
热门标签
热门文章
- 1getSystemService();的使用
- 2用 Eclipse 平台进行 C/C++ 开发_eclipse加载外部c++工程为什么使用外部编译器打开
- 32024年前端的前景如何?_2024qianduanmianshiti
- 400后又用回QQ了?“微信太老气,适合中年人”,扎心了_微信 qq 90后 评论
- 5ROS: 创建机器人仿真模型_ros水下机器人仿真
- 6OpenSSL的证书, 私钥和签名请求(CSRs)
- 7Tensorflow 2.x 模型-部署与实践_适用tensorflow2的模型
- 8mysql 类型转换 索引_经过字段类型转化后的查询不走索引
- 9spring boot Common Application properties-1_springapplication common
- 10cnn和transformer区别_transformer和cnn的区别
当前位置: article > 正文
大数据 排错日记0003——org.apache.hadoop.fs.ChecksumException: Checksum error_checksum error: /tmp/linkis/hadoop/
作者:Gausst松鼠会 | 2024-03-27 10:43:31
赞
踩
checksum error: /tmp/linkis/hadoop/

报错信息
2020-03-05 12:05:57,079 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id 2020-03-05 12:05:57,080 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId= 2020-03-05 12:05:58,366 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2020-03-05 12:05:58,368 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2020-03-05 12:05:58,373 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1 2020-03-05 12:05:58,393 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1 2020-03-05 12:05:58,440 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local2130092725_0001 2020-03-05 12:05:58,542 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/ 2020-03-05 12:05:58,543 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local2130092725_0001 2020-03-05 12:05:58,543 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null 2020-03-05 12:05:58,547 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2020-03-05 12:05:58,574 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks 2020-03-05 12:05:58,574 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local2130092725_0001_m_000000_0 2020-03-05 12:05:58,600 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux. 2020-03-05 12:05:58,651 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@49590e6e 2020-03-05 12:05:58,653 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Java/Workspaces/idea2019/BigData/Hdfs_dfs/data/date_4/part-r-00000:0+210 2020-03-05 12:05:58,681 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584) 2020-03-05 12:05:58,681 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100 2020-03-05 12:05:58,681 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080 2020-03-05 12:05:58,681 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600 2020-03-05 12:05:58,681 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600 2020-03-05 12:05:58,684 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2020-03-05 12:05:58,691 INFO [org.apache.hadoop.fs.FSInputChecker] - Found checksum error: b[0, 210]=6930322e632e616c69696d672e636f6d2c313336333135373938353036362c32373531320a6930322e632e616c69696d672e636f6d2c313336333135373938353036362c32373531320a6930322e632e616c69696d672e636f6d2c313338333135373939353033332c3233300a69666163652e716979692e636f6d2c313338333135373939333034342c353433330a7375672e736f2e3336302e636e2c313336333135373938353036362c353939320a7375672e736f2e3336302e636e2c313338333135373939353033332c32373332380a org.apache.hadoop.fs.ChecksumException: Checksum error: file:/D:/Java/Workspaces/idea2019/BigData/Hdfs_dfs/data/date_4/part-r-00000 at 0 exp: -1927656569 got: -8170764 at org.apache.hadoop.fs.FSInputChecker.verifySums(FSInputChecker.java:323) at org.apache.hadoop.fs.FSInputChecker.readChecksumChunk(FSInputChecker.java:279) at org.apache.hadoop.fs.FSInputChecker.read1(FSInputChecker.java:228) at org.apache.hadoop.fs.FSInputChecker.read(FSInputChecker.java:196) at java.io.DataInputStream.read(DataInputStream.java:100) at org.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:180) at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216) at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174) at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:143) at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:183) at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:553) at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80) at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 2020-03-05 12:05:58,693 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output 2020-03-05 12:05:58,705 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete. 2020-03-05 12:05:58,706 WARN [org.apache.hadoop.mapred.LocalJobRunner] - job_local2130092725_0001 java.lang.Exception: org.apache.hadoop.fs.ChecksumException: Checksum error: file:/D:/Java/Workspaces/idea2019/BigData/Hdfs_dfs/data/date_4/part-r-00000 at 0 exp: -1927656569 got: -8170764 at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) Caused by: org.apache.hadoop.fs.ChecksumException: Checksum error: file:/D:/Java/Workspaces/idea2019/BigData/Hdfs_dfs/data/date_4/part-r-00000 at 0 exp: -1927656569 got: -8170764 at org.apache.hadoop.fs.FSInputChecker.verifySums(FSInputChecker.java:323) at org.apache.hadoop.fs.FSInputChecker.readChecksumChunk(FSInputChecker.java:279) at org.apache.hadoop.fs.FSInputChecker.read1(FSInputChecker.java:228) at org.apache.hadoop.fs.FSInputChecker.read(FSInputChecker.java:196) at java.io.DataInputStream.read(DataInputStream.java:100) at org.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:180) at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216) at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174) at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:143) at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:183) at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:553) at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80) at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 2020-03-05 12:05:59,544 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local2130092725_0001 running in uber mode : false 2020-03-05 12:05:59,544 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0% 2020-03-05 12:05:59,546 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local2130092725_0001 failed with state FAILED due to: NA 2020-03-05 12:05:59,548 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 0 执行失败.....

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
问题描述:
本次的mapreduce程序处理的是经过第一次mapreduce程序处理后的结果part-r-00000。期间在结果数据中添加了两条数据,最后导致了问题的存在。
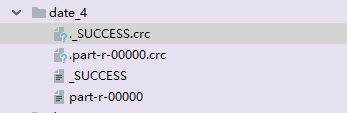
原因分析:
处理的结果中途被我加了一行数据,在读取的时候就会通过check机制进行数据完整性的检查,对比的是.crc文件中存储的信息。对比结果不正确就发生了这一幕。
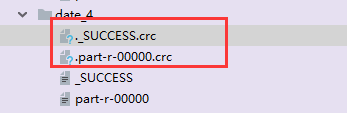
解决办法:
1.将两个.crc文件删除。
2.将文件数据恢复原样。
OVER

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/323816
推荐阅读
相关标签

