
热门标签
热门文章
- 1ubuntu22.04安装Ros2(每步都有图)(20221124)
- 2用kithara驱动控制IS620N伺服电机简单实例_kithara不支持千兆网卡
- 3机器学习各大模型原理的深度剖析!进来学习!!_机器学习模型
- 4ESLint 的一些理解_eslint explicit
- 5ThreadPoolExecutor和ThreadPoolTaskExecutor区别_executorthreadpool 和 executorthreadtaskpool
- 6腾讯云函数 python_腾讯云函数SCF使用心得
- 7linux mysql8离线升级_mysql 8.0升级8.4
- 8人工智能 | 通俗讲解AI基础概念_人工智能 通俗讲义
- 9计算机常用英语词汇_s expected. if you encounter any issues, please re
- 10Django | 从中间件的角度来认识Django发送邮件功能
当前位置: article > 正文
pytorch优化器
作者:IT小白 | 2024-08-20 04:26:13
赞
踩
pytorch优化器
优化器optimizer加速神经网络的训练
SGD方法(Stochestic Gradient Descent)(随机梯度下降)每次使用批量数据训练,虽然不能反映整体情况,但是加速了训练速度,也不会丢失很多的准确度。
其他方法参考:Optimizer
import numpy as np import torch import torch.utils.data as Data import torch.nn.functional as F import matplotlib.pyplot as plt from torch.autograd import Variable #给一些超参数 LR = 0.01 BATCH_SIZE = 32 EPOCH = 12 x = torch.unsqueeze(torch.linspace(-1,1,1000),dim = 1) y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) #plot dataset plt.scatter(x.numpy(),y.numpy()) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
打印数据点看一下数据
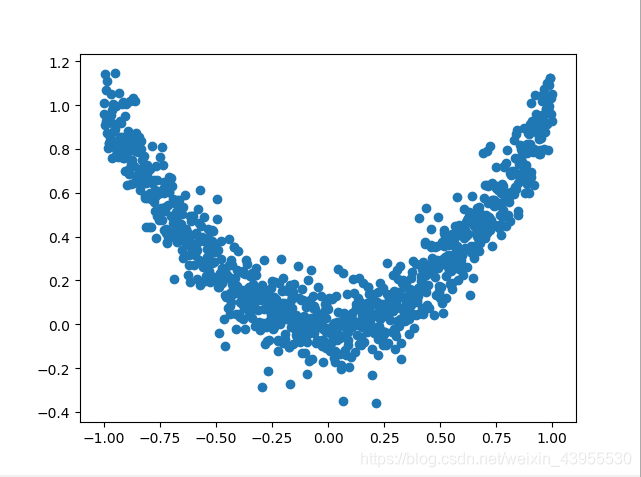
import numpy as np import torch import torch.utils.data as Data import torch.nn.functional as F import matplotlib.pyplot as plt from torch.autograd import Variable #给一些超参数 LR = 0.01 BATCH_SIZE = 32 EPOCH = 12 x = torch.unsqueeze(torch.linspace(-1,1,1000),dim = 1) y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) ##plot dataset #plt.scatter(x.numpy(),y.numpy()) #plt.show() torch_dataset = Data.TensorDataset(x,y) loader = Data.DataLoader(dataset = torch_dataset,batch_size = BATCH_SIZE,shuffle = True) #构建神经网络 class Net(torch.nn.Module): #从Module模块继承 #定义阶段 def __init__(self,n_feature,n_hidden,n_output): super(Net,self).__init__() #继承Net到模块 self.hidden = torch.nn.Linear(n_feature,n_hidden)#隐藏层 self.predict = torch.nn.Linear(n_hidden,n_output)#输出层 #搭建神经网络过程 def forward(self,x):#神经网络前向传递的过程 x = F.relu(self.hidden(x)) x = self.predict(x) #在输出的时候不用激励函数,因为用激励还输会截断一部分值的数据 return x #用四个不同的优化器优化神经网络 net_SGD = Net(1,20,1) net_Momentum = Net(1,20,1) net_RMSprop = Net(1,20,1) net_Adam = Net(1,20,1) nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam] opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr = LR) opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr = LR,momentum = 0.8) opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9) opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99)) optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam] loss_func = torch.nn.MSELoss() losses_his = [[],[],[],[]] #记录每个优化器的误差变化 for epoch in range(EPOCH): print('Epoch: ', epoch) for step, (batch_x, batch_y) in enumerate(loader): b_x = Variable(batch_x) #这里的batch_x都是tensor的形式,要Variable一下才能变成Variable b_y = Variable(batch_y) # 对每个优化器, 优化属于他的神经网络 for net, opt, l_his in zip(nets, optimizers, losses_his): output = net(b_x) # get output for every net loss = loss_func(output, b_y) # compute loss for every net opt.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients opt.step() # apply gradients l_his.append(loss.data.numpy()) # loss recoder labels = ['SGD','Momentum','RMSprop','Adam'] for i,l_his in enumerate(losses_his): plt.plot(l_his,label = labels[i]) plt.legend(loc = 'best') plt.xlabel('Steps') plt.ylabel('Loss') plt.ylim((0,0.2)) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
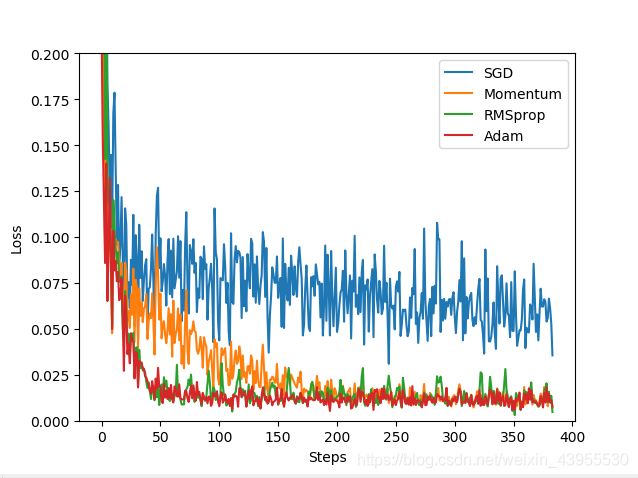
Momentum比SGD更快一点
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/1005190
推荐阅读
相关标签

