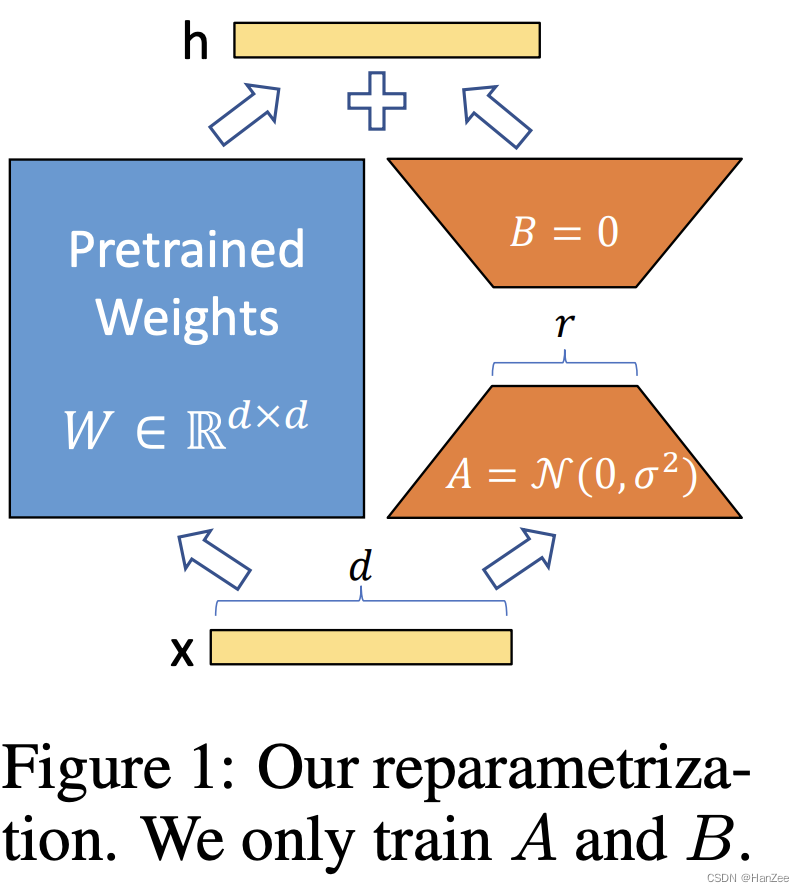
Lora主要有这些优势:
- 一个Pre-train model可以用来为不同的任务建立许多小的LoRA模块,可以冻结共享模型,并通过替换图1中的矩阵A和B来有效地切换任务,从而大大减少存储需求和任务切换的开销。
- Lora 更高效并且降低了硬件门槛。
- 在推理时,可以把图一中两种颜色的矩阵合并,与完全finetune的速度没有差别。
- LoRA与许多先前的方法是不相关的,并且可以与许多方法相结合。
作者又介绍了一些符号的定义:(这里我直接词典翻译)
术语和惯例 我们经常提到Transformer架构,并对其维度使用常规术语。我们把Transformer层的输入和输出维度大小称为model。我们用Wq、Wk、Wv和Wn来指代self-attention模块中的查询/键/值/输出投影矩阵。W或W0指的是预训练的权重矩阵,∆W指的是适应过程中的累积梯度更新。我们用r来表示一个LoRA模块的秩。我们遵循(Vaswani等人,2017;Brown等人,2020)规定的惯例,使用Adam(Loshchilov & Hutter,2019;Kingma & Ba,2017)进行模型优化,并使用Transformer MLP前馈维度dfn=4×dmodel。
Method
一个神经网络包含许多dense layers,它们通常都是满秩的,但是通过下游任务微调后,这些权重矩阵通常是低秩的,但是他们仍然可以有效学习。作者收到启发,假设Pre-Train model 的权重矩阵为 w0:
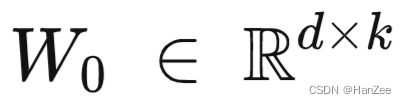
冻结它,引入新的底秩分解矩阵 :
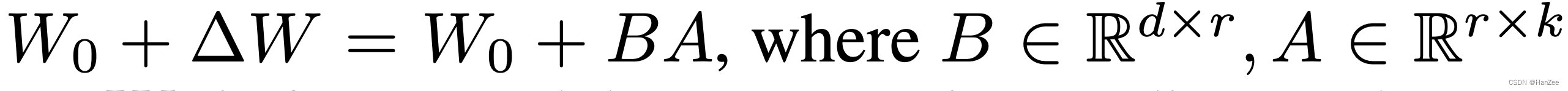
这里有些类似于1 * 1 conv的形式,中间的 维度 r 都是为在加速的前提下尽可能保留更多的信息,r的选择我认为作者应该会考虑与完全 finetune 权重矩阵的秩差不多的数。其中 W0 与 BA (其中BA与图1对应)与相同的Input 做矩阵乘法,然后二者在求和。
公式如下:
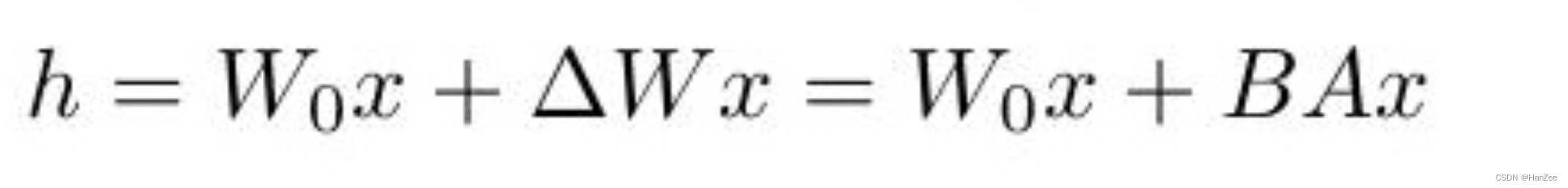
其中A通过正态分布 初始化,B则全0,所以BA也是全0矩阵。
这个额外的矩阵是支持热‘插拔的’,是指我可以在不同的下游任务应用不同的矩阵,比如我想做词性标注,我只需要原始的Pre-train model 加上在词性标注数据上finetune 的 BA就可以了,并且速度不受影响。
Experiment
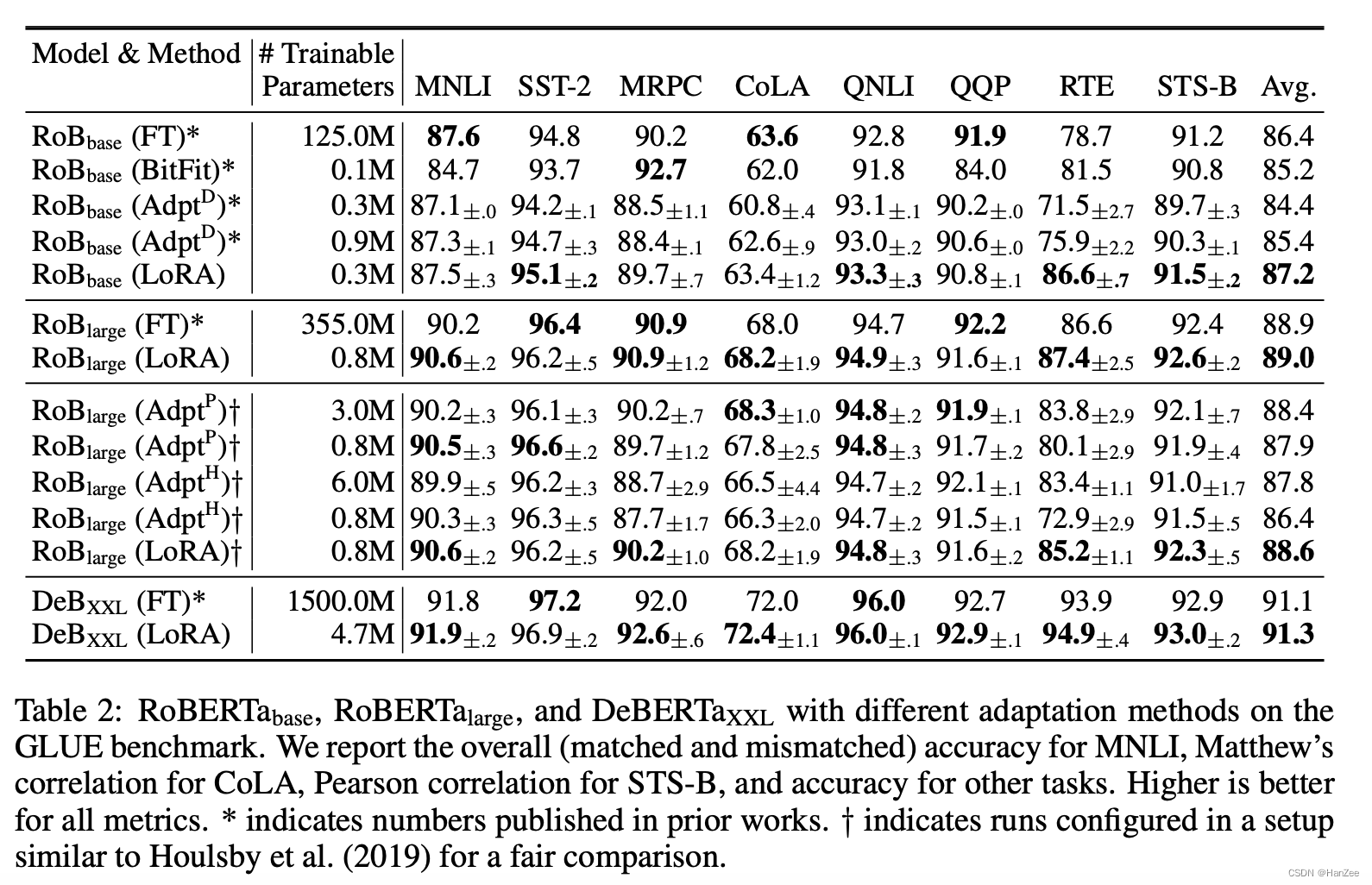
代码
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=['query_key_value']
)
model = "加载的模型"
model = get_peft_model(model, peft_config)
# 打印参数情况
model.print_trainable_parameters()
接下来和正常训练模型一样
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

