
热门标签
热门文章
- 1Ubuntu服务器更改远程端口号的方法_ubuntu网络port怎么设置
- 2CloudFlare域名管理系统_cloudflare批量管理
- 3php论坛源代码,php论坛源代码下载
- 4AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates
- 5Strongswan与Andriod野蛮模式L2TPoverIPsec对接有时候不成功。_strongswan ipsec不生效
- 6算法32:环形链表(有双指针)_求环形链表的节点数java
- 7idea2018项目导入2020.1idea依赖包失败的解决方法_getloadedimportedassetsandartifactids called with
- 8Python爬虫:代理ip电商数据实战
- 9聚类分析之 K均值_k均值聚类适用于什么样的数据
- 10python uiautomator2 安装及使用_python uiautomatic2 使用方法
当前位置: article > 正文
python实现Excel表操作_python pillow 绘制表格
作者:Guff_9hys | 2024-08-14 19:37:53
赞
踩
python pillow 绘制表格
1.需求:
输出所有同学“名称:对应成绩”的信息
输出分值最高和最低的同学名称及分数,(如有重复并列输出)
求出平均值并输出
输出高于平均值的同学名称及成绩
输出低于平均值的同学名称及成绩
将成绩排名信息写入csv格式的文件中,文件名称为:test_你自己的名字_时间戳.csv
生成一个图片,将前三名信息水印在这张图片上,将图片保存在
2.表格要求
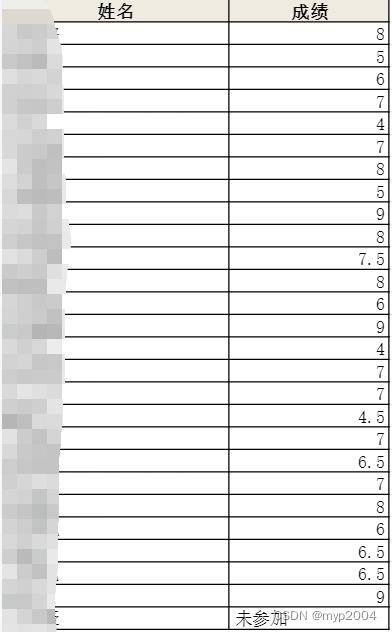
3.安装第三方库
pip install Pillow
Pillow = PIL
PIL:(Python Imaging Library)是一个常用的Python图像处理库,它提供了处理图像的各种功能和工具。在PIL库中,Image、ImageDraw和ImageFont是一些重要的模块和类,用于创建、操作和渲染图像
Image模块是PIL库的核心模块,用于创建、打开和保存图像。它提供了各种方法和属性,用于访问图像的像素、大小、模式、颜色等信息。ImageDraw模块是用于在图像上绘制图像的几何图形、文本等的模块。它提供了各种方法和函数,如line()、rectangle()、text()等,用于在图像上绘制形状和文本。ImageFont模块用于加载和使用字体文件。它提供了一种方法用于选择和设置在图像上绘制文本时所使用的字体和字号。
pip install openpyxl
openpyxl:
- 读取Excel文件:openpyxl可以打开现有的Excel文件,并提供对工作表、单元格和数据等的访问。通过它,可以读取Excel文件中的数据,进行数据处理和分析。
- 写入Excel文件:使用openpyxl可以创建新的Excel文件,并在工作表中填充数据、设置格式和公式等。这对于生成自定义报表和导出数据非常有用。
- 修改Excel文件:openpyxl也支持修改现有Excel文件中的数据、样式和设置等。可以插入新的行或列,更新单元格的值和格式化。
- 操作工作表和单元格:openpyxl提供了许多方法和属性,用于获取、设置和操作工作表和单元格的数据、样式和设置。可以访问单元格的值、公式、样式、字体、边框等。
- 处理图表和图像:openpyxl还支持处理Excel文件中的图表和图像。可以读取和修改图表的数据,以及插入、删除和调整图像的位置和大小。
4.代码展示
代码不理解的下面有解释
- import openpyxl, csv
- from datetime import datetime
- from PIL import Image, ImageDraw, ImageFont
-
-
- #遍历每一行,获取同学的名称和成绩
- def read_excel(file_path):
- # 打开Excel文件
- workbook = openpyxl.load_workbook(file_path)
- # 选择一个工作表
- sheet = workbook.active
- # 生成一个字典
- students = {}
-
- # 遍历每一行,获取同学的名称和成绩
- for row in sheet.iter_rows(min_row=2, values_only=True):
- name, score = row
-
- if score is None or score == '未参加':
- continue
- try:
- students[name] = float(score)
- except ValueError:
- print(f"无法将值转换为浮点数:{score}")
- return students
-
-
- #输出所有同学的名称·成绩
- def output_all_students(students):
- print("所有同学的成绩:")
- for name, score in students.items():
- print(f'{name}:{score}')
-
-
- #输出分数最高和分数最低的同学
- def output_highest_and_lowest_scores(students):
- max_score = max(students.values())
- min_score = min(students.values())
- #这里利用了列表推导式找出分数最高和最低的同学
- highest_students = [name for name, score in students.items() if score == max_score]
- lowest_students = [name for name, score in students.items() if score == min_score]
-
- print("分数最高的同学:")
- for name in highest_students:
- print(f'{name}:{max_score}')
-
- print("分数最低的同学:")
- for name in lowest_students:
- print(f'{name}:{min_score}')
-
-
- #获取所有同学的平均值
- def calculate_average_score(students):
- scores = list(students.values())
- total_scores = sum(scores)
- average_score = total_scores / len(scores)
- return average_score
-
-
- #获取分数高于平均值的同学
- def output_above_average_students(students, average_score):
- print("分数高于平均值的同学:")
- for name, score in students.items():
- if score > average_score:
- print(f'{name}:{score}')
-
-
- #获取分数低于平均值的同学
- def output_below_average_students(students, average_score):
- print("分数低于平均值的同学:")
- for name, score in students.items():
- if score < average_score:
- print(f'{name}:{score}')
-
-
- #将成绩按照降序写入csv文件并打印
- def write_to_csv(students):
- # 按照成绩降序排列学生信息
- sorted_students = sorted(students.items(), key=lambda x: x[1], reverse=True)
-
- # 生成CSV文件名
- csv_filename = f"test_your_name_{datetime.now().strftime('%Y%m%d%H%M%S')}.csv"
-
- # 生成CSV文件
- with open(csv_filename, mode='w', newline='') as file:
- writer = csv.writer(file)
- writer.writerow(['姓名', '成绩'])
- writer.writerows(sorted_students)
-
- # 打印写入信息
- print(f"排名信息已写入CSV文件:{csv_filename}")
-
-
- #生成一张图片并添加前三名同学的信息
- def add_watermark(students):
- # 生成一张空白图片
- image = Image.new('RGBA', (500, 300), (255, 255, 255))
- draw = ImageDraw.Draw(image)
-
- # 定义水印的字体样式
- font = ImageFont.truetype('C:/Windows/Fonts/simhei.ttf', 24)
-
- # 获取前三名的信息
- top_students = sorted(students.items(), key=lambda x: x[1], reverse=True)[:3]
-
- # 在图片上添加水印
- x = 50 # 水印文本左上角的x坐标
- y = 50 # 水印文本左上角的y坐标
- for index, (name, score) in enumerate(top_students):
- watermark_text = f"姓名:{name} 成绩:{score}" # 构造水印文本
- draw.text((x, y), watermark_text, font=font, fill=(0, 0, 0, 128))
- y += 30
- # 保存图片
- image.save('img_2.png')
-
- print("水印已成功添加到图片!")
-
-
- if __name__ == '__main__':
- # 读取Excel文件
- file_path = '2209A.xlsx'
- students = read_excel(file_path)
-
- # 输出所有同学的成绩
- output_all_students(students)
-
- # 输出分数最高和最低的同学分数
- output_highest_and_lowest_scores(students)
-
- # 计算平均分数
- average_score = calculate_average_score(students)
- print(f"平均分数:{average_score}")
-
- # 输出高于平均分值的同学及成绩
- output_above_average_students(students, average_score)
-
- # 写入csv文件
- write_to_csv(students)
-
- # 生成图片写入水印
- add_watermark(students)

-
openpyxl.load_workbook:是 openpyxl 库中用于加载 Excel 工作簿的函数。它可以打开一个现有的 Excel 文件并返回一个表示该工作簿的对象,以供后续操作
-
workbook.active:是 openpyxl 中的一个属性,用于获取工作簿中当前活动的工作表对象。活动工作表是用户最后一次使用的工作表,或者在创建工作簿时没有指定默认活动工作表时的第一个工作表
-
sheet.iter_rows:是 openpyxl 库中 Sheet 对象的一个方法,用于迭代工作表中的行,并返回一个生成器(generator)。通过迭代行,你可以方便地访问工作表中的单元格数据
-
min_row=2:指定要开始迭代的行号,默认为工作表的第一行,这是是从第2行开始
-
values_only:是 openpyxl 库中 iter_rows() 方法的一个参数,用于指定是否仅返回单元格的值,而不包括其他属性(如样式、公式等)通过设置 values_only=True,可以方便地获取工作表中的单元格值而不需要其他的信息
- draw.text():deaw.text()方法用于在图像上绘制文本,接受一些参数来指定文本的位置、内容、字体、填充颜色等。y += 30则是递增变量y的值,以便在绘制下一行文本时垂直偏移
- csv.writer():cas.writer()是一个用于写入CSV文件的函数,它是csv模块的一部分,通过创建一个writer对象,你可以使用该对象的方法将数据写入CSV文件中
-
writer.writerow(['姓名', '成绩']):标题内容
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/980525
推荐阅读
相关标签

