
- 1在不同版本Python中安装PyQT5及PyQT5-Tools_pyqt5下载
- 2【MySQl】MySQl中的乐观锁是怎么实现的_mysql 乐观锁
- 3【Python】Transformers加载BERT模型from_pretrained()问题解决_typeerror: 'berttokenizer' object is not callable
- 4adb禁止鸿蒙系统更新_adb 手机 停止更新 csdn
- 5HTML:列表元素_果仁雷爷
- 6机器人是怎么计时的(通用定时器 - 时基单元)
- 7#如何创新玩转HarmonyOS开发##SANDAU#探索鸿蒙生态:学习HarmonyOS知识的发现与心得_鸿蒙应用开发的总结与体会
- 8华为鸿蒙和安卓有啥区别?我们和鸿蒙开发者聊了聊_安卓开发与华为开发的区别
- 9idea中新建分支并且切换到新建的分支上_checked out new branch dev from origin/dev
- 10PYLTP 0.2.1 centos 6.5安装 过程_pyltp-0.2.1
意图识别项目笔记_意图识别与实体识别区别
赞
踩
意图识别分为两个模块:意图分类的识别和当前意图中slot(槽位)的识别。其中槽位的识别可以参考实体的识别,但又与之不同。槽位识别可以看做是对每个意图所需条件的识别,比实体的识别更加多元化。比如有一句话:显示从北京到上海的航班。
意图:航班查询。
槽位标记:北京(from-city),上海(to-city)
实体标记:北京(city),上海(city)。
1.项目流程
样本格式:采用BIO标记策略,句子+EOS+句子中每个字对应的槽位标签+意图。
1.数据预处理阶段:。将句子,槽位标签,意图id化并保存至文件中
2.模型输入:句子的列表,每个句子长度的列表,槽位列表,意图列表。
3.模型架构:通过模型预测槽位列表、意图列表。
4.损失计算:通过NLLLoss()函数(只接收log_softmax后的数据)计算槽位、意图和实际的损失。
5.模型优化:使用Adam函数优化损失。
2.模型架构
下面来详细介绍上述流程中的模型架构。
模型结构图:
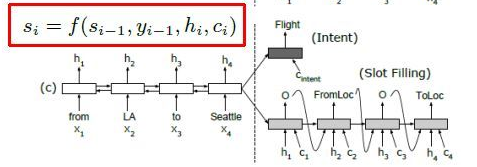
该模型是基于seq2seq+attention对齐机制的架构,分为Encoder和Decoder两个阶段。
Encoder: 加载预训练的语言模型,对输入的数据进行字嵌入得到字向量,通过torch中的pack_padded_sequence将字向量按照句子长度降序、padding、打包作为LSTM的输入,通过双向LSTM进行特征提取。返回每个时刻隐藏层的输出结果hiddens和最后一个时刻隐藏层输出的(h,c)的二元组state。
Decoder: 该阶段通过Encoder阶段的输出来预测意图和槽位。
1.将Si-1为decode阶段上一个时刻的输出,将Si-1赋值n份(n为Encoder阶段中的时刻数,也就是句子长度)与hiddens进行加权求和获取Encoder中的权重参数,再与hiddens相乘获取文本向量Ci,并将其添加到一个文本向量列表Cn。
2.Si为decoder阶段当前时刻的输出状态:Si=Si-1 + yi-1 + Ci。将Si和当前时刻对应Encoder中的时刻的输出ht做拼接,使用单向LSTM提取特征,通过log_softmax提取概率最大的作为yi,并添加值预测槽位列表中。
3.将文本向量列表Cn与Encoderhiddens拼接,做取均值降维,再使用log_softmax作为输出结果并添加到预测意图列表中。

