
- 1编程语言命名规范_请结合所学以及网络资料,介绍一下编程语言有哪些命名规则
- 2linux安装redis超级详细教程_linux环境部署redis6.2.10
- 3推动内容安全生态与通用大模型良性融合_内容安全通过大模型解决
- 4Linux : 解决ssh命令失败(ssh: Network is unreachable),MobaXtermSSH连接超时(Network error:Conection timed out )_ssh network is unreachable
- 5分布式系统—ELK日志分析系统概述及部署
- 6mysql添加用户_mysql添加用户
- 7C语言写二叉树_建立二叉树的代码c语言
- 8超详细的VSCode下载和安装教程(非常详细)从零基础入门到精通,看完这一篇就够了。
- 9PyCharm查看运行状态的步骤及方式!_pycharm 运行进度
- 10等保系列之——网络安全等级保护测评:工作流程及工作内容_网络安全等级保护测评流程
亚信科技基于 Apache SeaTunnel 的二次开发应用实践
赞
踩
亚信科技在Apache SeaTunnel的实践分享
自我介绍
各位同学好,很荣幸通过Apache SeaTunnel社区和大家进行分享交流。我是来自亚信科技的潘志宏,主要负责公司内部数据中台产品的开发。

本次分享的主题是Apache SeaTunnel在亚信科技的集成实践,具体讲我们的数据中台是如何集成SeaTunnel的。
分享内容概述
在本次分享中,我将重点讲解以下几个方面:
- 为什么选择SeaTunnel
- 如何集成SeaTunnel
- 集成SeaTunnel过程中遇到的问题
- SeaTunnel的二次开发
- 对SeaTunnel的期待
为什么选择SeaTunnel
首先介绍一下,我主要负责亚信数据中台产品DATAOS的迭代开发。DATAOS是一个比较标准的数据中台产品,涵盖数据集成、数据开发、数据治理、数据开放等功能模块。与SeaTunnel相关的主要是数据集成模块,该模块主要负责数据的整合。
在引入SeaTunnel之前,我们的数据集成模块的功能架构如下:
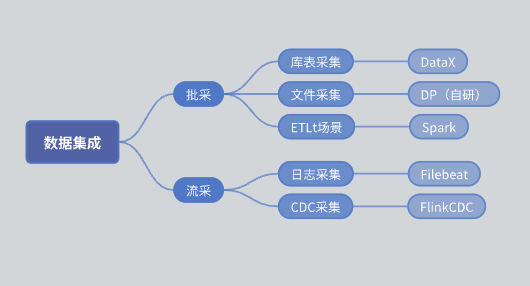
- 批采:分为库表采集和文件采集。
- 库表采集:主要使用DataX实现。
- 文件采集:自研的DP引擎。
- ETLt采集:自研的ETLt采集引擎。DataX偏向于ELT(抽取、加载、转换),适用于数据抽取入库后再进行复杂的转换,但在某些场景下需要进行EL小T(抽取、加载、简单的转换),DataX并不适合。因此,我们基于Spark SQL自研了一个引擎。
- 流采:日志采集主要基于Filebeat,CDC采集主要基于Flink CDC。
在我们的数据集成模块中,整体架构分为三层,分别是数据集成前台、调度平台以及数据集成服务。
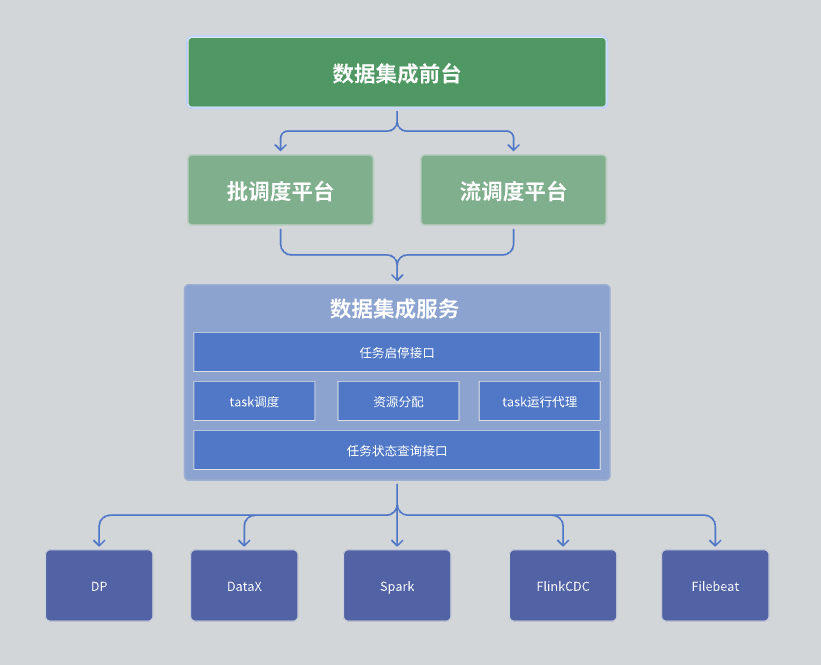
下面是每一层的详细描述:
第一层:数据集成前台
数据集成前台主要负责数据集成任务的管理。具体包括任务的开发、调度开发和运行监控。这些任务通过DAG(有向无环图)的方式将各个集成算子组合起来,实现复杂的数据处理流程。前台界面提供了直观的任务管理界面,使得用户可以方便地配置、监控数据集成任务。
第二层:调度平台
调度平台负责任务运行的调度管理。它支持批处理和流处理两种模式,并能够根据任务的依赖关系和调度策略拉起相应的任务。
第三层:数据集成服务
数据集成服务是整个数据中心服务的核心,它提供了一系列关键功能:
- 任务管理接口:包括任务的创建、删除、更新和查询等功能。
- 任务启停接口:允许用户启动或停止特定的任务。
- 任务状态查询接口:查询任务的当前状态信息,便于监控和管理。
数据集成服务还负责任务的具体运行。由于我们的采集任务可能包含多个引擎,这就需要在任务运行时实现多引擎的协调和调度。
任务运行流程
任务的运行主要包括以下几个步骤:
- 任务调度:根据预定的调度策略和依赖关系,调度平台拉起相应的任务。
- 任务执行:任务执行过程中,根据任务的DAG配置,依次执行各个算子。
- 多引擎协调:对于包含多个引擎的任务(如DataX和Spark混合任务),需要在执行过程中协调各个引擎的运行,确保任务的顺利执行。
资源分配
同时为了使DataX这种单机运行的任务能够更好地分布式运行,并实现资源复用,我们对DataX任务进行了资源分配的优化:
- 分布式调度:通过资源分配机制,将DataX任务分布到多个节点上运行,避免单点瓶颈,提高任务的并行度和执行效率。
- 资源复用:通过合理的资源管理和分配策略,确保不同任务在资源使用上的高效复用,减少资源浪费。
任务运行代理
我们对每个执行引擎实现了相应的任务执行代理,以实现任务的统一管理和监控:
- 执行引擎代理:在数据集成服务中,代理管理各个执行引擎,如DataX、Spark、Flink CDC等。代理负责任务的启动、停止以及状态监控。
- 统一接口:提供统一的任务管理接口,使得不同引擎的任务可以通过相同的接口进行管理,简化了运维和管理工作。
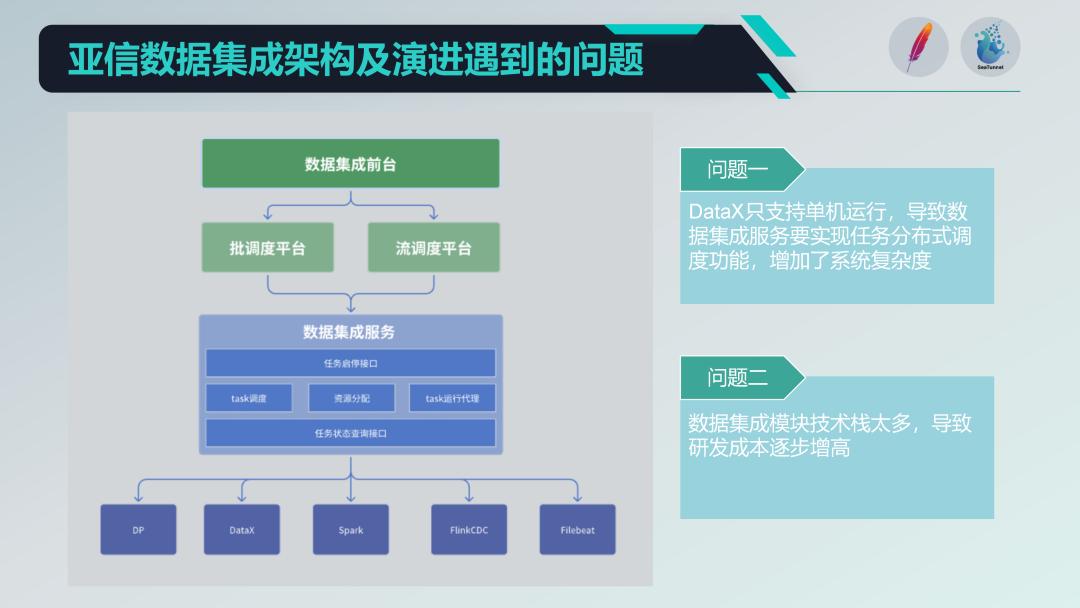
老的数据集成架构存在的一些问题
我们集成了一些开源项目,如DataX、Spark、Flink CDC、Filebeat等,形成了一个功能强大的数据集成服务平台。但也面临一些问题:
- 单机运行限制:DataX只支持单机运行,这导致我们需要在其基础上实现分布式调度功能,增加了系统的复杂度。
- 技术栈过于多样化:引入了多个技术栈(如Spark和Flink),虽然功能丰富,但也导致研发成本较高,每次开发新功能都需要应对多个技术栈的兼容性和集成问题。
架构演进
为了优化架构并降低复杂度,我们对现有架构进行了演进:
- 整合多引擎功能:引入SeaTunnel后,我们可以统一多个引擎的功能,实现单一平台上的多种数据处理能力。
- 简化资源管理:通过SeaTunnel的资源管理功能,简化了DataX等单机任务的分布式调度,降低了资源分配和管理的复杂度。
- 降低研发成本:通过统一的架构和接口设计,减少了多技术栈带来的开发和维护成本,提高了系统的可扩展性和易维护性。
通过对架构的优化和演进,我们成功地解决了DataX单机运行限制和多技术栈带来的高研发成本问题。
引入SeaTunnel后,我们能够在一个平台上实现多种数据处理功能,同时简化了资源管理和任务调度,提高了系统的整体效率和稳定性。
为什么选择 SeaTunnel?
我们与 SeaTunnel 的接触可以追溯到Waterdrop时期,针对于Waterdrop进行过多次应用实践。
去年,SeaTunnel 推出了 Zeta 引擎,支持分布式架构,并成为 Apache 顶级项目,这使得我们在去年找到了一个合适的时间节点,进行了深入的调研,并决定引入 SeaTunnel。
以下是我们选择 SeaTunnel 的几个主要原因:
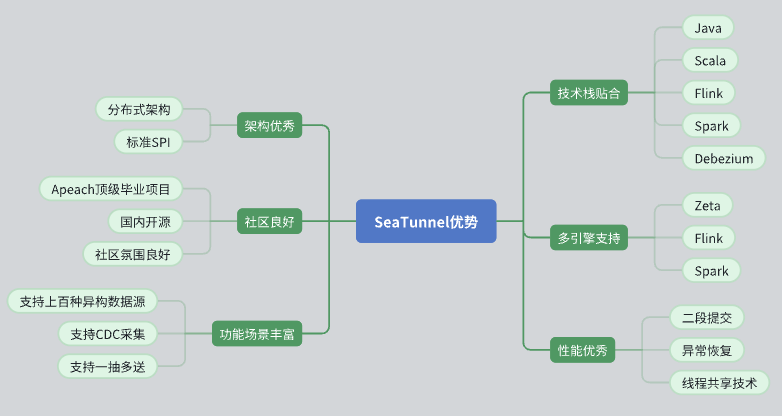
- 优秀的架构设计
- SeaTunnel 具有分布式架构,能够很好地适应我们的需求。
- 它的 API 设计标准化,采用了 SPI(Service Provider Interface)模式,便于扩展和集成。
- 活跃的社区支持
- SeaTunnel 是 Apache 顶级项目,社区氛围良好,活跃的开发者和用户群体为问题的解决和功能的扩展提供了强大的支持。
- 国内开源项目的背景,使我们在沟通和协作上更加顺畅。
- 丰富的功能和数据源支持
- SeaTunnel 支持多种数据源,功能丰富,能够满足我们多样化的数据处理需求。
- 支持 CDC(Change Data Capture),可以进行实时数据同步和处理。
- 支持一抽多送(one-to-many)的数据传输模式,提升了数据传输的灵活性。
- 技术栈的贴合
- SeaTunnel 兼容 Java,并且支持 Flink 和 Spark,使我们能够在现有技术栈上无缝集成和应用。
- 使用 Debezium 进行 CDC 数据捕获,技术实现成熟稳定。
- 多引擎支持
- SeaTunnel 支持多种计算引擎,包括 Zeta、Flink 和 Spark,能够根据具体需求选择最适合的引擎进行计算。
- 这一点非常重要,因为它允许我们在不同场景下选择最优的计算模式,提升了系统的灵活性和效率。
- 出色的性能
- SeaTunnel 设计了诸如二阶段提交(two-phase commit)、异常恢复(fault-tolerance recovery)以及线程共享(thread sharing)等性能优化机制,确保数据处理的高效和稳定。
引入SeaTunnel后解决的问题
SeaTunnel 能够解决我们之前提到的两个主要问题:
- 分布式调度
- DataX 只能单机运行,我们需要额外实现分布式调度功能。而 SeaTunnel 天生支持分布式架构,无论是使用 Zeta、Flink 还是 Spark 作为计算引擎,都能轻松实现分布式数据处理,大大简化了我们的工作。
- 技术栈整合
- 我们之前使用了多种技术栈,包括 DataX、Spark、Flink CDC 等,这使得研发成本高昂且系统复杂。而 SeaTunnel 通过统一封装这些技术栈,提供了一个集成化的平台,能够同时支持 ELT 和 ETL 流程,极大地简化了系统架构,降低了开发和维护成本。
如何集成 SeaTunnel
在集成 SeaTunnel 之前,我们的旧架构已经存在并运行了一段时间,整体上分为三层:前台、调度平台以及数据集成服务。前台负责任务的管理与开发,调度平台负责任务的调度与依赖管理,而数据集成服务则是执行和管理所有数据集成任务的核心部分。
以下是我们在集成 SeaTunnel 后的新架构。
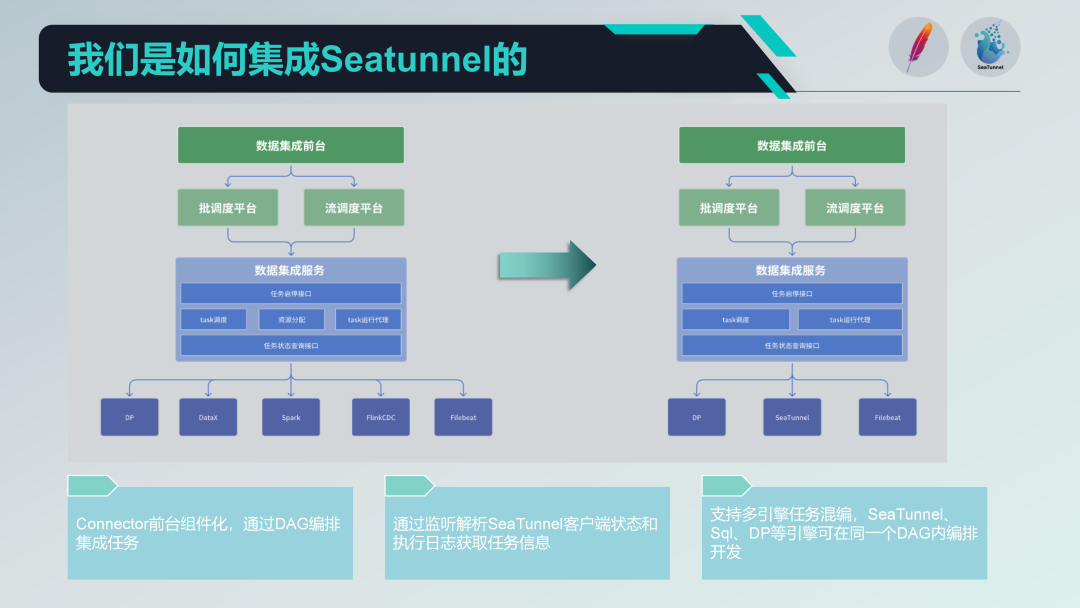
首先,我们将旧架构中涉及 DataX 的资源分配部分取消了。由于 SeaTunnel 本身支持分布式架构,不再需要额外的资源分配管理。这一调整极大地简化了我们的架构。
技术栈的替换
我们逐步使用 SeaTunnel 替换了旧有的技术栈。具体步骤如下:
- 替换批处理任务:我们先替换了旧架构中使用 DataX 和 Spark 进行批处理 ETL 的部分。
- 替换流处理任务:接下来,我们将逐步替换使用 Flink CDC 进行流处理的部分。 通过这种分步走的方式,我们可以确保系统在逐步过渡过程中始终保持稳定。
组件化 SeaTunnel Connector
我们基于 SeaTunnel 的 Connector 进行了组件化设计,并在前台通过表单方式进行配置和 DAG 编排。虽然 SeaTunnel Web 也在进行类似的工作,但我们根据自身需求进行了定制化开发,以便更好地与现有系统集成。
任务运行代理
在任务运行代理方面,我们通过 SeaTunnel 客户端提交任务,并监听 SeaTunnel 客户端的状态和执行日志。通过解析这些日志,我们可以获取任务的执行状态信息,确保任务执行的可监控性和可追踪性。
多引擎混编开发
我们支持多引擎混编开发,在前台页面可以对一个调度任务进行多引擎的 DAG 编排。这样,我们可以在一个调度任务中同时使用不同的引擎(如 SQL 引擎和 DP 引擎)进行任务开发,提高系统的灵活性和扩展性。
集成SeaTunnel过程中遇到的问题
在集成 SeaTunnel 的过程中,我们遇到了一些问题,以下是几个具有代表性的问题及其解决方案:
问题一:报错处理
在使用 SeaTunnel 的过程中,我们遇到了一些报错,这些报错涉及到框架的代码。由于官方文档中没有相关说明,我们通过加入社区微信群,向群内的开发者求助,及时解决了问题。
问题二:任务割接
我们的旧采集任务是使用 DataX 实现的,在替换为 SeaTunnel 时,需要考虑任务的割接问题。
我们通过以下方案进行解决:
- 组件化设计:我们的数据中台采集任务是组件化设计的,前台的组件和后台的执行引擎之间有一层转换层。前台配置表单,后台通过转换层生成 DataX 需要执行的 JSON 文件。
- 相似的 JSON 文件生成:SeaTunnel 的配置与 DataX 类似,前台同样是通过表单配置,后台生成 SeaTunnel 需要执行的 JSON 文件。通过这种方式,我们能够无缝地将旧任务转移到新的 SeaTunnel 平台上,确保任务的平滑过渡。
- SQL 脚本转换:编写 SQL 脚本,对旧有的 DataX 任务进行清洗和转换,使其能够适配 SeaTunnel。这种方法更具灵活性和适应性,因为 SeaTunnel 会频繁更新,直接写硬编码进行兼容不是长久之计。通过脚本转换,可以更高效地迁移任务,适应 SeaTunnel 的更新。
问题三:版本管理
我们在使用 SeaTunnel 的过程中遇到了版本管理的问题。SeaTunnel 的更新频繁,而我们团队的二开版本需要持续跟进最新版本。以下是我们的解决方案:
本地分支管理:我们基于 SeaTunnel 2.3.2 版本拉了一个本地分支,对其进行二次开发,包括修复个性化需求和临时修复的 bug。为了尽量减少本地维护的代码,我们仅保留必要的改动,其他部分尽量使用社区的最新版本。
定期合并社区更新:我们定期将社区的新版本合并到本地分支,特别是对我们改动的部分进行更新和兼容。虽然这种方法比较笨拙,但可以保证我们及时跟进社区的最新功能和修复。
回馈社区:为了更好地管理和维护代码,我们计划将我们的一些改动和个性化需求提交给社区,争取社区的接纳和支持。这不仅有助于减少我们本地的维护工作,也有助于社区的共同发展。
SeaTunnel 二次开发与实践
在 SeaTunnel 的使用过程中,我们针对实际业务需求进行了多项二次开发,特别是在连接器(Connector)层面。以下是我们在二次开发中遇到的问题及解决方案。
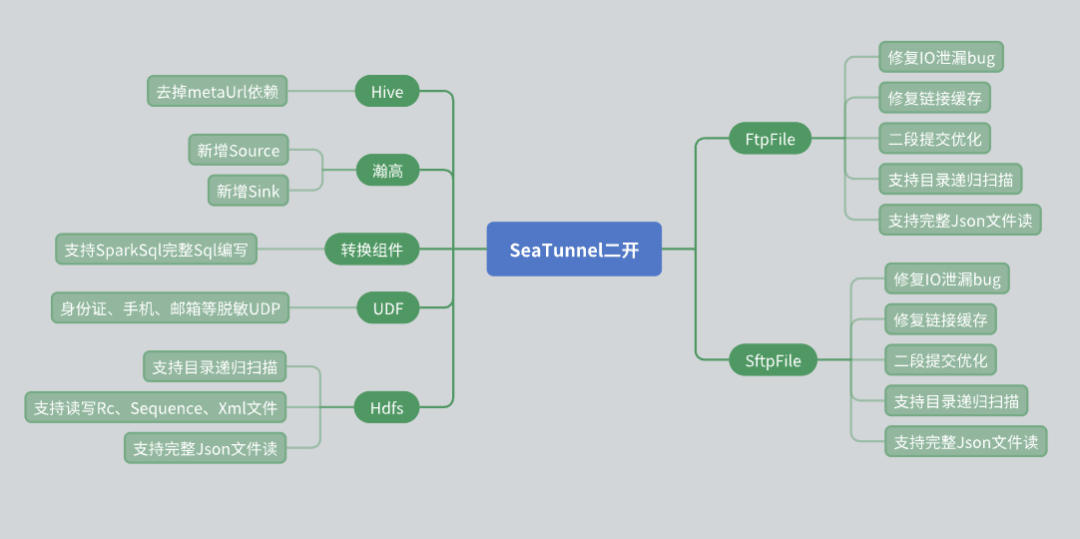
Hive Connector 的改造
- 原始的 SeaTunnel Hive Connector 需要依赖 Meta URL 来获取元数据。然而,在实际应用中,很多第三方用户因安全问题无法提供 Meta URL。为了应对这一情况,我们进行了如下改造:
- 使用 Hive Server 2 的 JDBC 接口来获取表的元数据信息,从而避免了对 Meta URL 的依赖。
- 通过这种方式,我们能够更灵活地为用户提供 Hive 数据的读写能力,同时确保数据安全。
瀚高数据库的支持
- 瀚高数据库在我们的项目中有广泛应用,因此我们增加了对瀚高数据库的数据源读写支持。同时,针对瀚高数据库的一些特殊需求,我们开发了转换组件:
- 支持行转列、列转行等复杂转换操作。
- 编写了多种 UDF(用户自定义函数),用于数据脱敏等操作。
文件连接器的改造
- 文件系统连接器在我们的使用中占有重要地位,因此我们对其进行了多项改造:
- HDFS Connector:增加了目录递归和正则表达式扫描文件的功能,同时支持读取和写入多种文件格式(如 RC、Sequence、XML、JSON)。
- FTP 和 SFTP Connector:修复了 I/O 泄露的 bug,并优化了连接缓存机制,确保同一 IP 不同账号之间的独立性。
二段提交机制的优化
在使用 SeaTunnel 的过程中,我们深入了解了其二段提交机制,以确保数据的一致性。以下是我们在此过程中遇到的问题及解决方案: 
问题描述:在使用 FTP 和 SFTP 进行文件写入时,报错提示没有写入权限。排查发现,SeaTunnel 为了保证数据一致性,会先将文件写入临时目录,然后再进行移动。
然而,由于不同账号对临时目录的权限设置问题,导致写入失败。
解决方案:在创建临时目录时,设置更大的权限(如 777),以确保所有账号都有权限写入。同时,解决了文件移动过程中由于跨文件系统导致的 rename 命令失败的问题,通过在同一文件系统下创建临时目录,避免了跨文件系统操作。
二次开发管理
在二次开发过程中,我们面临着如何管理和同步 SeaTunnel 新版本的问题。我们的解决方案如下:
- 本地分支管理:基于 SeaTunnel 2.3.2 版本拉了一个本地分
- 定期合并社区更新:定期将社区的新版本合并到本地分支,确保我们能够及时获得社区的新功能和修复。
- 回馈社区:计划将我们的一些改动和个性化需求提交给社区,以期获得社区的接纳和支持,从而减少本地维护的工作量。
SeaTunnel 集成与应用
在集成 SeaTunnel 过程中,我们主要关注以下几点:
- 资源分配优化:利用 SeaTunnel 的分布式架构,简化了资源分配问题,不再需要额外的分布式调度功能。
- 技术栈整合:将 DataX、Spark、FlinkCDC 等不同技术栈的功能整合到 SeaTunnel 中,统一封装,实现 ETL 和 ELT 的一体化。
通过以上步骤和策略,我们成功地将 SeaTunnel 集成到我们的数据集成服务中,解决了旧有系统中的一些关键问题,优化了系统的性能和稳定性。
在这个过程中,我们积极参与社区,寻求帮助并反馈问题,确保集成工作的顺利进行。这种积极的互动不仅提高了我们的技术水平,也推动了 SeaTunnel 社区的发展。
参与开源社区的心得体会
在参与 SeaTunnel 的过程中,我有以下几点体会:
- 时间合适:我们在 SeaTunnel 快速发展的阶段选择了这个项目,时机非常好。SeaTunnel 的发展给了我们很大的信心,让我们觉得有很多事情可以做。
- 个人目标:我在今年年初就定下了参与开源社区的目标,并积极付诸行动。
- 社区的友好:SeaTunnel 社区非常友好,大家交流顺畅,相互帮助。这种积极的氛围让我觉得参与其中非常值得。
对于那些一直想参与开源社区但还没有迈出第一步的人,我想鼓励大家勇敢地迈出这一步。社区最重要的是人,只要你加入,你就是社区中不可或缺的一部分。
对 SeaTunnel 的期待
最后,我想分享一下对 SeaTunnel 的一些期待:
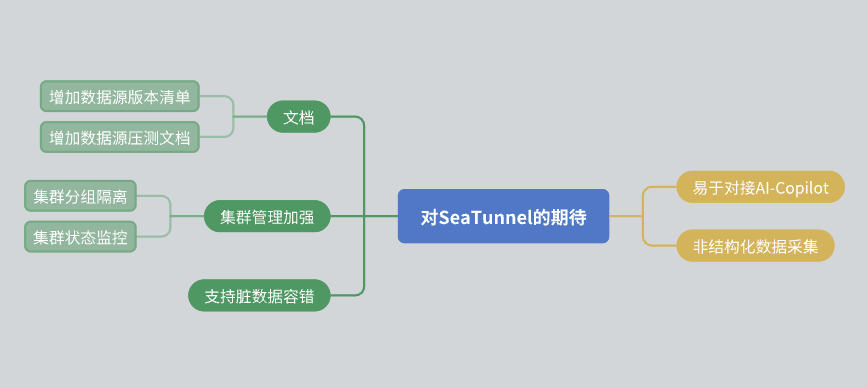
- 文档改进:希望社区能进一步完善文档,包括数据源的版本清单和压测报告。
- 集群管理:希望 SeaTunnel 在集群内部能实现资源隔离,并提供更丰富的集群状态监控信息。
- 数据容错:虽然 SeaTunnel 已经有容错机制,但希望未来能进一步优化。
- AI 集成:希望 SeaTunnel 能提供更多接口,方便 AI 辅助接入。
感谢 SeaTunnel 社区的每一位成员,感谢你们的付出。我的分享就到这里,谢谢大家!
本文由 白鲸开源科技 提供发布支持!

