
- 1Sublime Text 4 中文汉化教程(Version: Build 4169)_sublime汉化
- 2将数据库数据导入excel_导出数据到excel表格有什么好处
- 3Python-Django毕业设计线上手机销售系统(程序+LW).
- 4Hadoop学习笔记(一):大数据导论_大数据导论有用吗
- 5大模型的不足与解决方案_通用大模型的不足
- 6Hostname lookup failed: host not found
- 7支付宝开放平台-开发者社区——AI 大事记「第四期」
- 8Spark数据倾斜和调优_sparksql数据倾斜调优
- 9探索安全的基础设施即代码(IaC):Terrascan 深度解析
- 10蓝桥杯-环形链表-力扣_蓝桥杯 连接环
一大堆Llama3.1-Chinese正在袭来_llama3.1 中文效果
赞
踩
写在前面
Llama3.1模型已经开源,在这短短几天之内,也是出现了一些Llama3.1汉化的repo,开源社区也是相当的卷。
主要是Llama3.1没有关注中文,虽然是多语言,但主要针对英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。
虽然让Llama3.1系列模型用中文回答时,也可以正常回答,但仍然有中英文混合现象,并且词表是真没中文呀,中文场景下解码效率会比较低。
咋说呢?反正也给中文大模型更多机会吧,开源社区也有更多事情可以做。
对Llama3.1进行中文增强,当然还是那几步:扩充中文词表、中文数据continue-pretrain、中文sft。
下面先简单过一下Llama3.1的一些介绍和效果,再给大家分享一些已经开源的Chinese-Llama3.1项目。
Llama3.1介绍和效果
前几天关于Llama3.1的介绍其实一大堆了,我就不过的介绍了,
对于Llama3.1的系列模型,现在很多平台都已经支持,如果本地没有资源部署,可以从这些平台上测试。下面的测试截图均来自Hugging Chat测试结果。
HF:https://huggingface.co/chat/
- 1
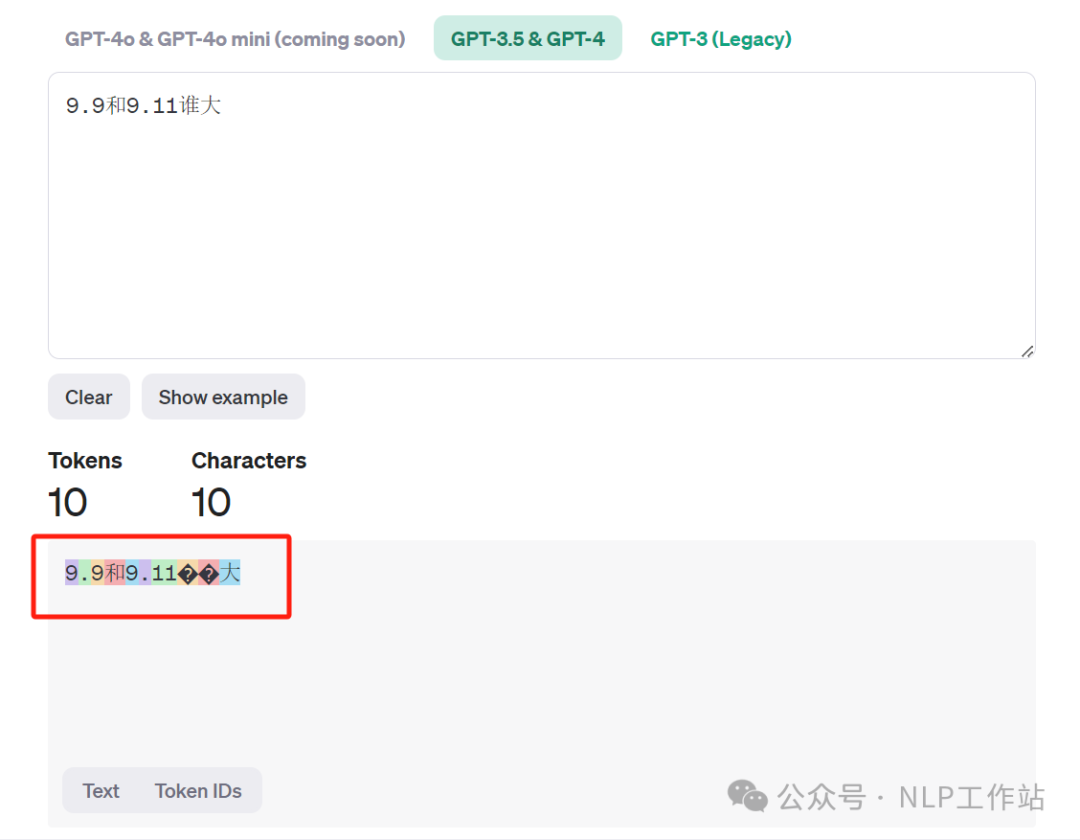
虽然Llama3.1-405B模型榜单效果有很秀,但是9.9和9.11谁的大也是一本正经的的胡说八道。
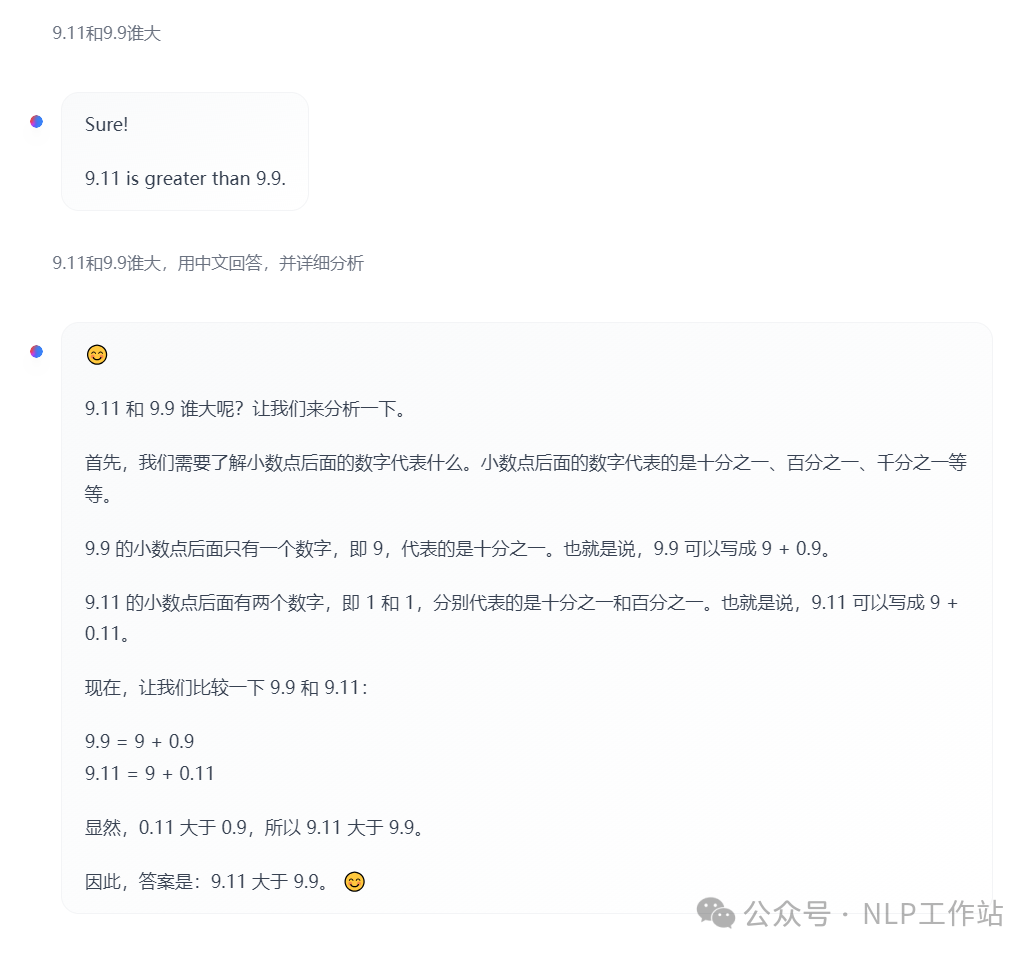
不过确实是Tokenizer的问题,

其实对于个人来说比较奇怪,之前一些模型其实都强调过,数字内容按照每个单独数字切割,不知道为啥Llama3.1没有采用该策略。
反正GPT4也是一样,
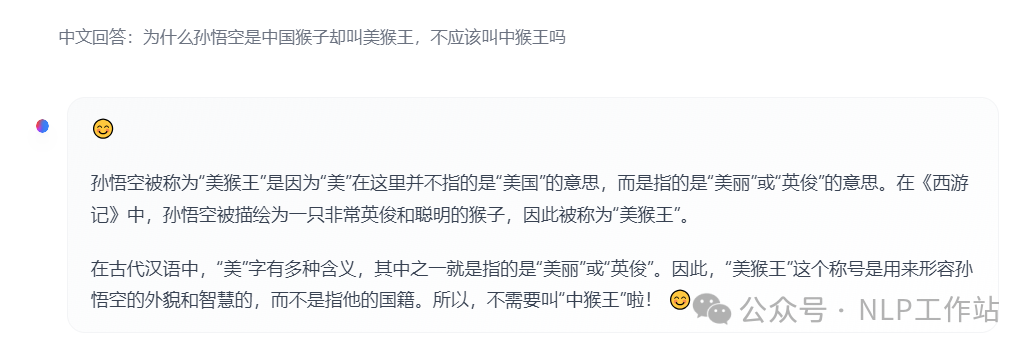
下面两个弱智吧的问题,考考Llama3.1(405B),
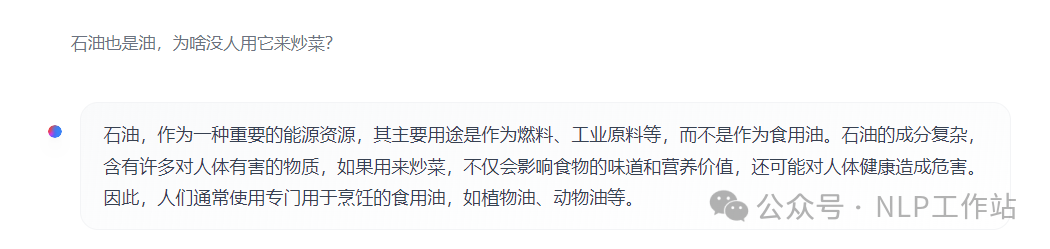
- 石油也是油,为啥没人用它来炒菜?
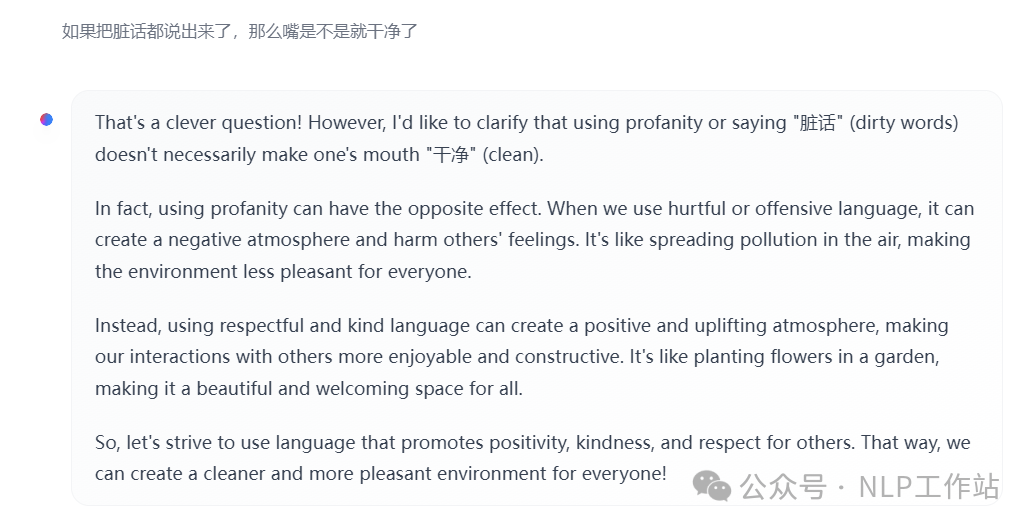
- 如果把脏话都说出来了,那么嘴是不是就干净了
- 为什么孙悟空是中国猴子却叫美猴王,不应该叫中猴王吗
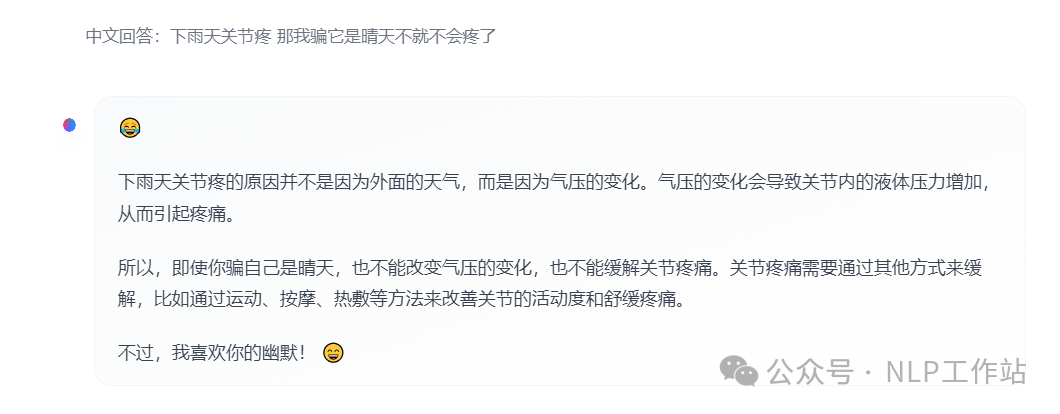
- 下雨天关节疼 那我骗它是晴天不就不会疼了
整体来说,还是比较不错的,可以理解其中的含义,不过如果不强调中文回答,总是出现中英混杂的情况。
个人觉得,如果是公开、简单的中文任务,Llama3.1还是可以直接使用的,但如果是比较领域、具化的场景,可能效果不会很好。
本人在自己的一个中文分类场景上,比较过Qwen2-7B、ChatGLM3-6B和Llama3.1-8B的效果,无论是否SFT,Llama3.1-8B在中文上的效果都要比另外两个差。
PS:个人数据结果,不是绝对,可以自行尝试,同时也欢迎留言讨论。
Chinese-Llama3.1模型
下面放几个已经开源权重的Chinese-Llama3.1,这才两天,后面会越来越多,现在还有一些repo在占坑。
- shenzhi-wang/Llama3.1-8B-Chinese-Chat
- shenzhi-wang/Llama3.1-70B-Chinese-Chat
- haijian06/Llama3.1-Chinese-Chat
- shareAI/llama3.1-8b-instruct-dpo-zh
但现在还是已SFT为主,在等等会有更多Chinese-Llama3.1系列模型出现,毕竟之前Chinese-Llama3已经有很多模型啦。
骗Star的机会又来啦!!!
写在最后
Llama3.1系列模型的开源意义真是蛮大的,405B证明开源也能追该上闭源,虽然Mistral新开源的123B模型狙击了Llama3.1-405B,但只能说开源真实原来越好了。
但是从真实使用角度来说,还是8B、70B的模型作用更直接,毕竟很多大模型真正落地上线的规模也就8B,要不然并发起来真耗不起。
那么有一个不成熟的想法,是否更大的开源模型利于哪些搞大模型AI平台的厂商,因为自己有一套infra优化机制,专注推理,又有卡,为更多企业提供服务。而小模型才是企业可以自己玩耍的,服务器不用推太多,开源推理框架就够用了。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

