
热门标签
热门文章
- 1CCF稀疏向量100分代码(利用输入的顺序,使用队列巧解)_ccfint a[100][100]
- 2Pytorch - CNN、RNN、GRU 分类_pytorch中gru时间序列分类
- 3讲解Canvas中的一些重要方法
- 4模型压缩整理2020.5.6_sparsity ratio
- 5手机运营商二要素验证接口:确保业务操作安全可靠_手机运营商二要素验证接口:确保业务操作安全可靠
- 6基于FPGA的计算器(含源码)_基于fpga的多功能计算器的设计
- 7Java中的内部类(如果想知道Java中有关内部类的知识点,那么只看这一篇就足够了!)
- 8SpringBoot系列之搭建WebSocket应用_spring boot 开放websocket
- 9【重点突破】—— React应用中封装axios(转),2024年最新腾讯+华为+阿里面试真题分享_axios react
- 10基于java中的springboot框架实现智慧图书管理系统设计演示【附项目源码+论文说明】_图书管理系统javaspringboot
当前位置: article > 正文
yolov8实例分割Tensorrt部署C++代码,engine模型推理示例和代码详解_c++模型推理实例代码
作者:Gausst松鼠会 | 2024-06-16 04:02:53
赞
踩
c++模型推理实例代码
接上文中的yolov8-aeg实例分割onnx转engine部分代码详解。本文对yolov8seg实例分割推理部分代码进行详细解不,此部分与常见的不同,后处理部分主要以矩阵处理为主。通过代码注释和示例运行,帮助大家理解和使用。
代码
文件夹内容如下。
主要包括主程序infer_main.cpp和用到的logging.h、utilus.h。其中logging.h在前篇博客已经讲过,附有代码,可参阅yolov8-aeg实例分割onnx转engine部分代码详解。utilus.h中仅包含两个函数的定义,比较简单不做赘述,可看相应代码。此处主要对含有预处理、推理和后处理等过程的infer_main.cpp代码进行解读,通过每行注释等形式。
infer_main.cpp
此代码为推理的主代码,包括预处理、推理和后处理等过程。
#include "NvInfer.h" #include "cuda_runtime_api.h" #include "NvInferPlugin.h" #include "logging.h" #include <opencv2/opencv.hpp> #include "utils.h" #include <string> using namespace nvinfer1; using namespace cv; // stuff we know about the network and the input/output blobs static const int INPUT_H = 640; static const int INPUT_W = 640; static const int _segWidth = 160; static const int _segHeight = 160; static const int _segChannels = 32; static const int CLASSES = 80; static const int Num_box = 8400; //输出的尺寸大小,8400*(80+4+32),32是掩码,4是box,classes是每个目标的分数,yolov8把置信度和分数二合一了 static const int OUTPUT_SIZE = Num_box * (CLASSES+4 + _segChannels);//output0 //分割的输出头尺寸大小,输出是32*160*160 static const int OUTPUT_SIZE1 = _segChannels * _segWidth * _segHeight ;//output1 //置信度阈值 static const float CONF_THRESHOLD = 0.1; //nms阈值 static const float NMS_THRESHOLD = 0.5; //mask阈值 static const float MASK_THRESHOLD = 0.5; //输入结点名称 const char* INPUT_BLOB_NAME = "images"; //检测头的输出结点名称 const char* OUTPUT_BLOB_NAME = "output0";//detect //分割头的输出结点名称 const char* OUTPUT_BLOB_NAME1 = "output1";//mask struct OutputSeg { int id; //结果类别id float confidence; //结果置信度 cv::Rect box; //矩形框 cv::Mat boxMask; //矩形框内mask,节省内存空间和加快速度 }; //output中,包含了经过处理的id、conf、box和maskiamg信息 void DrawPred(Mat& img,std:: vector<OutputSeg> result) { //生成随机颜色 std::vector<Scalar> color; //这行代码的作用是将当前系统时间作为随机数种子,使得每次程序运行时都会生成不同的随机数序列。 srand(time(0)); //根据类别数,生成不同的颜色 for (int i = 0; i < CLASSES; i++) { int b = rand() % 256; int g = rand() % 256; int r = rand() % 256; color.push_back(Scalar(b, g, r)); } Mat mask = img.clone(); for (int i = 0; i < result.size(); i++) { int left, top; left = result[i].box.x; top = result[i].box.y; int color_num = i; //画矩形框,颜色是上面选的 rectangle(img, result[i].box, color[result[i].id], 2, 8); //将box中的result[i].boxMask区域涂成color[result[i].id]颜色 mask(result[i].box).setTo(color[result[i].id], result[i].boxMask); char label[100]; //建立打印信息标签:置信度 //将格式化的字符串保存到label字符串中。 sprintf(label, "%d:%.2f", result[i].id, result[i].confidence); //std::string label = std::to_string(result[i].id) + ":" + std::to_string(result[i].confidence); int baseLine; //获取标签文本的尺寸 Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine); //确定一个最大的高 top = max(top, labelSize.height); //把文本信息加到图像上 putText(img, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 1, color[result[i].id], 2); } //用于对图像的加权融合 //图像1、图像1权重、图像2、图像2权重,添加结果中的标量、输出图像 addWeighted(img, 0.5, mask, 0.8, 1, img); //将mask加在原图上面 } static Logger gLogger; //输入引擎文本、图像数据、定义的检测输出和分割输出、1 void doInference(IExecutionContext& context, float* input, float* output, float* output1, int batchSize) { //从上下文中获取一个CUDA引擎。这个引擎加载了一个深度学习模型 const ICudaEngine& engine = context.getEngine(); //判断该引擎是否有三个绑定 assert(engine.getNbBindings() == 3); //定义了一个指向void的指针数组,用于存储GPU缓冲区的地址 void* buffers[3]; //获取输入和输出blob的索引,这些索引用于之后的缓冲区操作 const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME); const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME); const int outputIndex1 = engine.getBindingIndex(OUTPUT_BLOB_NAME1); // 使用cudaMalloc分配了GPU内存。这些内存将用于存储模型的输入和输出 CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 3 * INPUT_H * INPUT_W * sizeof(float)));// CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float))); CHECK(cudaMalloc(&buffers[outputIndex1], batchSize * OUTPUT_SIZE1 * sizeof(float))); //创建一个CUDA流。CUDA流是一种特殊的并发执行环境,可以在其中安排任务以并发执行。流使得任务可以并行执行,从而提高了GPU的利用率。 cudaStream_t stream; //判断是否创建成功 CHECK(cudaStreamCreate(&stream)); // 使用cudaMemcpyAsync将输入数据异步地复制到GPU缓冲区。这个操作是非阻塞的,意味着它不会立即完成。 CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream)); //将输入和输出缓冲区以及流添加到上下文的执行队列中。这将触发模型的推理。 context.enqueue(batchSize, buffers, stream, nullptr); //使用cudaMemcpyAsync函数将GPU上的数据复制到主内存中。这是异步的,意味着该函数立即返回,而数据传输可以在后台进行。 CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream)); CHECK(cudaMemcpyAsync(output1, buffers[outputIndex1], batchSize * OUTPUT_SIZE1 * sizeof(float), cudaMemcpyDeviceToHost, stream)); //等待所有在给定流上的操作都完成。这可以确保在释放流和缓冲区之前,所有的数据都已经被复制完毕。 //这对于保证内存操作的正确性和防止数据竞争非常重要。 cudaStreamSynchronize(stream); //释放内存 cudaStreamDestroy(stream); CHECK(cudaFree(buffers[inputIndex])); CHECK(cudaFree(buffers[outputIndex])); CHECK(cudaFree(buffers[outputIndex1])); } int main(int argc, char** argv) { //在终端输入engine模型和测试图像 //如果终端没有输入完整,则通过下列路径获取 if (argc < 2) { argv[1] = "../models/yolov8n-seg.engine"; argv[2] = "../images/bus.jpg"; } // create a model using the API directly and serialize it to a stream //定义一个指针变量,通过trtModelStream = new char[size];分配size个字符的空间 //nullptr表示指针针在开始时不指向任何有效的内存地址,空指针 char* trtModelStream{ nullptr }; //无符号整型类型,通常用于表示对象的大小或计数 //{ 0 }: 这是初始化列表,用于初始化 size 变量。在这种情况下,size 被初始化为 0。 size_t size{ 0 }; //打开文件,即engine模型 std::ifstream file(argv[1], std::ios::binary); if (file.good()) { std::cout << "load engine success" << std::endl; //指向文件的最后地址 file.seekg(0, file.end); //计算文件的长度 size = file.tellg(); //指回文件的起始地址 file.seekg(0, file.beg); //为trtModelStream指针分配内存,内存大小为size trtModelStream = new char[size];//开辟一个char 长度是文件的长度 assert(trtModelStream);// //把file内容传递给trtModelStream,传递大小为size,即engine模型内容传递 file.read(trtModelStream, size); //关闭文件 file.close(); } else { std::cout << "load engine failed" << std::endl; return 1; } //读取图像 Mat src = imread(argv[2], 1); //若无图像,则出错 if (src.empty()) { std::cout << "image load faild" << std::endl; return 1; } //获取原图像的宽和高 int img_width = src.cols; int img_height = src.rows; std::cout << "宽高:" << img_width << " " << img_height << std::endl; // Subtract mean from image //定义一个静态浮点数组 //静态意味着这个数组在程序的生命周期内一直存在,而不是只在函数调用时存在 static float data[3 * INPUT_H * INPUT_W]; //定义两个图像 Mat pr_img0, pr_img; //定义一个int容器 std::vector<int> padsize; //图像预处理,输入的是原图像和网络输入的高和宽,填充尺寸容器 //输出的是重构后的图像,以及每条边填充的大小保存在padsize pr_img = preprocess_img(src, INPUT_H, INPUT_W, padsize); // Resize //重构后图像的高和宽,以及高和宽各边填充的边界 int newh = padsize[0], neww = padsize[1], padh = padsize[2], padw = padsize[3]; //后于后面恢复的放大倍数 float ratio_h = (float)src.rows / newh; float ratio_w = (float)src.cols / neww; int i = 0;// [1,3,INPUT_H,INPUT_W] //std::cout << "pr_img.step" << pr_img.step << std::endl; // for (int row = 0; row < INPUT_H; ++row) { //逐行对象素值和图像通道进行处理 //pr_img.step=widthx3 就是每一行有width个3通道的值 //第row行 uchar* uc_pixel = pr_img.data + row * pr_img.step; for (int col = 0; col < INPUT_W; ++col) { //第col列 //提取第第row行第col列数据进行处理 //像素值处理 data[i] = (float)uc_pixel[2] / 255.0; //通道变换 data[i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0; data[i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.; uc_pixel += 3;//表示进行下一列 ++i;//表示在3个通道中的第i个位置,rgb三个通道的值是分开的,如r123456g123456b123456 } } //创建了一个Inference运行时环境,返回一个指向新创建的运行时环境的指针 IRuntime* runtime = createInferRuntime(gLogger); assert(runtime != nullptr); //初始化NVIDIA的Infer插件库 bool didInitPlugins = initLibNvInferPlugins(nullptr, ""); //反序列化一个CUDA引擎。这个引擎将用于执行模型的前向传播 ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr); assert(engine != nullptr); //使用上一步中创建的引擎创建一个执行上下文。这个上下文将在模型的前向传播期间使用 IExecutionContext* context = engine->createExecutionContext(); assert(context != nullptr); //释放了用于存储模型序列化的内存 delete[] trtModelStream; // Run inference //定义两个静态浮点,用于保存两个输出头的输出结果 static float prob[OUTPUT_SIZE]; static float prob1[OUTPUT_SIZE1]; auto start = std::chrono::system_clock::now(); //进行推理 //输入引擎文本、图像数据、定义的检测输出和分割输出、bs //返回的是输出1和输出2 doInference(*context, data, prob, prob1, 1); auto end = std::chrono::system_clock::now(); std::cout << "推理时间:" << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl; //用于保存目标框的信息 std::vector<int> classIds;//保存目标类别id std::vector<float> confidences;//置信度 std::vector<cv::Rect> boxes;//每个id矩形框 std::vector<cv::Mat> picked_proposals; //mask // 处理box int net_length = CLASSES + 4 + _segChannels; //定义一个矩阵,把prob中的数据重构为116*8400 cv::Mat out1 = cv::Mat(net_length, Num_box, CV_32F, prob); start = std::chrono::system_clock::now(); for (int i = 0; i < Num_box; i++) { //输出是1*net_length*Num_box;所以每个box的属性是每隔Num_box取一个值,共net_length个值 //左上角(i,4)宽1高classes,即冲116个数据中提取80个类别的分数 cv::Mat scores = out1(Rect(i, 4, 1, CLASSES)).clone(); // Point classIdPoint; double max_class_socre; //原矩阵、按行查找,0表示全矩阵,最大值的值,按列查找,0表示全矩阵,最大点的位置 minMaxLoc(scores, 0, &max_class_socre, 0, &classIdPoint); max_class_socre = (float)max_class_socre; //如果最大分数大于置信度,则进行下一步处理 //保存符合置信度的目标信息,确定出类别和置信度,即通过80个类别分数,确定目标类别 if (max_class_socre >= CONF_THRESHOLD) { //提取该目标框的32个mask cv::Mat temp_proto = out1(Rect(i, 4 + CLASSES, 1, _segChannels)).clone(); //.t是转置操作 picked_proposals.push_back(temp_proto.t()); //尺寸重构,减去填充的尺度,乘以放大因子 float x = (out1.at<float>(0, i) - padw) * ratio_w; //cx float y = (out1.at<float>(1, i) - padh) * ratio_h; //cy float w = out1.at<float>(2, i) * ratio_w; //w float h = out1.at<float>(3, i) * ratio_h; //h //坐标变换,变为左上角和宽高 int left = MAX((x - 0.5 * w), 0); int top = MAX((y - 0.5 * h), 0); int width = (int)w; int height = (int)h; if (width <= 0 || height <= 0) { continue; } //符合要求,则保存类别id classIds.push_back(classIdPoint.y); //保存置信度 confidences.push_back(max_class_socre); //保存框 boxes.push_back(Rect(left, top, width, height)); } } //进行非极大值抑制NMS std::vector<int> nms_result; //通过opencv自带的nms函数进行,矩阵box、置信度大小,置信度阈值,nms阈值,结果 cv::dnn::NMSBoxes(boxes, confidences, CONF_THRESHOLD, NMS_THRESHOLD, nms_result); std::vector<cv::Mat> temp_mask_proposals; //包括类别、置信度、框和mask std::vector<OutputSeg> output; //创建一个名为holeImgRect的Rect对象 Rect holeImgRect(0, 0, src.cols, src.rows); //提取经过非极大值抑制后的结果 for (int i = 0; i < nms_result.size(); ++i) { int idx = nms_result[i]; OutputSeg result; result.id = classIds[idx]; result.confidence = confidences[idx]; result.box = boxes[idx]& holeImgRect; output.push_back(result); //32个mask temp_mask_proposals.push_back(picked_proposals[idx]); } // 处理mask Mat maskProposals; for (int i = 0; i < temp_mask_proposals.size(); ++i) maskProposals.push_back(temp_mask_proposals[i]); //开始处理分割头的输出32*160*160 //把分割结果重构为32,160*160 Mat protos = Mat(_segChannels, _segWidth * _segHeight, CV_32F, prob1); //mask乘以分割head输出结果 Mat matmulRes = (maskProposals * protos).t();//n*32 32*25600 A*B是以数学运算中矩阵相乘的方式实现的,要求A的列数等于B的行数时 //形状重构 Mat masks = matmulRes.reshape(output.size(), { _segWidth,_segHeight });//n*160*160 std::vector<Mat> maskChannels; //将masks分割成多个通道,保存到maskChannels cv::split(masks, maskChannels); //确定一个边界,用于在160*160上截取没有填充区域的图像 Rect roi(int((float)padw / INPUT_W * _segWidth), int((float)padh / INPUT_H * _segHeight), int(_segWidth - padw / 2), int(_segHeight - padh / 2)); //处理和获得原始图像中改变像素点颜色的区域 for (int i = 0; i < output.size(); ++i) { Mat dest, mask; //进行sigmoid cv::exp(-maskChannels[i], dest); dest = 1.0 / (1.0 + dest); //截取相应区域,避免填充影响 dest = dest(roi); //把mask的大小重构到原始图像大小 resize(dest, mask, cv::Size(src.cols, src.rows), INTER_NEAREST); //crop----截取box中的mask作为该box对应的mask Rect temp_rect = output[i].box; //判断mask中box区域的值是否大于mask阈值,大于为true,小于为false //提取出mask中与temp_rect相交的部分,然后判断这部分的值是否大于预设的阈值MASK_THRESHOLD。结果保存在mask中 mask = mask(temp_rect) > MASK_THRESHOLD; //把掩码图像进行保存,大小和原图像大小一样,目标区域已经为true output[i].boxMask = mask; } end = std::chrono::system_clock::now(); std::cout << "后处理时间:" << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl; //output中,包含了经过处理的id、conf、box和maskiamg信息 DrawPred(src, output); cv::imshow("output.jpg", src); char c = cv::waitKey(0); // Destroy the engine context->destroy(); engine->destroy(); runtime->destroy(); system("pause"); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
utils.h
#pragma once #include <algorithm> #include <fstream> #include <iostream> #include <opencv2/opencv.hpp> #include <vector> #include <chrono> #include <cmath> #include <numeric> // std::iota using namespace cv; #define CHECK(status) \ do\ {\ auto ret = (status);\ if (ret != 0)\ {\ std::cerr << "Cuda failure: " << ret << std::endl;\ abort();\ }\ } while (0) struct alignas(float) Detection { //center_x center_y w h float bbox[4]; float conf; // bbox_conf * cls_conf int class_id; }; //图像预处理,输入的是原图像和网络输入的高和宽,填充尺寸容器 //输出重构后的图像 static inline cv::Mat preprocess_img(cv::Mat& img, int input_w, int input_h, std::vector<int>& padsize) { int w, h, x, y; float r_w = input_w / (img.cols*1.0); float r_h = input_h / (img.rows*1.0); if (r_h > r_w) { w = input_w; h = r_w * img.rows; x = 0; y = (input_h - h) / 2; } else { w = r_h * img.cols; h = input_h; x = (input_w - w) / 2; y = 0; } //h和w是重构后图像的高和宽 //xy是填充的边界 cv::Mat re(h, w, CV_8UC3); cv::resize(img, re, re.size(), 0, 0, cv::INTER_LINEAR); cv::Mat out(input_h, input_w, CV_8UC3, cv::Scalar(128, 128, 128)); re.copyTo(out(cv::Rect(x, y, re.cols, re.rows))); padsize.push_back(h); padsize.push_back(w); padsize.push_back(y); padsize.push_back(x);// int newh = padsize[0], neww = padsize[1], padh = padsize[2], padw = padsize[3]; return out; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
CmakeLists.txt
在这里插入代码片
- 1
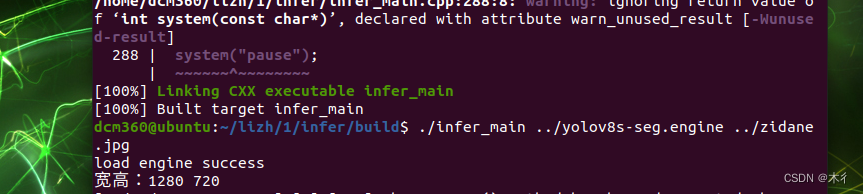
运行示例
打开文件夹终端,执行如下命令
mkdir build
cd build
cmake ..
make -j32
./main ../yolov8s-seg.engine ../zidane,jpg
- 1
- 2
- 3
- 4
- 5
上述中的j32,可根据自己配置调整其数值。运行结果如下所示:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/725071
推荐阅读
相关标签

