
热门标签
热门文章
- 1已解决python 的SyntaxError :invalid syntax异常正确解决办法,亲测有效,嘿嘿嘿_python中* syntaxerror: invalid syntax
- 2App移动端测试(10)—— Monkey自定义脚本案例_android monkey脚本demo
- 3基于python-opencv的摄像头识别五角星_五角星识别
- 4如何解锁苹果手机id锁?苹果手机物主锁定怎么办?苹果手机无法激活怎么办?_mix ramdisk解锁软件
- 5python numpy版本查询_查询numpy版本
- 6Gradio从入门到精通(1)---快速入门
- 7【Android】反编译与预防被反编译_安卓混淆apk反编译
- 8关于在II7里面出现:当前信任级别设置不支持调试 的解决方法_ii7 调试属性
- 9python数据分析需要的软件,python数据分析处理软件_数据处理用什么软件编写比较好
- 10pycharm连接远程服务器_todesk可以和pycharm一起实现对服务器的远程控制吗
当前位置: article > 正文
大模型算法面试 - 基础篇_大模型面经
作者:Guff_9hys | 2024-07-18 07:27:26
赞
踩
大模型面经
基础知识
1.transformer 八股文
a.Self-Attention的表达式
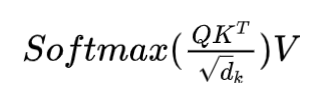
b.为什么上面那个公式要对QK进行scaling
scaling后进行softmax操作可以使得输入的数据的分布变得更好,你可以想象下softmax的公式,数值会进入敏感区间,防止梯度消失,让模型能够更容易训练。
c.self-attention一定要这样表达吗?
不一定,只要可以建模相关性就可以。当然,最好是能够高速计算(矩阵乘法),并且表达能力强(query可以主动去关注到其他的key并在value上进行强化,并且忽略不相关的其他部分),模型容量够。
d.有其他方法不用除根号
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/844255
推荐阅读
相关标签

