- 1【S32DS报错】-2-提示Error while launching command:arm-none-eabi-gdb –version错误_error while launching command: d:\nxp\s32ds.3.4\ec
- 22023华为od机试C卷【剩余银饰的重量】C++ 实现_剩余银饰的重量 华为
- 3在linux shell中使用for遍历产生的递增数字序列的N种方法_linux for里怎么递加2
- 4搭建CRNN模型(基于windows与tensorflow)_crnn模型训练
- 5大数据毕业设计:python校园舆情分析可视化系统 情感分析 舆情分析 朴素贝叶斯分类算法 爬虫(源码)✅_舆情分析 代码货栈
- 6【FPGA/verilog -入门学习11】verilogTestbench中的文本文件写入,读出,打印等操作_verilog测试文件操作步骤
- 7浏览器打印信息和自己写的console的位置不一样,一直显示 transform.js
- 8迅为RK3568开发板Linux_NVR_SDK 编译源码_rk3568 nvr sdk
- 9跨时钟域中单比特处理的基本知识点_synchronizer hold time
- 10iphone simulator 如何添加图片到相册_ios 模拟器 相册图片位置
使用Pandas对某医院中风患者数据进行预处理_使用pandas对某医院中风犯者进行预处理
赞
踩
【实验内容】
- 合并年龄、平均血糖和中风患者信息数据
- 删除年龄异常的数据
- 离散化年龄特征
【实验目的】
(1)掌握判断主键的方法。
(2)掌握主键合并的方法。
(3)掌握异常值数据处理的方法。
(4)掌握函数的创建与使用方法。
(5)掌握离散化连续型数据的方法。
【实验技术/工具清单】
集成开发工具:Anaconda3、PyCharm、Jupyter
第三方模块:Numpy、Pandas
【实验原理/思路】
实训1:合并年龄、平均血糖和中风患者信息数据
某医院为研究中风患者的特征,想要对中风患者的基础信息和体检数据(healthcare-dataset-stroke.xlsx)进行分析,其部分数据如表1所示。经观察发现患者基础信息和体检数据中缺少中风患者的年龄和平均血糖的信息,然而在年龄和平均血糖数据(healthcare-dataset-age_abs.xlsx)中存放了分析所需的中风患者的年龄和平均血糖信息,其部分数据如表2所示。现需要对患者的年龄、平均血糖数据与患者基础信息和体检数据进行合并,以便下一步分析。
表1 部分中风患者的基础信息和体检数据
| 编号 | 性别 | 高血压 | 是否结婚 | 工作类型 | 居住 类型 | 体重 指数 | 吸烟史 | 中风 |
| 9046 | 男 | 否 | 是 | 私人 | 城市 | 36.6 | 以前吸烟 | 是 |
| 51676 | 女 | 否 | 是 | 私营企业 | 农村 | N/A | 从不吸烟 | 是 |
| 31112 | 男 | 否 | 是 | 私人 | 农村 | 32.5 | 从不吸烟 | 是 |
| 60182 | 女 | 否 | 是 | 私人 | 城市 | 34.4 | 抽烟 | 是 |
| 1665 | 女 | 是 | 是 | 私营企业 | 农村 | 24 | 从不吸烟 | 是 |
| 56669 | 男 | 否 | 是 | 私人 | 城市 | 29 | 以前吸烟 | 是 |
表2 部分中风患者的年龄和平均血糖数据
| 编号 | 年龄 | 平均血糖(mg/dl) |
| 9046 | 67 | 228.69 |
| 51676 | 61 | 202.21 |
| 31112 | 80 | 105.92 |
| 60182 | 49 | 171.23 |
| 1665 | 79 | 174.12 |
实训2:删除年龄异常的数据
基于实训1合并后的数据,经观察发现在年龄特征中存在异常值(年龄数值为负数),为了避免异常值数据对分析结果造成不良影响,需要对异常值进行处理。
实训3:使用分组聚合方法分析房屋销售情况
利用分类算法预测患者是否中风时,算法模型要求数据是离散的。在实训2中已对年龄特征异常值进行了处理,现需要将连续型数据转换为离散型数据,使用等宽法对年龄特征进行离散化。
【实验步骤】
1.读取并查看某地区房屋销售数据的基本信息
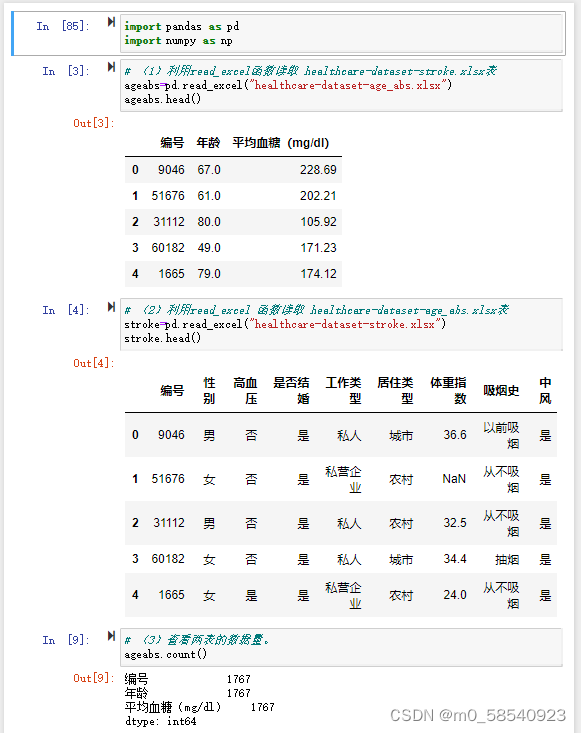
(1)利用read_excel函数读取 healthcare-dataset-stroke.xlsx表。
(2)利用read_excel 函数读取 healthcare-dataset-age_abs.xlsx表。
(3)查看两表的数据量。
(4)以编号作为主键进行外连接。
(5)查看数据是否合并成功。
2. 删除年龄异常的数据
(1)获取年龄特征。
(2)利用for 循环获取年龄特征中的数值,并用 if-else 语句判断年龄数值是否为异常值。
(3)若年龄数值为异常值,则删除异常值。
3. 离散化年龄特征
(1)获取年龄特征。
(2)使用等宽法离散化对年龄特征进行离散化。
【实验记录与结果分析】
实现源代码和执行结果。
- import pandas as pd
-
- import numpy as np
-
- ageabs=pd.read_excel("healthcare-dataset-age_abs.xlsx")
-
- ageabs.head()
-
- # (2)利用read_excel 函数读取 healthcare-dataset-age_abs.xlsx表
-
- stroke=pd.read_excel("healthcare-dataset-stroke.xlsx")
-
- stroke.head()
-
- # (3)查看两表的数据量。
-
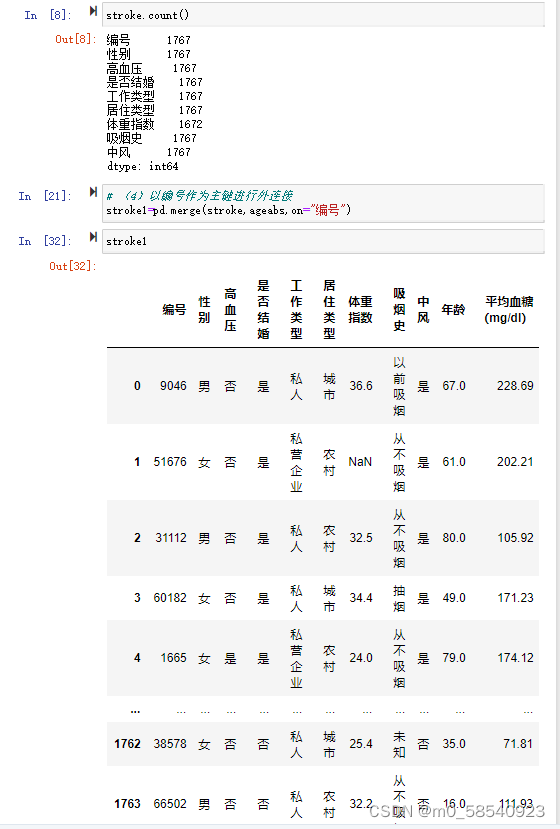
- ageabs.count()
-
- stroke.count()
-
- # (4)以编号作为主键进行外连接
-
- stroke1=pd.merge(stroke,ageabs,on="编号")
-
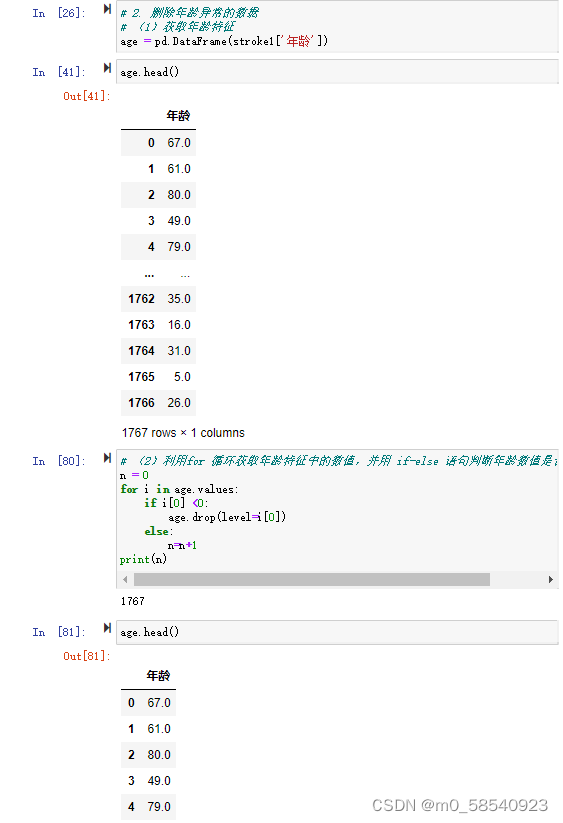
- # 2. 删除年龄异常的数据
-
- # (1)获取年龄特征
-
- age = pd.DataFrame(stroke1['年龄'])
-
- age.head()
-
- # (2)利用for 循环获取年龄特征中的数值,并用 if-else 语句判断年龄数值是否为异常值。
-
- n = 0
-
- for i in age.values:
-
- if i[0] <0:
-
- age.drop(level=i[0])
-
- else:
-
- n=n+1
-
- print(n)
-
- age.head()
-
- # 3. 离散化年龄特征
-
- # (1)获取年龄特征。
-
- # (2)使用等宽法离散化对年龄特征进行离散化。
-
- data = stroke1['年龄']
-
- list(data)
-
- # 可视化
-
- def cluster_plot(d, k):
-
- import matplotlib.pyplot as plt
-
- plt.rcParams['font.sans-serif'] = ['SimHei']
-
- plt.rcParams['axes.unicode_minus'] = False
-
-
-
- plt.figure(figsize=(12, 4))
-
- for j in range(0, k):
-
- plt.plot(data[d == j], [j for i in d[d == j]], 'o')
-
-
-
- plt.ylim(-0.5, k - 0.5)
-
- return plt
-
- # data = np.random.randint(1, 100, 200)
-
- k = 10 # 分为5个等宽区间
-
- # 等宽离散
-
- d1 = pd.cut(data, k, labels=range(k))
-
- cluster_plot(d1, k).show()
|
|