
- 1MySQL从零开始 6-表约束之空属性,默认值default,列描述comment以及零填充zerofill_zerofill null default null comment '' after type a
- 2【论文翻译】Graph Neural Networks: a review of methods and applications 图神经网络综述:方法和应用
- 3linux下离线安装gcc4.9.3过程(附链接及依赖文件)_离线安装gcc-4.9
- 4鸿蒙初体验_鸿蒙4.0 设备安装路径要和项目路径一致么
- 5Prompt提示词——常见的Prompt框架
- 6linux下生成高强度密码的四大神器_来个高强度密码
- 7GIT - 版本控制与GIT野史_版本控制 发展史 野史
- 8idm批量下载
- 9IDEA报错解决方案_idea错误提示解决方案
- 10好用的AI3D建模工具,让游戏动漫设计高效且轻松_ai 3d建模 api
毕业设计:python电影推荐系统 爬虫 可视化分析 Django框架(源码+文档)_电影推荐系统django
赞
踩
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
1、项目介绍
技术栈:
Python语言、Django框架、MySQL数据库、基于用户和基于物品协同过滤推荐算法、豆瓣电影、requests爬虫技术、Echarts可视化、HTML
2、项目界面
(1)电影数据展示
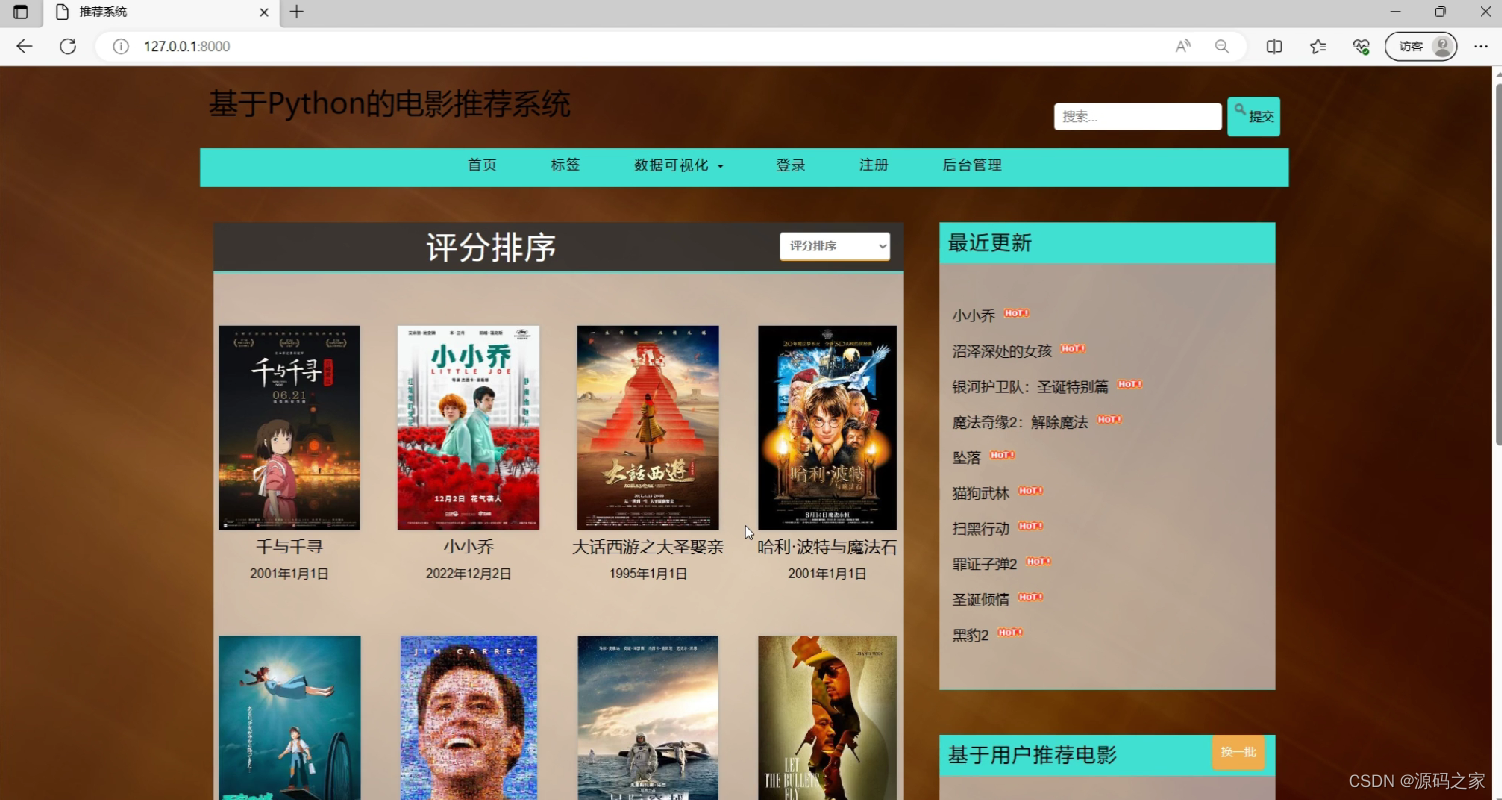
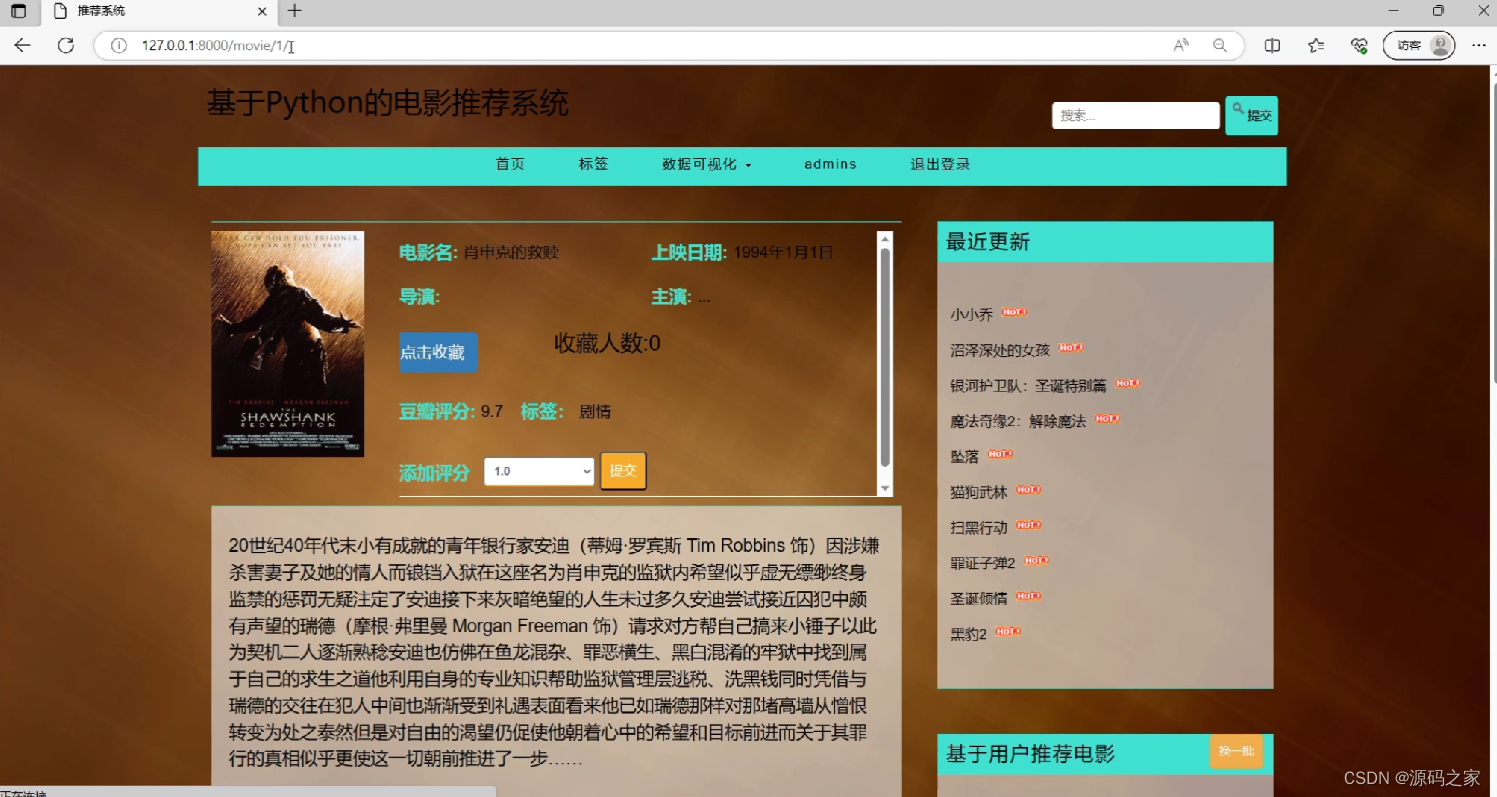
(2)电影数据详情页面
(3)电影数据可视化—饼状图分析

(4)电影数据可视化—词云图分析

(5)电影数据可视化—柱状图分析
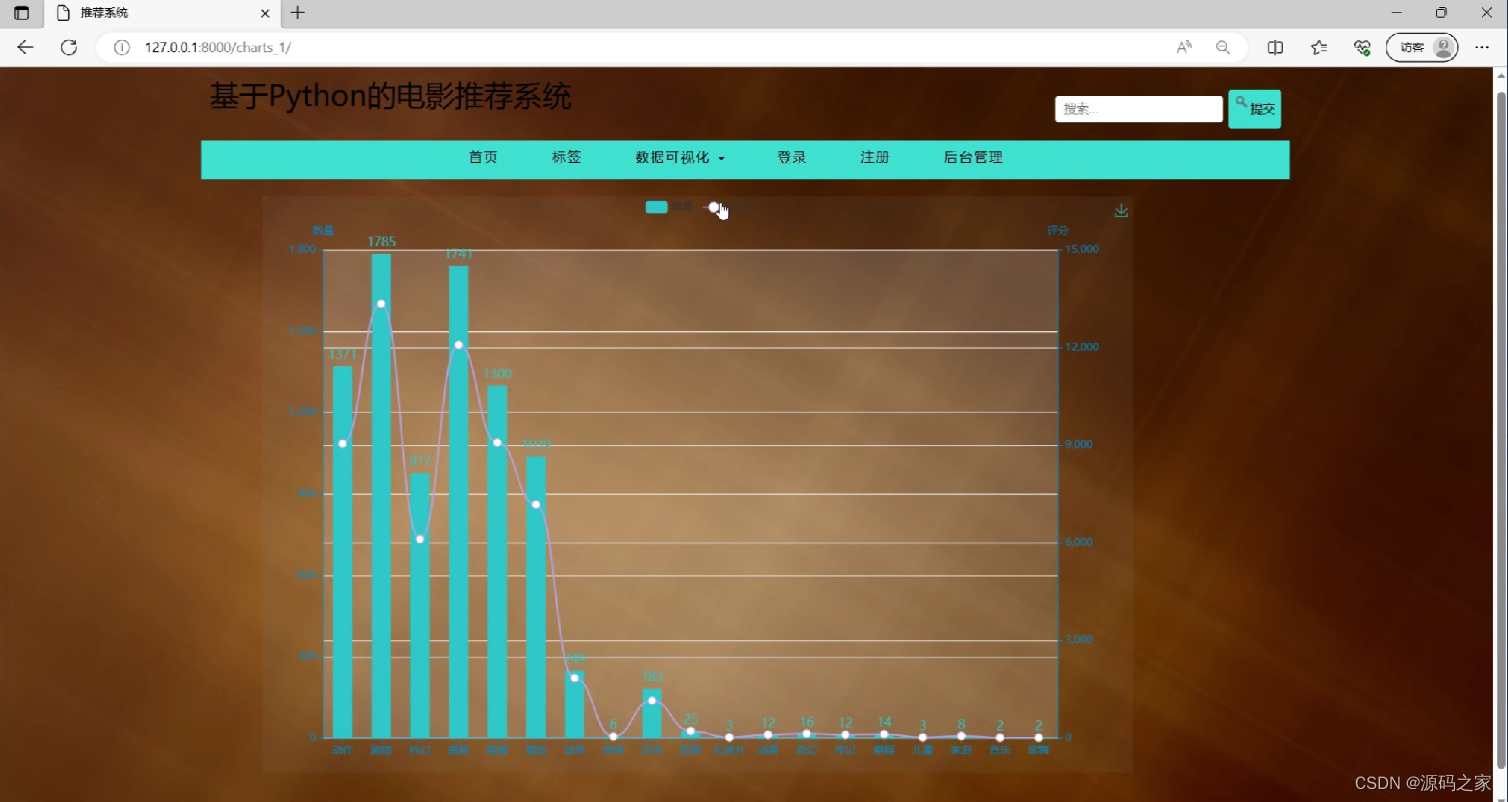
(6)电影数据可视化—曲线图分析
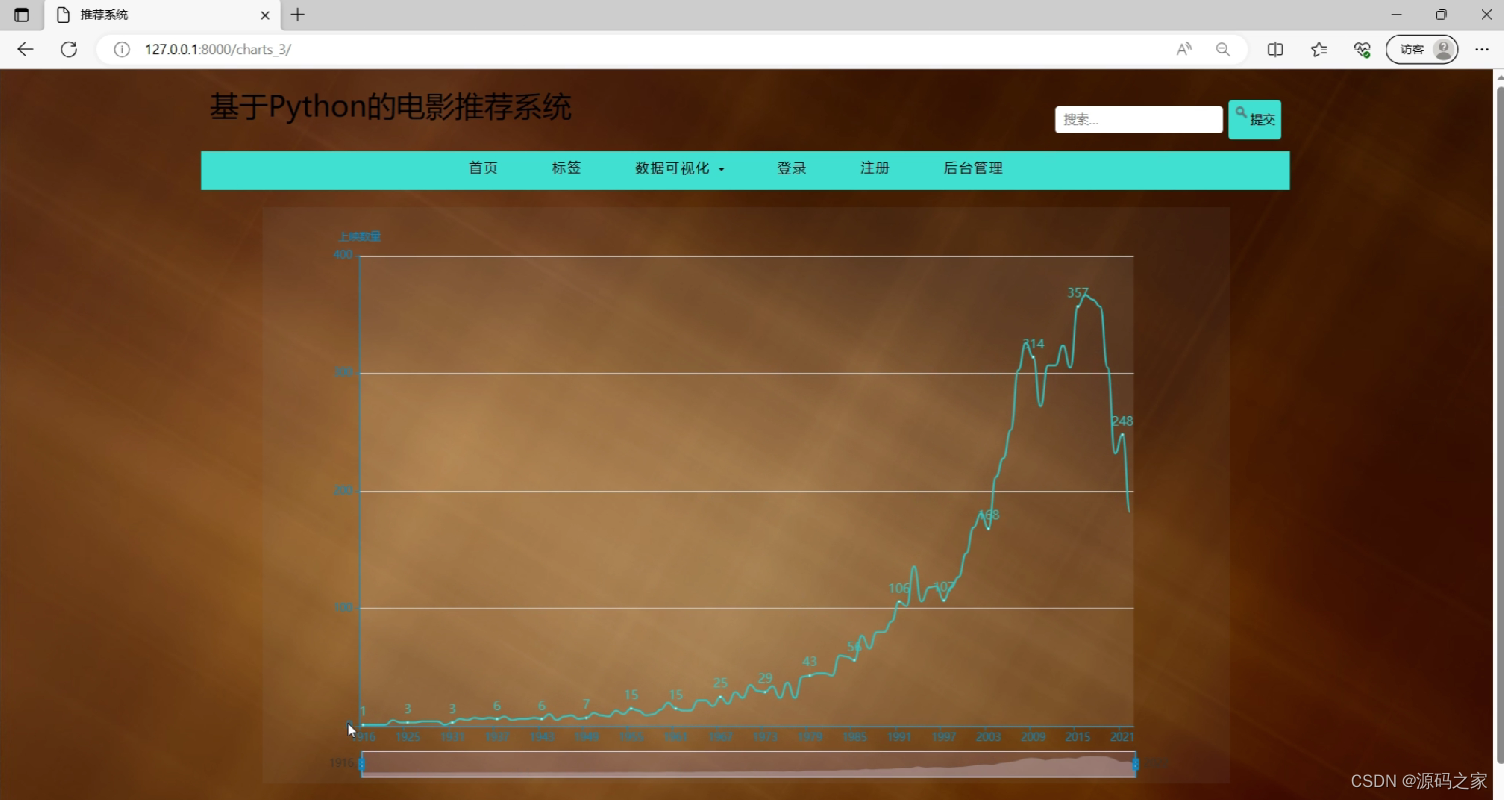
(7)电影推荐—基于用户和基于物品双推荐算法
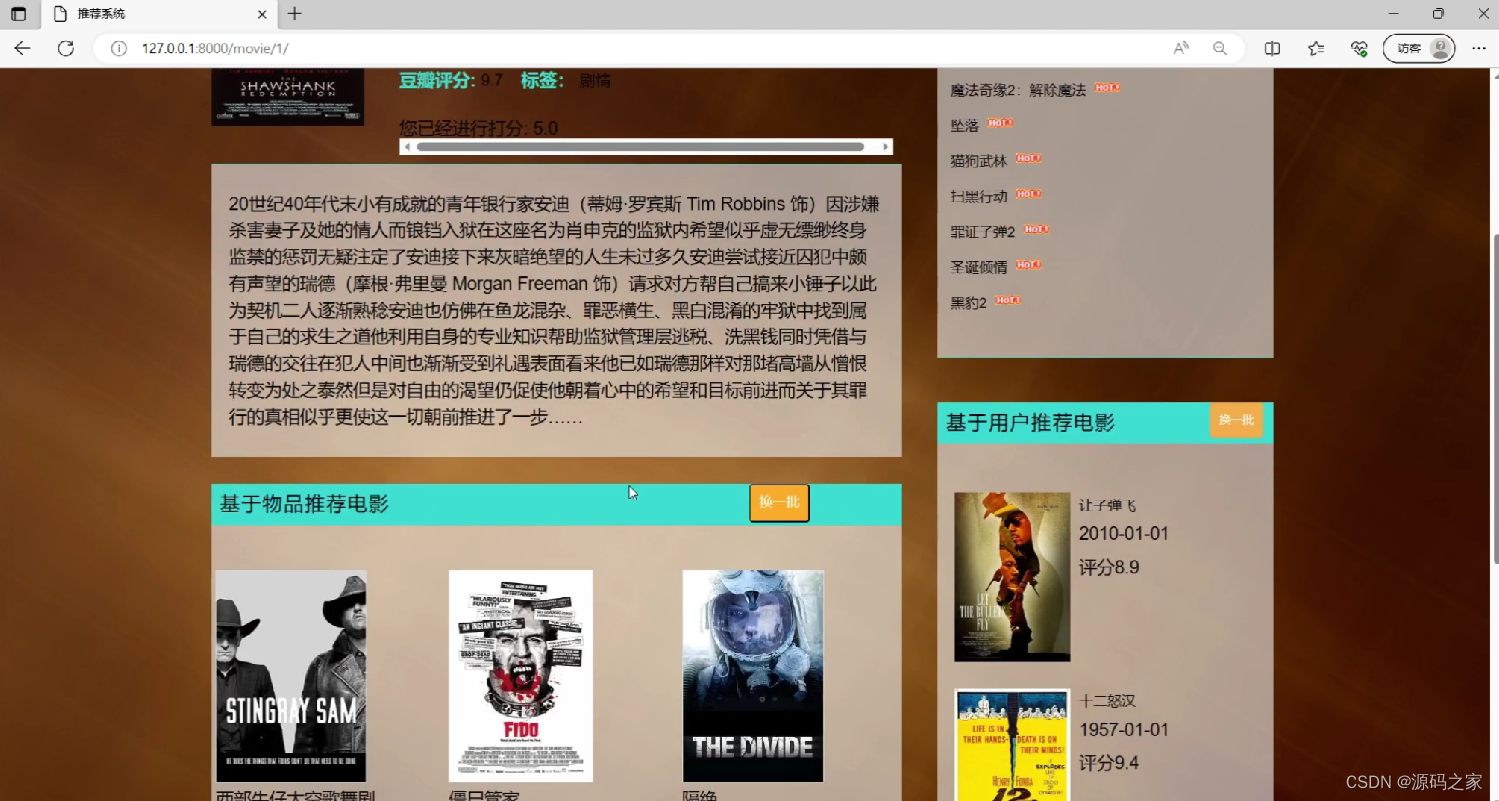
(8)电影分类

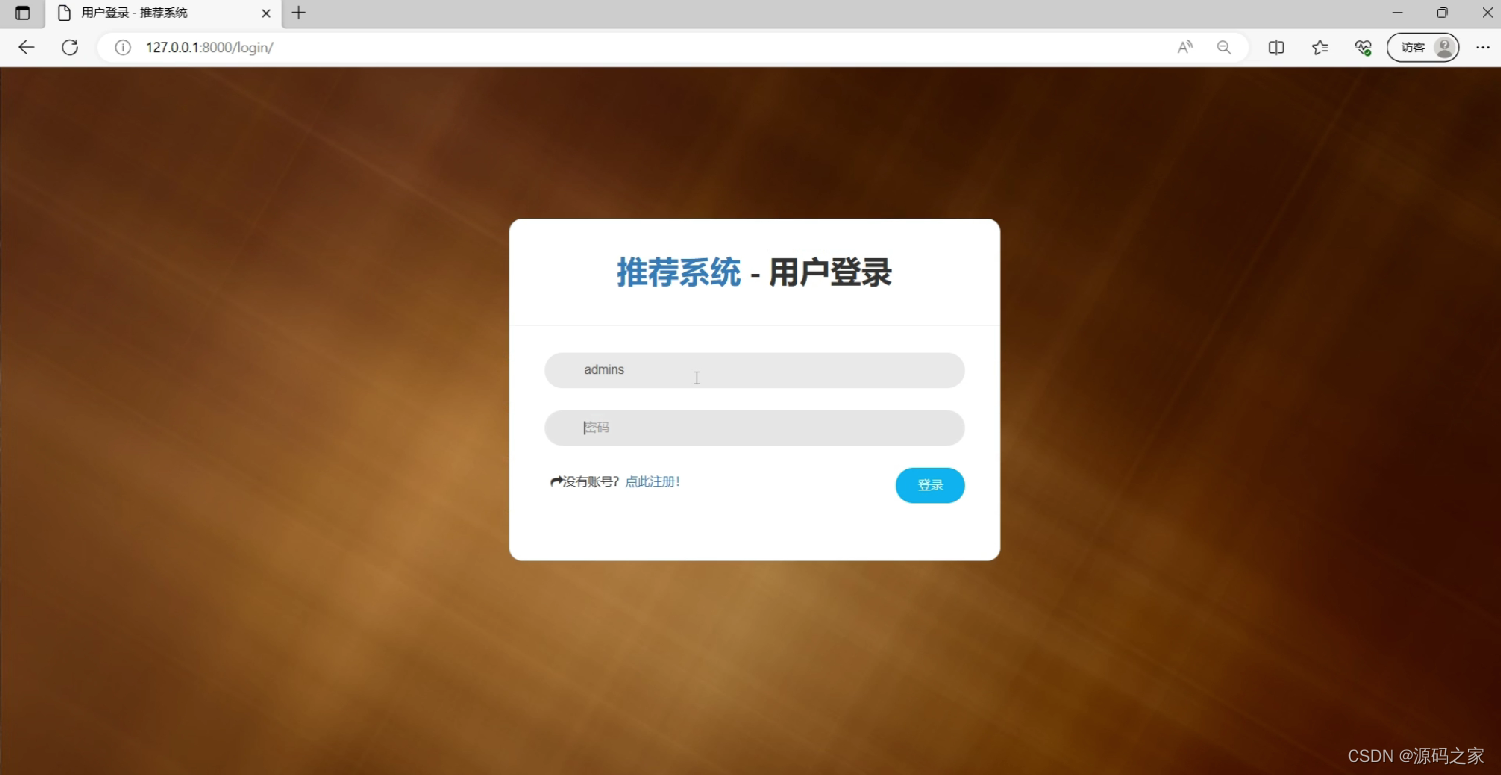
(9)注册登录界面
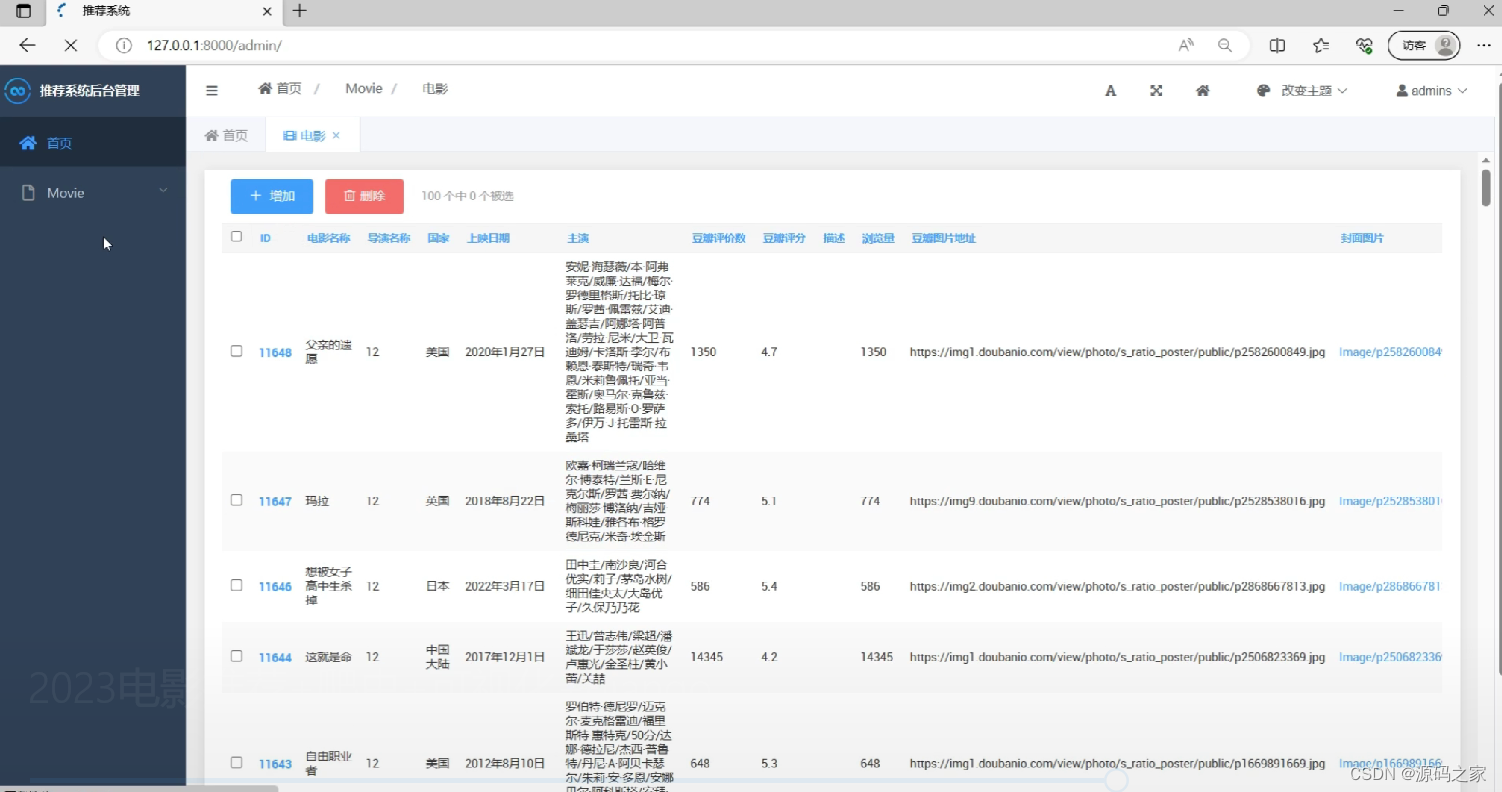
(10)后台数据管理
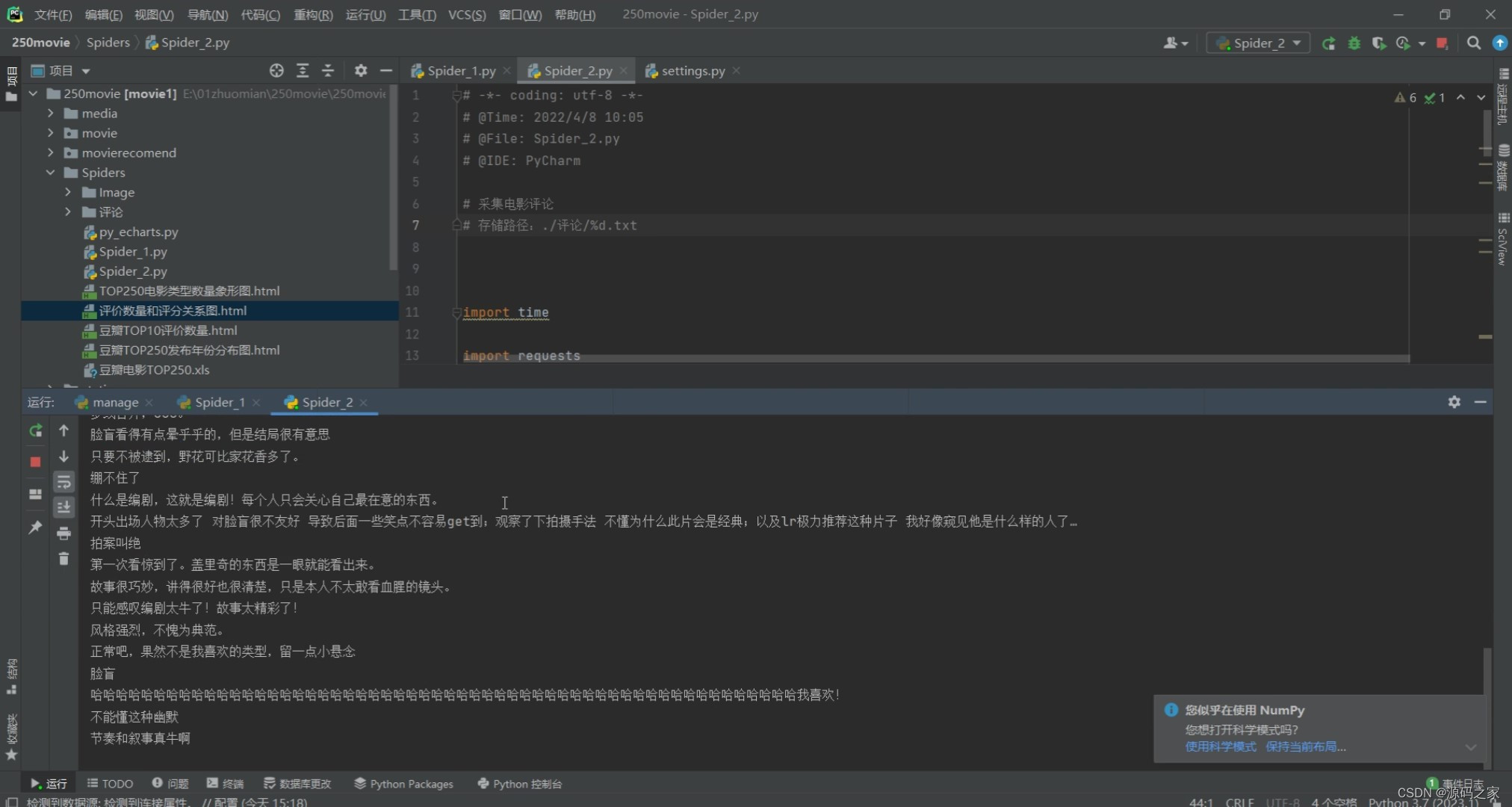
(12)电影数据采集页面
3、项目说明
本文将介绍一个基于Python语言、Django框架和MySQL数据库的豆瓣电影数据采集分析可视化推荐系统。
首先,我们使用requests爬虫技术从豆瓣电影网站上获取电影数据。通过分析网页的结构,我们可以提取出电影的名称、评分、导演、演员等信息,并将其存储在MySQL数据库中。
接下来,我们使用基于用户和基于物品的协同过滤推荐算法来实现电影推荐功能。基于用户的协同过滤算法根据用户的历史喜好,找到与其兴趣相似的其他用户,并推荐这些用户喜欢的电影。基于物品的协同过滤算法则根据电影的相似度,推荐与用户已经喜欢的电影相似的其他电影。通过这两种算法的结合,我们可以提供更准确的电影推荐结果。
为了更好地展示电影数据和推荐结果,我们使用Echarts可视化工具来呈现图表和图形。通过Echarts,我们可以生成各种可视化图表,如电影评分分布图、导演作品数量图、演员合作关系图等,以便用户更直观地了解电影信息。
最后,我们使用Django框架搭建一个Web应用程序,将数据采集、分析和推荐功能整合在一起。用户可以通过Web界面浏览电影信息、搜索电影、查看电影详情,并获得个性化的电影推荐。同时,用户还可以通过与系统的互动来改进推荐准确度,如给电影评分、添加喜欢的电影等。
总之,这个基于Python、Django和MySQL的豆瓣电影数据采集分析可视化推荐系统,通过爬虫技术获取电影数据,使用协同过滤算法实现个性化推荐,通过Echarts可视化工具展示数据,并通过Django框架搭建Web应用程序,为用户提供全面的电影浏览和推荐服务。
4、核心代码
import requests # 导包 from lxml import etree # 导包 import time import xlwt def main(): # 定义主函数 print('开始爬取数据...') data_list = get_data(headers) # 获取数据列表 save_data(data_list) print('爬取完毕!') def get_data(headers): data_list = [] start_url = 'https://movie.douban.com?start=' # 起始地址 for i in range(0, 10): print('开始爬取第%d页...' % (i + 1)) url = start_url + '%d&filter=' % (i * 25) # 拼接请求地址 response = requests.get(url, headers=headers).text req_html = etree.HTML(response) # 把网页转换为etree对象 div_data = req_html.xpath('//div[@class="item"]') for data in div_data: movie_list = [] movie_num = data.xpath('./div[1]/em/text()')[0] # 排名 movie_name = data.xpath('./div[2]/div[1]/a/span[1]/text()')[0] # 电影名 movie_datas = data.xpath('./div[2]/div[2]/p[1]/text()') # 年代/国家/剧情 movie_datas = "".join(movie_datas) # 拼接列表 movie_datas = movie_datas.split('\n') movie_datas = movie_datas[2].replace(' ', '').replace('\xa0', '').split('/') movie_date = movie_datas[0].replace('(中国大陆)', '') # 年代 movie_year = movie_datas[1] # 国家 movie_plot = movie_datas[2] # 剧情类型 movie_score = data.xpath('./div[2]/div[2]/div/span[2]/text()')[0] # 评分 movie_evaluate = data.xpath('./div[2]/div[2]/div/span[4]/text()')[0] # 评价数量 movie_url = data.xpath('./div[1]/a/@href')[0] # 电影链接 movie_list.append(movie_num) # 添加到列表信息 movie_list.append(movie_name) movie_list.append(movie_date) movie_list.append(movie_year) movie_list.append(movie_plot) movie_list.append(movie_score) movie_list.append(movie_evaluate.replace('人评价', '')) # print(movie_list) movie_list.append(movie_url) data_list.append(movie_list) # 将电影信息添加到数据列表以便数据持久化 time.sleep(3) # 等待3S接着爬 return data_list # 返回数据列表 def save_data(data_list): print('开始保存数据...') book = xlwt.Workbook(encoding="utf-8", style_compression=0) sheet = book.add_sheet('豆瓣电影', cell_overwrite_ok=True) col = ("电影排名", "电影名", "电影年代", "发行国家", "剧情类型", "评分", "评论数量", "电影链接") # 表头名 for i in range(0, 8): sheet.write(0, i, col[i]) # 列表名称 for k in range(0, len(data_list)): # 行 data = data_list[k] for j in range(0, 8): sheet.write(k + 1, j, data[j]) # 写入数据第二行,第0-7列 book.save('./豆瓣电影.xls') if __name__ == '__main__': main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

