- 1XUbuntu22.04之安装OBS30.0强大录屏工具(一百九十五)_ubuntu22.04.3安装录屏软件
- 2基于STM32的倒车雷达系统设计_rd-3雷达模块stm32
- 3SpringBoot+redis实现消息队列(发布/订阅)_org.springframework.data.redis.listener.redismessa
- 4AIGC - 高考语文作文全国篇
- 5编译原理:算符优先分析实验_算符优先分析法实验
- 6机器人学:(3)机器人运动学
- 7PaddleHub一键OCR中文识别 身份证识别_paddlehub 身份证识别
- 8探索微软Edge浏览器:一款现代浏览器的详细评测
- 9生信数据分析——GO+KEGG富集分析_go富集分析
- 10智能建筑与物联网技术:重塑未来空间的智慧交响曲
hadoop的伪分布式搭建_hadoop伪分布式搭建
赞
踩
1、hadoop的安装方式分为以下三种
a. 单机模式:只能使用Hadoop的一些公共功能
b. 伪分布式模式:利用一个节点(服务器)模拟集群环境
c. 完全分布式模式:是实际生产场景中常用的搭建方式,利用多个节点搭建分布式集群环境
搭建hadoo伪分布式
1、关闭linux系统的防火墙
a、临时关闭:service iptables stop
b、永久关闭:chkconfig iptables off
2. 配置主机名称:
a. 要求:Hadoop的集群的主机名称不能有空格或者_,如果存在则会导致Hadoop集群无法找到该节点
b. 编辑文件:vim /etc/sysconfig/network
c. 将HOSTNAME属性修改为指定的主机名称,例如:HOSTNAME=hadoop01
3. 配置hosts文件,将主机名称与IP地址进行映射
a. 编辑文件:vim /etc/hosts
b. 添加配置:192.168.112.128 hadoop01
4. 进行SSH免密互通
a. 生成自己的公钥以及秘钥,生成的公钥和秘钥自动存放在/root/.ssh/目录下:ssh-keygen
b. 把生成的公钥注册到远程的服务器上:ssh-copy-id root@hadoop01
5. 重新启动Linux系统:reboot
6. 解压Hadoop安装包:tar -xvf hadoop-2.7.6.tar.gz
a. 修改JAVA_HOME的路径:export JAVA_HOME=/home/software/jdk1.8
b. 修改HADOOP_CONF_DIR的路径,修改为Hadoop配置文件的具体路径:
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.6/etc/hadoop
7. 进入Hadoop安装包子目录etc/hadoop配置Hadoop:cd /home/software/hadoop-2.7.6/etc/hadoop/
1、 配置hadoop-env.sh
.a、 修改JAVA_HOME的路径:export JAVA_HOME=/home/software/jdk1.8
b、. 修改HADOOP_CONF_DIR的路径,修改为Hadoop配置文件的具体路径:
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.6/etc/hadoop
2、配置core-site.xml
a、添加配置: 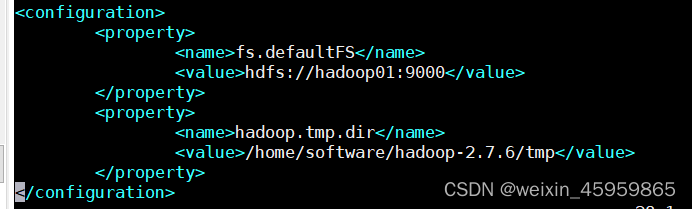
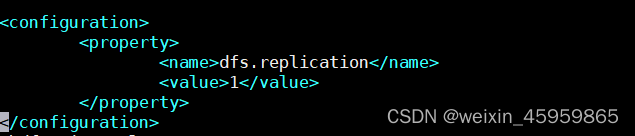
3、配置hdfs-site.xml
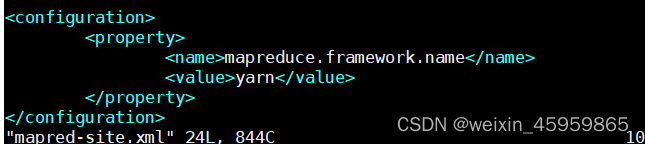
4、配置mapred-site.xml
a、将模板文件复制一份并重命名:cp mapred-site.xml.template mapred-site.xml
5、配置yarn-site.xml
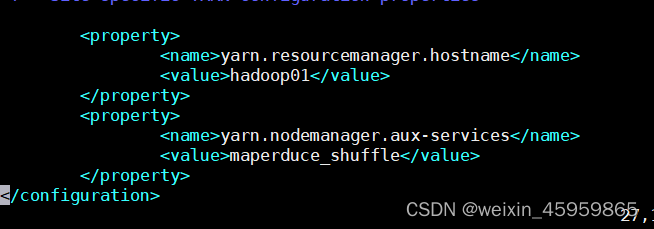
6、配置slaves

7、配置Hadoop的环境变量:
a、编辑文件:vim /etc/profile
8、重新生效该文件:source /etc/profile
9、验证Hadoop的环境变量是否配置成功:hadoop version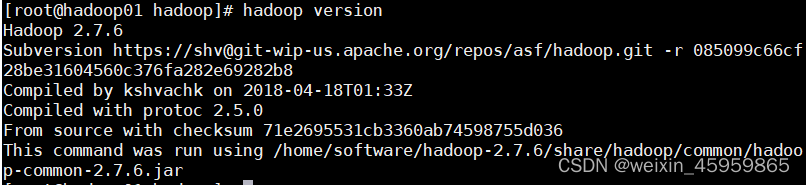
10、格式化NameNode:hadoop namenode -format

有这个,则代表格式化成功。

11、启动Hadoop:start-all.sh
因为是第一次启动,所以要建立连接,输入yes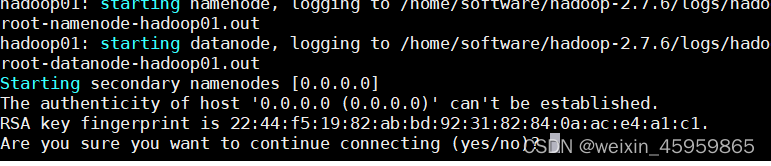
输入yes后
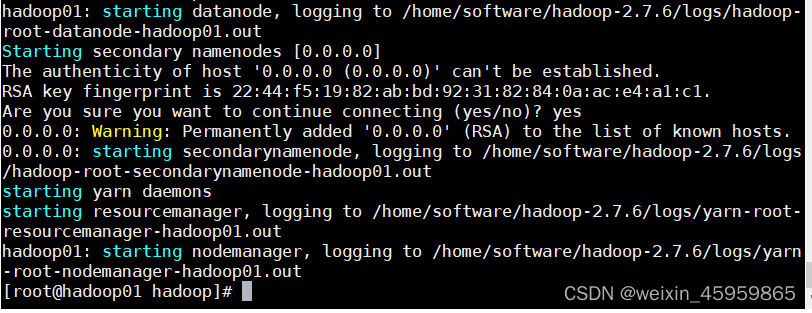
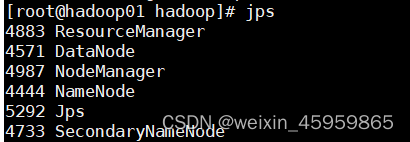
12、通过jps查询会出现6个进程 (我自己在查看这个是时候,就有一个没有启动成功,可能是配置文件时候,输入错误,也有可能是电脑自身的运行内存不足,其中NodeManager没有启动成功就有可能是没有达到最低运行的内存,要是遇到了这种错误,修改一下就可以的,大家可以自行百度)