
- 1spark为什么比mapreduce快?_下面哪些是spark比mapreduce计算快的原因(4分) a 基于内存的计算 b 基于dag的调
- 2Android 进阶——常用的Base64编码算法和MD5 信息摘要算法详解_android md5
- 3使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署
- 4LLM 大模型实用指南 | The Practical Guides for Large Language Models_ret-llm: towards a general read-write memory for l
- 5activemq的优势_【消息队列】1-为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?...
- 6数据结构之B树
- 7智能新时代的天津故事
- 8谷歌插件市场
- 9请求限流算法有哪些?分别面向什么应用场景?_对用户请求限流
- 10华为OD机试C卷-- 贪吃的猴子(Java & JS & Python & C)
Python课设——豆瓣top250
赞
踩
| 学院名称: | |
| 专业班级: | |
| 专 业: | |
| 学 号: | |
| 学生姓名: | |
| 指导教师: |
豆瓣电影Top250
摘要:
随着当今社会的飞速发展,处于大数据时代下的我们而言,信息的采集是一项非常重要的工作。而数据是大部分信息的载体,所以数字的使用价值对人们来说已经起到举足轻重的作用了。
想要从成万上亿条数据中提取我们需要的几百条或者几十条数据,要是没有计算机相关语言的支持就显得那么的不可能。通过本学期对python语言的学习了解到,利用python中爬虫的部分就可以得到我们需要的相关数据。
网络爬虫又称为网页蜘蛛,网络机器人,它是按照一定的规则自动地爬取万维网信息得到程序脚本。如果把网络比作一张网,那么爬虫就是其上的一只虫子,它在网上爬行的过程中采集网络中的数据。
本次项目将对豆瓣网排名250的电影相关数据进行了爬取,将其数据处理分析和进行相关的可视化操作。
目录
- 项目描述---------------------------------------4
- 项目设计分析-----------------------------------4
2.1开发工具------------------------------------4
2.2需求分析------------------------------------5
2.3平台情况介绍--------------------------------5
2.4项目流程图----------------------------------7
- 获取数据---------------------------------------7
3.1爬取数据------------------------------------7
3.1.1网页请求-------------------------------7
3.1.2获取每页25部电影数据------------------8
3.1.3获取每部电影具体信息-------------------8
3.2保存数据------------------------------------9
- 实现可视化-------------------------------------10
4.1折线图-------------------------------------10
4.2重叠折线图---------------------------------10
4.3条形图-------------------------------------11
4.4水平条形图---------------------------------12
4.5饼图---------------------------------------13
4.6柱状图-------------------------------------14
4.7直方图-------------------------------------15
- 项目全部代码展示------------------------------16
- 个人总结--------------------------------------21
1,项目描述
豆瓣网电影排名的相关信息都属于静态的数据,而非动态的。本次项目将对豆瓣网电影排名前250名的电影信息进行爬取,如:电影名称,上映年份,豆瓣评分,点评人数这四个方向的信息进行获取,整理,分析。
将获取得到的数据进一步的加工处理,使用python语言中的一些可视化模块,如:numpy,matplotlib.pyplot等将数据进行可视化操作,使数据以更加直观的形式呈现在人们面前,从而更容易让客户快速得到有用的信息。
极大地提高了资源的使用,时间的节约,还可以很好地满足一些特殊人群对电影行业领域信息的需求。
- 项目设计分析
由于本次项目需要对电影相关数据的获取,筛选,分析等操作。所以需要使用到一些工具和其他的支持。
2.1开发工具
解释器:python3.9
使用到的相关库:
Pandas --------------------- 读取表格数据
Re --------------------- 正则表达
Requests -------------------网页爬取数据
Matplotlib.pyplot------------实现可视化
数据存储:excel表格
2.2需求分析
提取豆瓣网前250名电影的电影名称,上映年份,豆瓣评分,点评人数等信息,将数据进行整理。
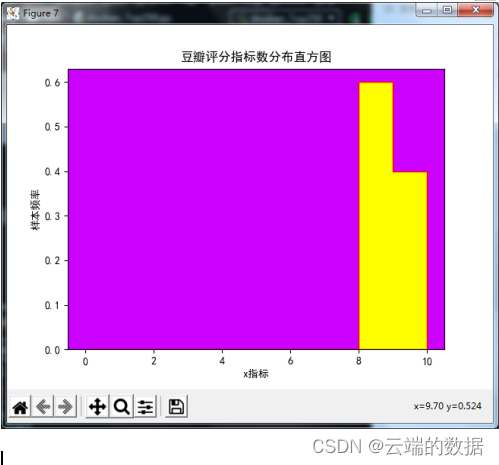
用折线图实现排名前十的电影上映时间按照时间的升序排列;折线图实现排名前十和前二十豆瓣平分的比较;条形图实现排名前十电影的评分比较;水平条形图实现每隔十年电影上映数量的比较;饼图实现近二十年来上映的电影占250部中的比;水平直方图实现评分前十的点评人数;饼图,实现前十点评人数占比;直方图,豆瓣评分指标。
2.3平台情况介绍
打开豆瓣电影网页:豆瓣电影 Top 250 (douban.com),可以看到TOP-250榜单共10页数据:
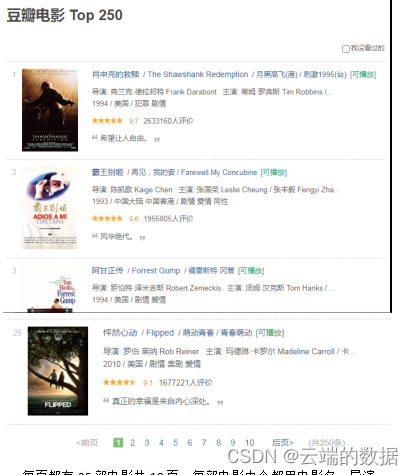
每页都有25部电影共10页,每部电影中个都用电影名,导演,主演,上映时间,地点,点评人数,豆瓣评分等信息。
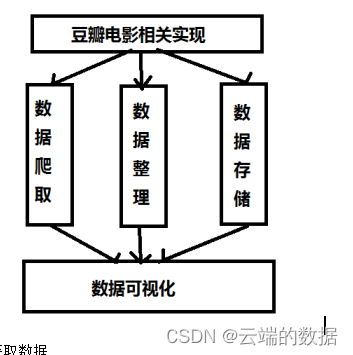
2.4项目流程
3.数据获取
3.1爬取数据
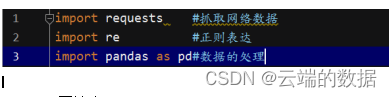
在爬取数据前需要在python窗口中导入相关模块:
3.1.1页面请求
伪装页面:

网页的请求:

3.1.2获取每页25部电影数据
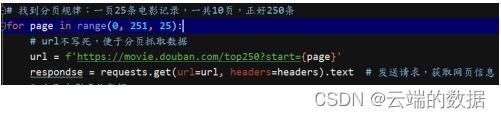
Respondes不是python中的库文件,而是一个用于响应返回的对象。
3.1.3获取每部电影具体信息
电影连接在每一个<li>列表标签的<a>标签中:
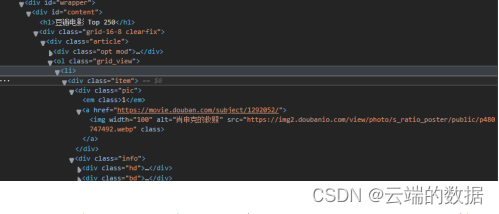
获取得到相关的电影名称,上映年份,豆瓣评分,点评人数数据,下列相关代码截图:
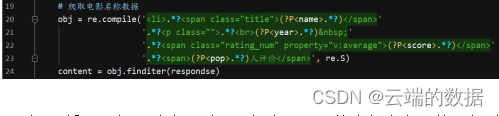
通过for循环语句可以遍历到250部电影需要的全部内容,获取得到的数据后将数据进行进一步的操作整理得到我们需要的比较完整的数据,相关代码如下: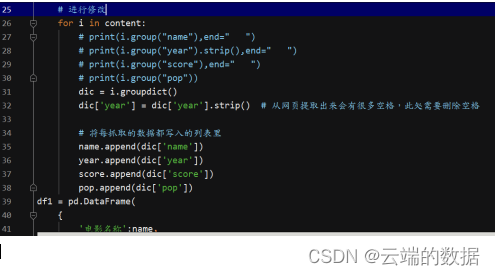
3.2保存数据
将上面整理好的250条数据保存到excel表格中,相关代码截图如下:

- 实现可视化
在实现可视化中需要将一些特殊字符,汉子可视化为他们原来的样子,所以添加两条语句。
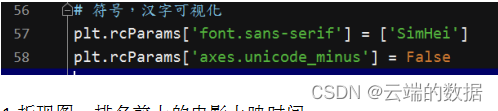
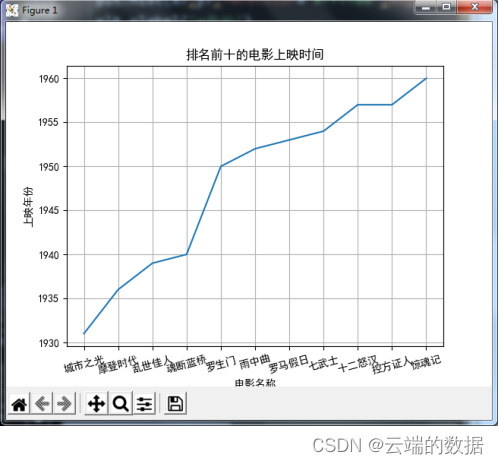
4.1折现图,排名前十的电影上映时间
实现:
代码:
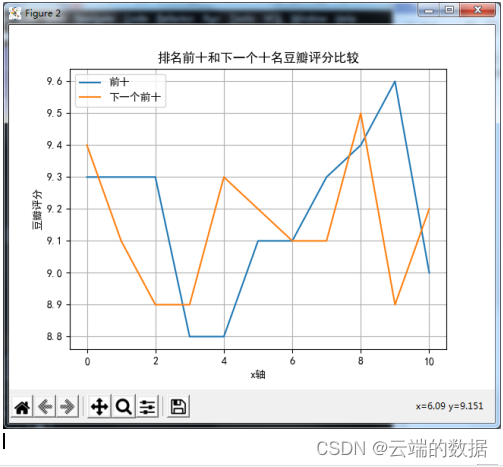
4.2折线图,排名前十和前二十豆瓣评分比较
实现:
代码:

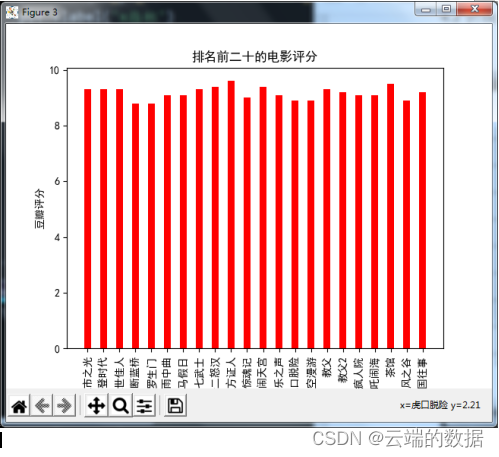
4.3条形图,排名前二十的电影评分
实现:
代码:

4.4水平条形图,每隔十年电影上映数的比较
实现:
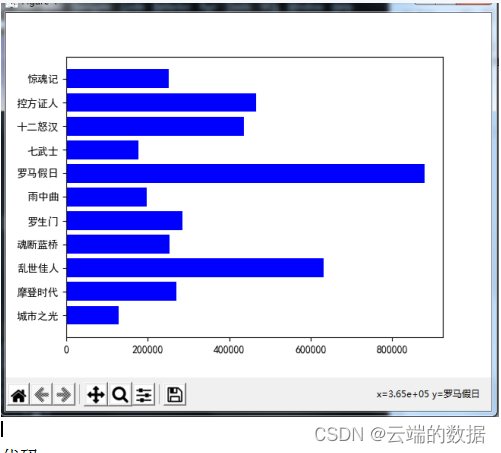
代码:

4.5饼图,前十电影点评人数占比
实现:
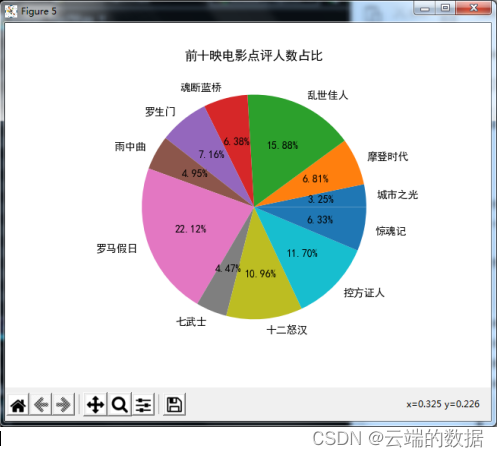
代码:
4.6散点图,
全部电影点评人数
实现:
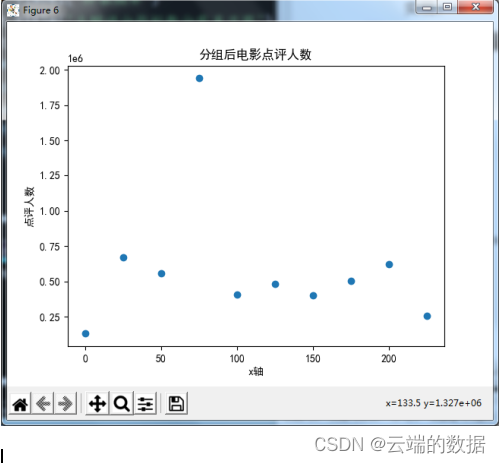
代码:
4.7直方图,豆瓣评分指标
实现:
代码:

- 项目全部代码展示
- import requests #抓取网络数据
-
- import re #正则表达
-
- import pandas as pd#数据的处理
-
- import matplotlib.pyplot as plt
-
- from wordcloud import WordCloud
-
- import numpy as np
-
- # 创建空列表用于存放 数据
-
- name =[]
-
- year =[]
-
- score =[]
-
- pop = []
-
- # 伪装网页
-
- headers = {"User-Agent":
-
- "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"}
-
- #解析数据
-
- # 找到分页规律:一页25条电影记录,一共10页,正好250条
-
- for page in range(0, 251, 25):
-
- # url不写死,便于分页抓取数据
-
- url = f'https://movie.douban.com/top250?start={page}'
-
- respondse = requests.get(url=url, headers=headers).text # 发送请求,获取网页信息
-
- # 爬取电影名称数据
-
- obj = re.compile('<li>.*?<span class="title">(?P<name>.*?)</span>'
-
- '.*?<p class="">.*?<br>(?P<year>.*?) '
-
- '.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
-
- '.*?<span>(?P<pop>.*?)人评价</span>', re.S)
-
- content = obj.finditer(respondse)
-
- # 进行修改
-
- for i in content:
-
- # print(i.group("name"),end=" ")
-
- # print(i.group("year").strip(),end=" ")
-
- # print(i.group("score"),end=" ")
-
- # print(i.group("pop"))
-
- dic = i.groupdict()
-
- dic['year'] = dic['year'].strip() # 从网页提取出来会有很多空格,此处需要删除空格
-
-
-
- # 将每抓取的数据都写入的列表里
-
- name.append(dic['name'])
-
- year.append(dic['year'])
-
- score.append(dic['score'])
-
- pop.append(dic['pop'])
-
- df1 = pd.DataFrame(
-
- {
-
- '电影名称':name,
-
- '上映年份':year,
-
- '豆瓣评分':score,
-
- '点评人数':pop
-
- }
-
- )
-
- #将其写入excel表格中
-
- df1.to_excel(r'F:\Sophomore\Python\作业\爬虫.xlsx')# 保存excel
-
-
-
- # #读取excel表中数据实现可视化
-
- df = pd.read_excel(r"F:\Sophomore\Python\作业\豆瓣Top_250.xlsx", engine='openpyxl')
-
- # print(df.index,df.columns)
-
-
-
- # 符号,汉字可视化
-
- plt.rcParams['font.sans-serif'] = ['SimHei']
-
- plt.rcParams['axes.unicode_minus'] = False
-
-
-
- # 按照上映时间排序
-
- df2 = df.sort_values(by=['上映年份'],inplace=False,ascending=True)
-
-
-
- # 折线图,排名前十的电影上映时间
-
- plt.figure(1)
-
- x = df2[0:11:1]['电影名称']
-
- y = df2[0:11:1]['上映年份']
-
- plt.plot(x,y)
-
- plt.title("排名前十的电影上映时间")
-
- plt.xticks(rotation=15)#倾斜45度
-
- plt.xlabel('电影名称');plt.ylabel('上映年份')
-
- plt.grid()
-
- plt.show()
-
-
-
- # 折线图,排名前十和前二十豆瓣评分比较
-
- plt.figure(2)
-
- x2 = range(0,11,1)
-
- y2 = df2[0:11:1]['豆瓣评分']
-
- y22 = df2[11:22:1]['豆瓣评分']
-
- plt.plot(x2,y2,x2,y22)
-
- plt.title('排名前十和下一个十名豆瓣评分比较')
-
- plt.xlabel('x轴');plt.ylabel('豆瓣评分')
-
- plt.legend(['前十','下一个前十'])
-
- plt.grid()
-
- plt.show()

- 个人总结
通过本学期的python学习,了解了很多以前没有了解过的知识点。数据不仅可以直接传递信息,在程序员手里可以将其变为更加直接的形式展示在客户面前。
Matplotlib是python中用于画图的工具之一,python强大的库中承载了许许多多的用于不同领域的库,使用起来更加简洁方便,其中让我感受最深的是python中的爬取数据的功能,可以将其他非数字语言经过一些形式的处理后保存在数据库或者保存在excel表格中,起到整理数据的作用,便于特殊人员将数据最大化的使用。
在本学期的学习过程中收获颇多,希望在今后的学习上继续保持本学期的学习精神。

