
- 1CrossOver for Mac 24.0.0 (mac类虚拟机运行Windows软件)
- 2【HarmonyOS开发】ArkTs关系型和非关系型数据库的存储封装_relationalstore failed to insert data. code:undefi
- 3最新最全的前端面试题集锦之 微信小程序 篇(从基础到高级)_小程序高级面试
- 4Android的.dex、.odex与.oat文件扫盲_base.odex
- 5矩阵运算时⊗和·的区别?_这个符号
- 6【Git】Git使用Gui图形化界面,Git中SSH协议,Idea集成Git_git gui 教程
- 7DumperOptions:配置文件yml读写
- 8C语言刷题(19)
- 9elementUI树形组件el-tree添加层级虚线,指示线_element树形结构加线
- 10性能优化 - likely和unlikely函数
支持中文的Rasa NLU训练服务部署---Rasa_NLU_Chi_rasa训练中文模型
赞
踩
代码在 https://github.com/crownpku/rasa_nlu_chi
但是它的内容已经严重过时,根本跑不起来,结合自己部署过程中踏过的一些坑,形成此文。
部署环境:Ubuntu 16.04+python 3.6
Rasa NLU本身是只支持英文和德文的。中文因为其特殊性需要加入特定的tokenizer作为整个流水线的一部分。我加入了jieba作为我们中文的tokenizer,这个适用于中文的rasa NLU的版本代码在github上。
语料获取及预处理
如果直接使用中文wikipedia和百度百科语料生成的total_word_feature_extractor_chi.dat(链接如下),可直接跳至构建rasa_nlu语料和模型部分
链接:https://pan.baidu.com/s/1kNENvlHLYWZIddmtWJ7Pdg 密码:p4vx
Rasa NLU的实体识别和意图识别的任务,需要一个训练好的MITIE的模型。这个MITIE模型是非监督训练得到的,类似于word2vec中的word embedding。
要训练这个MITIE模型,我们需要一个规模比较大的中文语料。最好的方法是用对应自己需求的语料,比如做金融的chatbot就多去爬取些财经新闻,做医疗的chatbot就多获取些医疗相关文章。
我使用的是awesome-chinese-nlp中列出的中文wikipedia dump和百度百科语料。其中关于wikipedia dump的处理可以参考这篇帖子。
仅仅获取语料还不够,因为MITIE模型训练的输入是以词为单位的。所以要先进行分词,我们使用结巴分词。
安装结巴分词:
$ pip install jieba
将一个语料文件分词,以空格为分隔符:
$ python -m jieba -d " " ./test > ./test_cut
MITIE模型训练
我们把所有分好词的语料文件放在同一个文件路径下。接下来我们要训练MITIE模型。
首先将MITIE clone下来:
$ git clone https://github.com/mit-nlp/MITIE.git
我们要使用的只是MITIE其中wordrep这一个工具。我们先build它。
- $ cd MITIE/tools/wordrep
- $ mkdir build
- $ cd build
- $ cmake ..
- $ cmake --build . --config Release
然后训练模型,得到total_word_feature_extractor.dat。注意这一步训练会耗费几十GB的内存,大概需要两到三天的时间。。。
$ ./wordrep -e /path/to/your/folder_of_cutted_text_files
构建rasa_nlu语料和模型
- 将rasa_nlu_chi clone下来并安装:
- $ git clone https://github.com/crownpku/rasa_nlu_chi.git
- $ cd rasa_nlu_chi
- $ python setup.py install
- 构建尽可能多的示例数据来做意图识别和实体识别的训练数据:
data/examples/rasa/demo-rasa_zh.json
格式是json,例子如下。’start’和’end’是实体对应在’text’中的起止index。
- {
- "text": "找个吃拉面的店",
- "intent": "restaurant_search",
- "entities": [
- {
- "start": 3,
- "end": 5,
- "value": "拉面",
- "entity": "food"
- }
- ]
- },
- {
- "text": "这附近哪里有吃麻辣烫的地方",
- "intent": "restaurant_search",
- "entities": [
- {
- "start": 7,
- "end": 10,
- "value": "麻辣烫",
- "entity": "food"
- }
- ]
- },
- {
- "text": "附近有什么好吃的地方吗",
- "intent": "restaurant_search",
- "entities": []
- },
- {
- "text": "肚子饿了,推荐一家吃放的地儿呗",
- "intent": "restaurant_search",
- "entities": []
- }

对于中文我们现在有两种pipeline:
使用 MITIE+Jieba:
[“nlp_mitie”, “tokenizer_jieba”, “ner_mitie”, “ner_synonyms”, “intent_classifier_mitie”]
这种方式训练比较慢,效果也不是很好,最后出现的intent也没有分数排序。
我们推荐使用下面的pipeline:
MITIE+Jieba+sklearn (sample_configs/config_jieba_mitie_sklearn.json):
[“nlp_mitie”, “tokenizer_jieba”, “ner_mitie”, “ner_synonyms”, “intent_featurizer_mitie”, “intent_classifier_sklearn”]
这里也可以看到Rasa NLU的工作流程。”nlp_mitie”初始化MITIE,”tokenizer_jieba”用jieba来做分词,”ner_mitie”和”ner_synonyms”做实体识别,”intent_featurizer_mitie”为意图识别做特征提取,”intent_classifier_sklearn”使用sklearn做意图识别的分类。
- 训练Rasa NLU的模型
$ python -m rasa_nlu.train -c sample_configs/config_jieba_mitie_sklearn.yml --data data/examples/rasa/demo-rasa_zh.json --path models这样就会生成一个类似model_20xxxxxx-xxxxxxx的文件在 /models/default 的文件夹里。
如果报错提示需要安装mitie或sklearn,可用pip install安装。
搭建本地rasa_nlu服务
- 启动rasa_nlu的后台服务:
python -m rasa_nlu.server -c sample_configs/config_jieba_mitie_sklearn.yml --path models
- 打开一个新的terminal,我们现在就可以使用curl命令获取结果了, 举个例子:
- curl -XPOST localhost:5000/parse -d '{"q":"我发烧了该吃什么药","model": "model_20200821-002830"}' | python -mjson.tool
- % Total % Received % Xferd Average Speed Time Time Time Current
- Dload Upload Total Spent Left Speed
- 100 781 0 713 100 68 234 22 0:00:03 0:00:03 --:--:-- 234
- {
- "intent": {
- "name": "medical",
- "confidence": 0.41050353032074
- },
- "entities": [
- {
- "entity": "disease",
- "value": "\u53d1\u70e7",
- "start": 1,
- "end": 3,
- "confidence": null,
- "extractor": "ner_mitie"
- }
- ],
- "intent_ranking": [
- {
- "name": "medical",
- "confidence": 0.41050353032074
- },
- {
- "name": "restaurant_search",
- "confidence": 0.268388781853104
- },
- {
- "name": "affirm",
- "confidence": 0.1452713537374723
- },
- {
- "name": "goodbye",
- "confidence": 0.11560279492180317
- },
- {
- "name": "greet",
- "confidence": 0.06023353916688072
- }
- ],
- "text": "\u6211\u53d1\u70e7\u4e86\u8be5\u5403\u4ec0\u4e48\u836f"
- }
当然,你需要把model_20xxxxxx替换成你的model名字。
如果报错 "y should be a 1d array, got an array of shape() instead."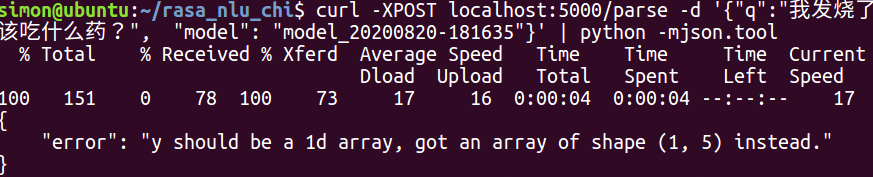
原因是因为sklearn的代码validation.py里面对y的格式有要求,需要把y的格式从二维矩阵转换成一维矩阵

也可以用postman



