
热门标签
热门文章
- 1人工智能技术:现状、挑战与未来展望_对人工智能的总结与展望
- 2qgroundcontrol在LINUX下的编译与调试_/tmp/.mount_qgroun3ef27o/qgroundcontrol: /lib/x86_
- 3Spring Boot 整合 Redis 实现排行榜功能
- 4VSCODE远程ssh调试linux+cpolar内网穿透_cpolar ssh
- 5kafka保证消息有序性
- 6动手学深度科学课后作业-现代CNN_在使用批量规范化之前,我们是否可以从全连接层或卷积层中删除偏置参数?为什么?
- 7米哈游客户端笔试题_校招进米哈游客户端开发岗位需要具备哪些能力?
- 8LeetCode 45. 跳跃游戏 II_给一个正整数列 nums,一个跳数 jump,及幸存数量 left。运算过程为:从索引为0的位
- 9红黑树介绍_叶结点有没有平衡因子
- 10关于Keil5报错Loading PDSC Debug Description failed for STMicroelectronics STM32xxx ......_loading pdsc debugdescription failed
当前位置: article > 正文
python 爬虫如何获取js里面的内容_soup获取js中的值
作者:IT小白 | 2024-03-13 00:01:25
赞
踩
soup获取js中的值
一、在编写爬虫软件获取所需内容时可能会碰到所需要的内容是由javascript添加上去的 在获取的时候为空 比如我们在获取新浪新闻的评论数时使用普通的方法就无法获取
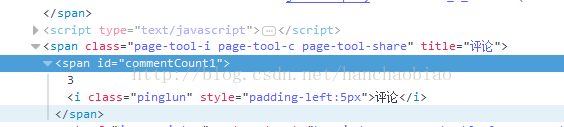
普通获取代码示例:
- import requests
- from bs4 import BeautifulSoup
-
- res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml')
- res.encoding = 'utf-8'
- soup = BeautifulSoup(res.text,'html.parser')
- #取评论数
- commentCount = soup.select_one('#commentCount1')
- print(commentCount.text)
此时所获取的结果为空 这是由于内容是存储在js文件中
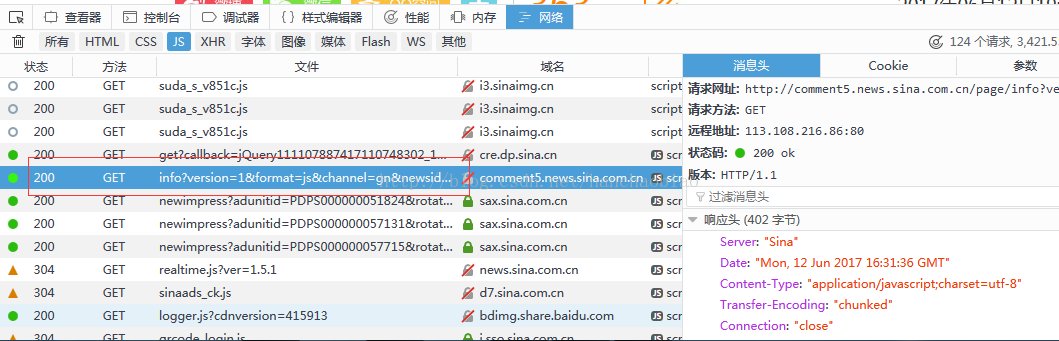
因此我们需要取寻找存储评论内容的js 经过查找我们发现其存储在改js里
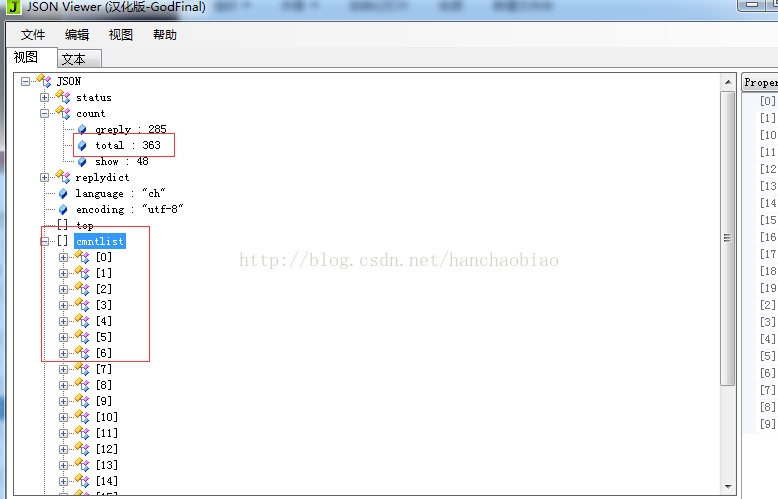
将相应内容放入json数据查看器中我们发现评论总数和评论内容都在该js文件中一json格式存放
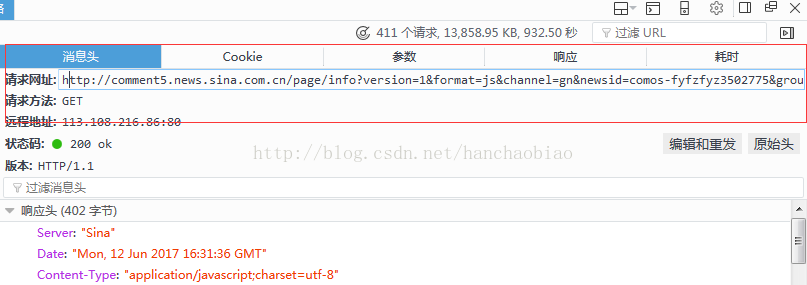
在消息头中我们可以看的该js文件的访问路径及请求方式
代码示例
- import json
- comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783')
- comments.encoding = 'utf-8'
- print(comments)
- jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据
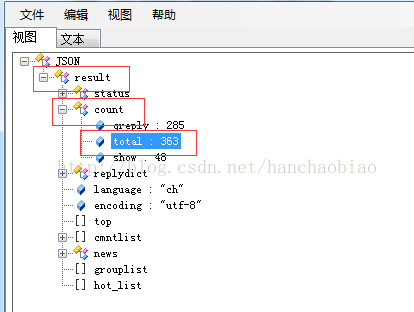
- print(jd['result']['count']['total'])
注释:这里解释下为何需要移除 var data= 因为在获取时字符串前缀是包含var data=的 其不符合json数据格式 因此转化时需将其从请求内容中移除

取评论总数时为何使用jd['result']['count']['total']
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/226629
推荐阅读
相关标签

