
热门标签
热门文章
- 1C语言基础知识理论版(很详细)_c语言的理论
- 2最新 | Ask Me Anything 一种提示(Prompt)语言模型的简单策略(斯坦福大学 & 含源码)_llm prompt
- 3聚类篇——(二)K-means聚类_kmeans聚类问题描述
- 4【C/C++】【学生成绩管理系统】深度剖析
- 5TTS 语音合成技术学习
- 6独立开发变现周刊(第119期):一个自学开发者创建一个月收入12.5万美元的软件公司...
- 7Python_tkinter(按钮,文本框,多行文本组件)_tkinter button边上加字
- 8Redis进阶 - 朝生暮死之Redis过期策略_redis 定时 过期
- 9Git -- reset 详解_git reset 文件
- 10李宏毅2023机器学习作业HW06解析和代码分享
当前位置: article > 正文
Hive学习
作者:Guff_9hys | 2024-06-30 11:01:42
赞
踩
Hive学习
目录
9.3.1 SQL语句转换成MapReduce作业的基本原理
9.3.2 Hive中SQL查询转换成MapReduce作业的过程
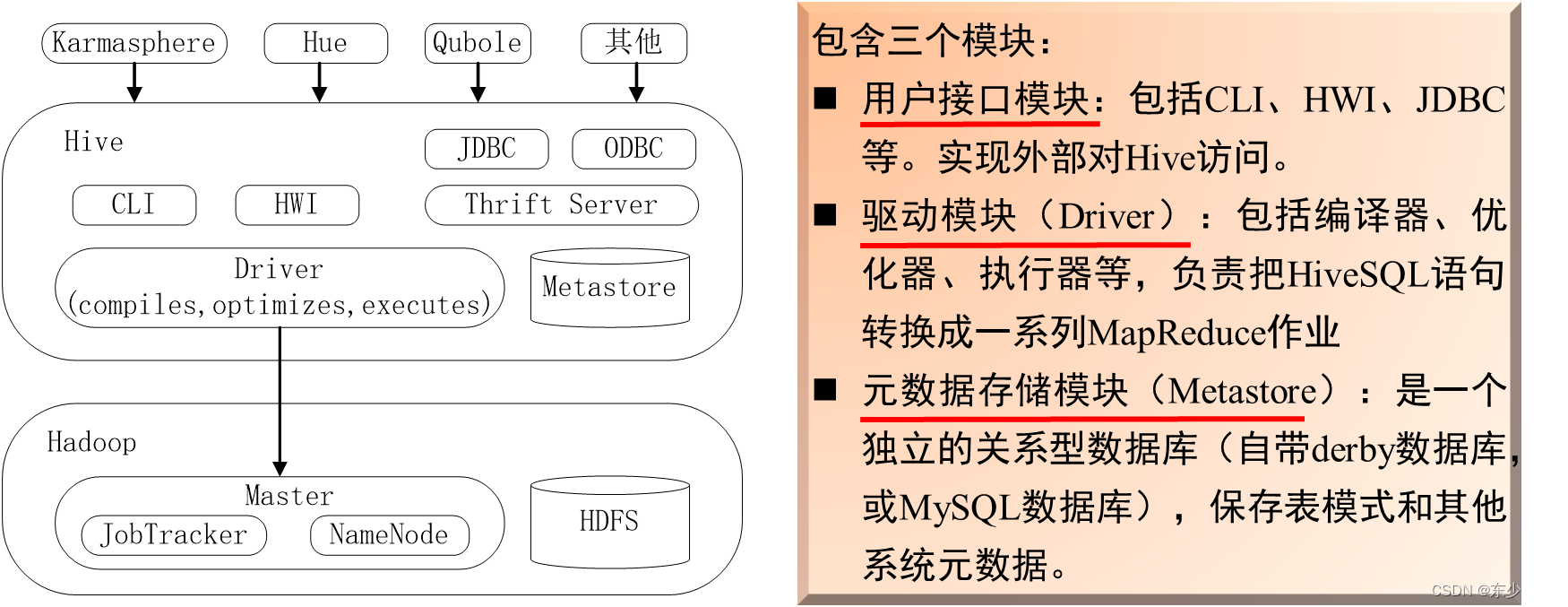
9.2 Hive系统架构
9.3 Hive工作原理
Hive执行引擎可以是MapReduce、Tez或Spark,这里只介绍MapReduce作为执行引擎时的Hive工作原理。主要包括下面两个内容:
9.3.1 SQL语句转换成MapReduce作业的基本原理



9.3.2 Hive中SQL查询转换成MapReduce作业的过程
当用户向
Hive
输入一段命令或查询时,
Hive
需要与
Hadoop
交互工作来完成该操作
:
Ø
驱动模块
接收该
命令或查询编译器
Ø
对该
命令或查询进行解析编译
Ø
由
优化器对
该
命令或查询进行优化计算
Ø
该
命令或查询通过执行器进行
执行

几点说明:
当启动
MapReduce
程序时,
Hive
本身是不会生成
MapReduce
算法程序的
需要通过一个表示“
Job
执行计划”的
XML
文件驱动执行内置的、原生的
Mapper
和
Reducer
模块
Hive
通过和
JobTracker
通信来初始化
MapReduce
任务,不必直接部署在
JobTracker
所在的管理节点上执行
通常在大型集群上,会有专门的网关机来部署
Hive
工具。网关机的作用主要是远程操作和管理节点上的
JobTracker
通信来执行任务
数据文件通常存储在
HDFS
上,
HDFS
由
名称
节点管理
9.4 Hive HA基本原理

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/772458
推荐阅读
相关标签

