
- 1还不懂 ConcurrentHashMap ?这份源码分析了解一下_concurrenthashmap源码分析
- 2非常实用的log调试工具:logcat
- 3Springboot网上租车系统的设计与实现 计算机毕设源码64297_基于spring boot的车辆租赁管理系统设计与实现流程图
- 4分布式锁初探--redis锁_sessioncallback
sessioncallback = new ses - 5前端学习(20):无序列表_前段无序
- 6FPGA/IC秋招经典100题(含详解)_对11.916无损定点化
- 7使用hping3网络工具构造TCP/IP数据包和进行DDos攻击
- 8若将瑞星比Borland 刘旭略胜Anders_anders delphi4.0
- 9CSS知识点汇总(第三篇:为网页添加列表)_请简要描述,使用背景图像定义列表项目符号的好处。
- 10xxx cannot be cast to xxx_cannot cast xx to xx
github 视觉测量_计算机视觉八大任务全概述:PaddlePaddle工程师详解热门视觉模型...
赞
踩
来自百度的深度学习工程师,围绕计算机视觉领域的八大任务,包括:图像分类、目标检测、图像语义分割、场景文字识别、图像生成、人体关键点检测、视频分类、度量学习等,进行了较为详细的综述并形成此文。
这篇综述中,介绍了这些任务的基本情况,以及目前的技术进展、主要的模型和性能对比等。而且还逐一附上了GitHub传送门,用于更进一步的学习与安装实践指南。其中不少教程还是用中文写成,非常友好。
总之,这篇综述全程干货,推荐收藏阅读。
上篇
计算机视觉(Computer Vision)是研究如何使机器“看”的科学,更进一步的说,是使用摄像机机和电脑代替人眼对目标进行识别、跟踪和测量等的机器视觉,并通过电脑处理成为更适合人眼观察或传送给仪器检测的图像。
形象地说,就是给计算机安装上眼睛(摄像机)和大脑(算法),让计算机像人一样去看、去感知环境。计算机视觉技术作为人工智能的重要核心技术之一,已广泛应用于安防、金融、硬件、营销、驾驶、医疗等领域。本文上篇中,我们将介绍基于PaddlePaddle的四种计算机视觉技术及其相关的深度学习模型。
一、图像分类
图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉中重要的基础问题,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层视觉任务的基础。
图像分类在许多领域都有着广泛的应用。如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
得益于深度学习的推动,图像分类的准确率大幅度提升。在经典的数据集ImageNet上,训练图像分类任务常用的模型,包括AlexNet、VGG、GoogLeNet、ResNet、Inception-v4、MobileNet、MobileNetV2、DPN(Dual Path Network)、SE-ResNeXt、ShuffleNet等。
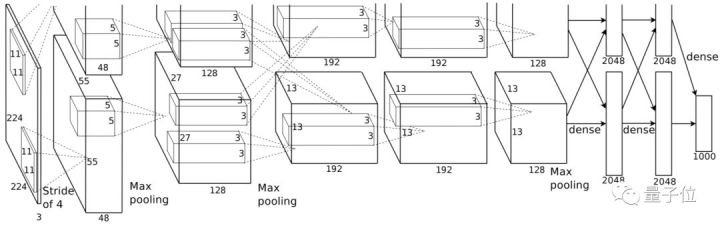
△ AlexNet
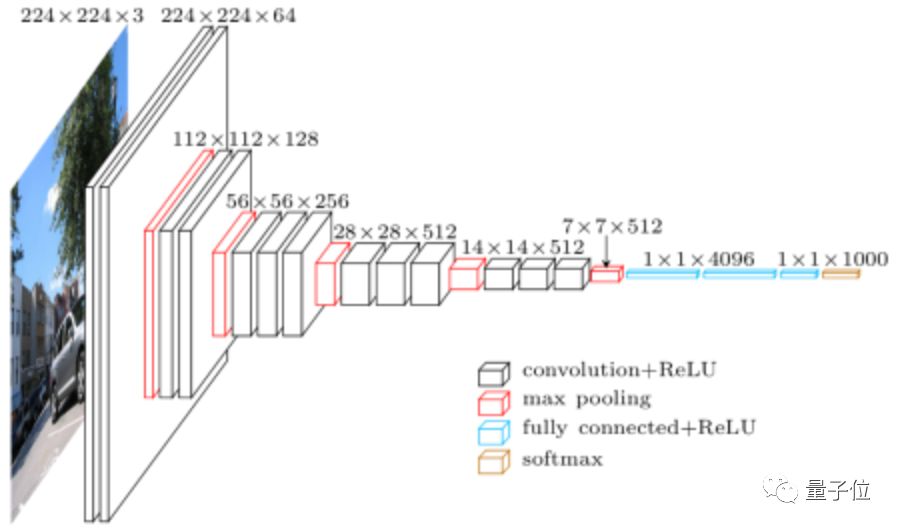
△ VGG
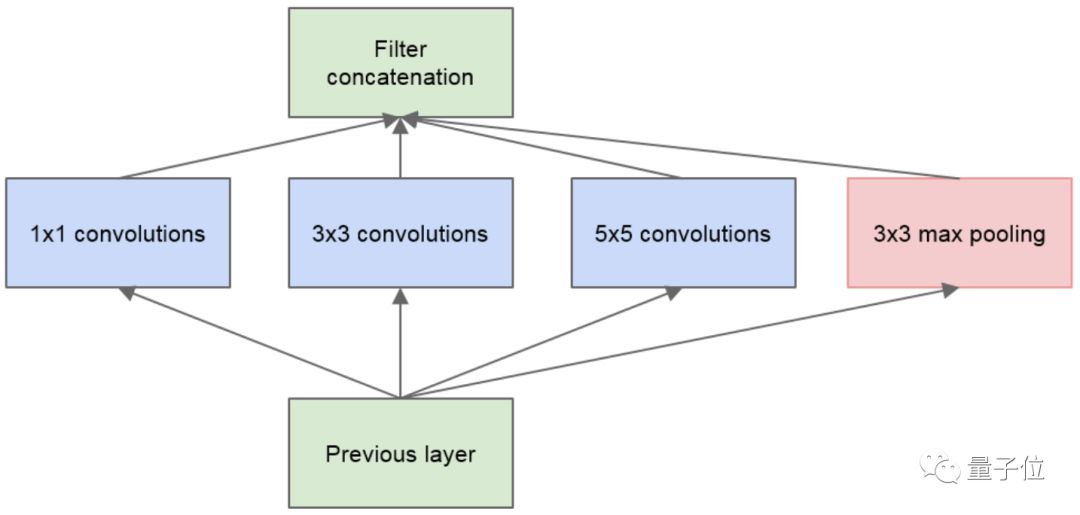
△ GoogLeNet
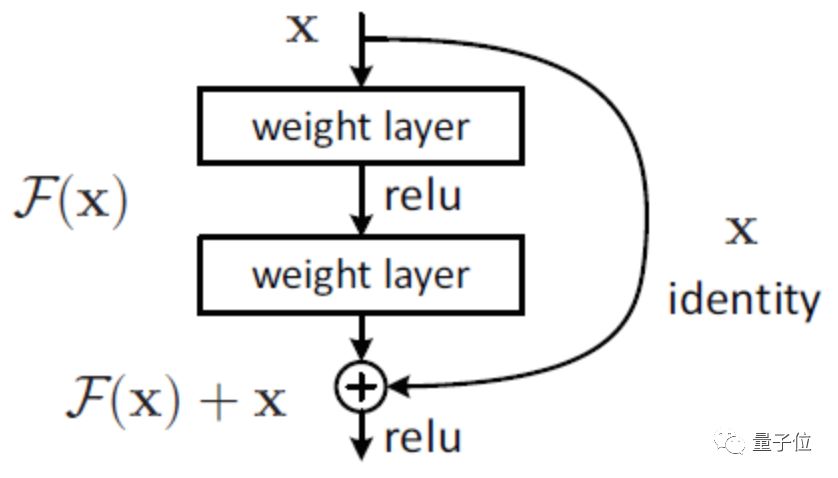
△ ResNet
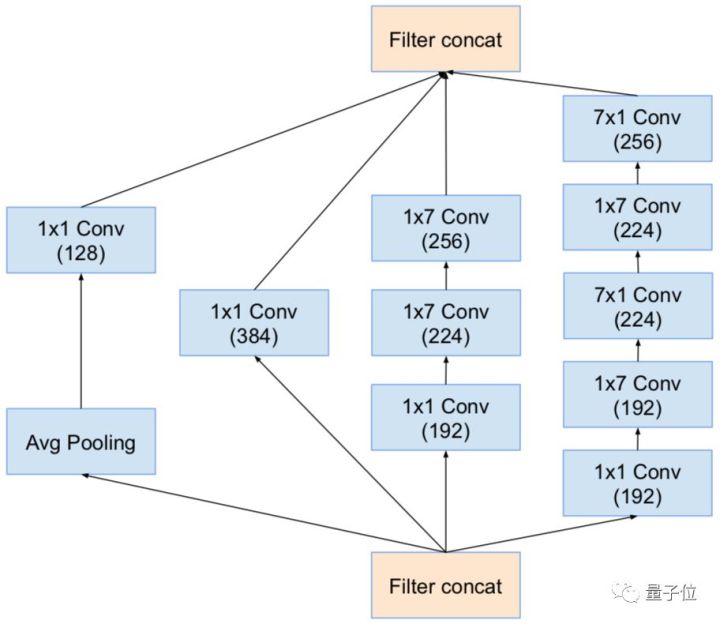
△ Inception-v4
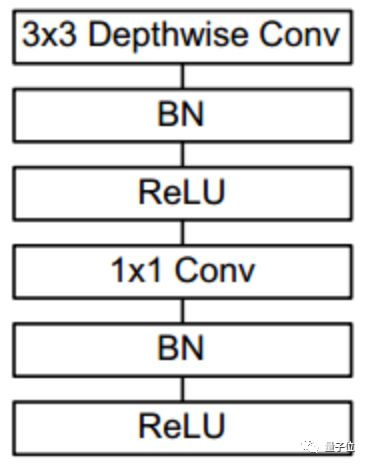
△ MobileNet
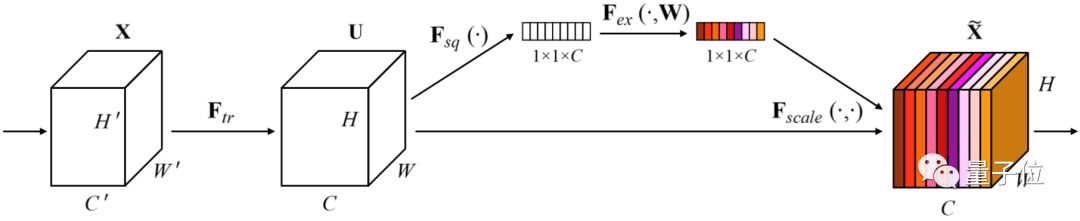
△ SE-ResNeXt

△ ShuffleNet
模型的结构和复杂程度都不一样,最终得到的准确率也有所区别。下面这个表格中,列出了在ImageNet 2012数据集上,不同模型的top-1/top-5验证准确率。
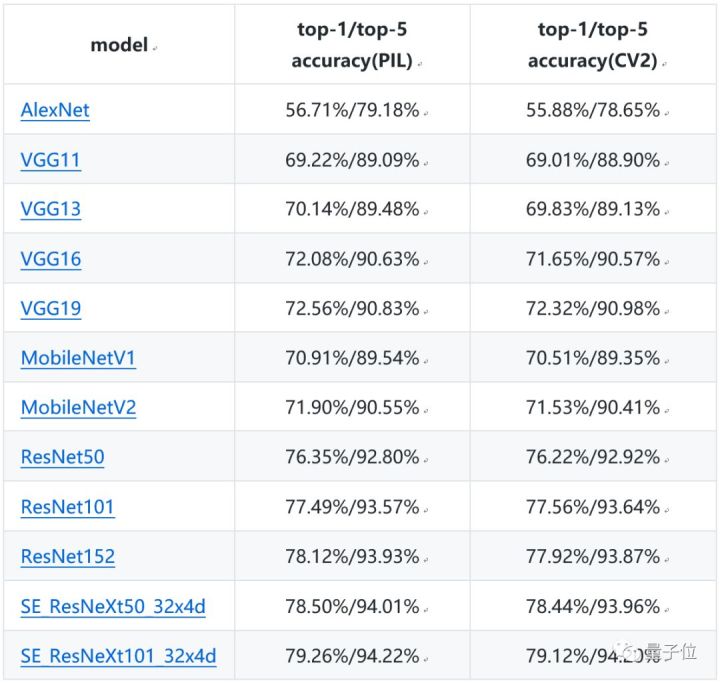
△ 图像分类系列模型评估结果
在我们的GitHub页面上,提供上述与训练模型的下载。以及详细介绍了如何使用PaddlePaddle Fluid进行图像分类任务。包括安装、数据准备、模型训练、评估等等全部过程。还有将Caffe模型转换为PaddlePaddle Fluid模型配置和参数文件的工具。
上述页面的传送门在此:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/image_classification

二、目标检测
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。
对于人类来说,目标检测是一个非常简单的任务。然而,计算机能够“看到”的是图像被编码之后的数字,很难解图像或是视频帧中出现了人或是物体这样的高层语义概念,也就更加难以定位目标出现在图像中哪个区域。
与此同时,由于目标会出现在图像或是视频帧中的任何位置,目标的形态千变万化,图像或是视频帧的背景千差万别,诸多因素都使得目标检测对计算机来说是一个具有挑战性的问题。
在目标检测任务中,我们主要介绍如

