
热门标签
热门文章
- 1Python自动化 —— 大麦网自动抢购原价演唱会门票_大麦抢票代码_python 大麦抢票演唱会
- 2深度学习优化器深度解析:SGD、Adam、RMSprop的比较与应用
- 3问题:第一次世界大战的起止时间是 #其他#学习方法#微信
- 4移动IM开发指南1:如何进行技术选型_开发im 思想
- 5游戏开发小结——如何在 Unity 项目中添加和管理背景音乐_unity添加背景音乐
- 6Alex 的 Hadoop 菜鸟教程: 第21课 不只是在HBase中用SQL:Phoenix_cannot locate configuration: tried hadoop-metrics2
- 7数据结构需要每个都具体实现吗?
- 8【制作100个unity游戏之27】使用unity复刻经典游戏《植物大战僵尸》,制作属于自己的植物大战僵尸随机版和杂交版3(附带项目源码)_植物大战僵尸unity
- 9【大厂AI课学习笔记NO.71】AI算力芯片GPU/TPU等_npu和tpu
- 10javax.security.auth.login.LoginException: Receive timed out
当前位置: article > 正文
论文笔记--Llama3 report_llama3论文
作者:Cpp五条 | 2024-06-17 14:20:05
赞
踩
llama3论文
1. 文章简介
- 标题:Llama3 Report
- 作者:Meta
- 日期:2024.04
2. 性能升级
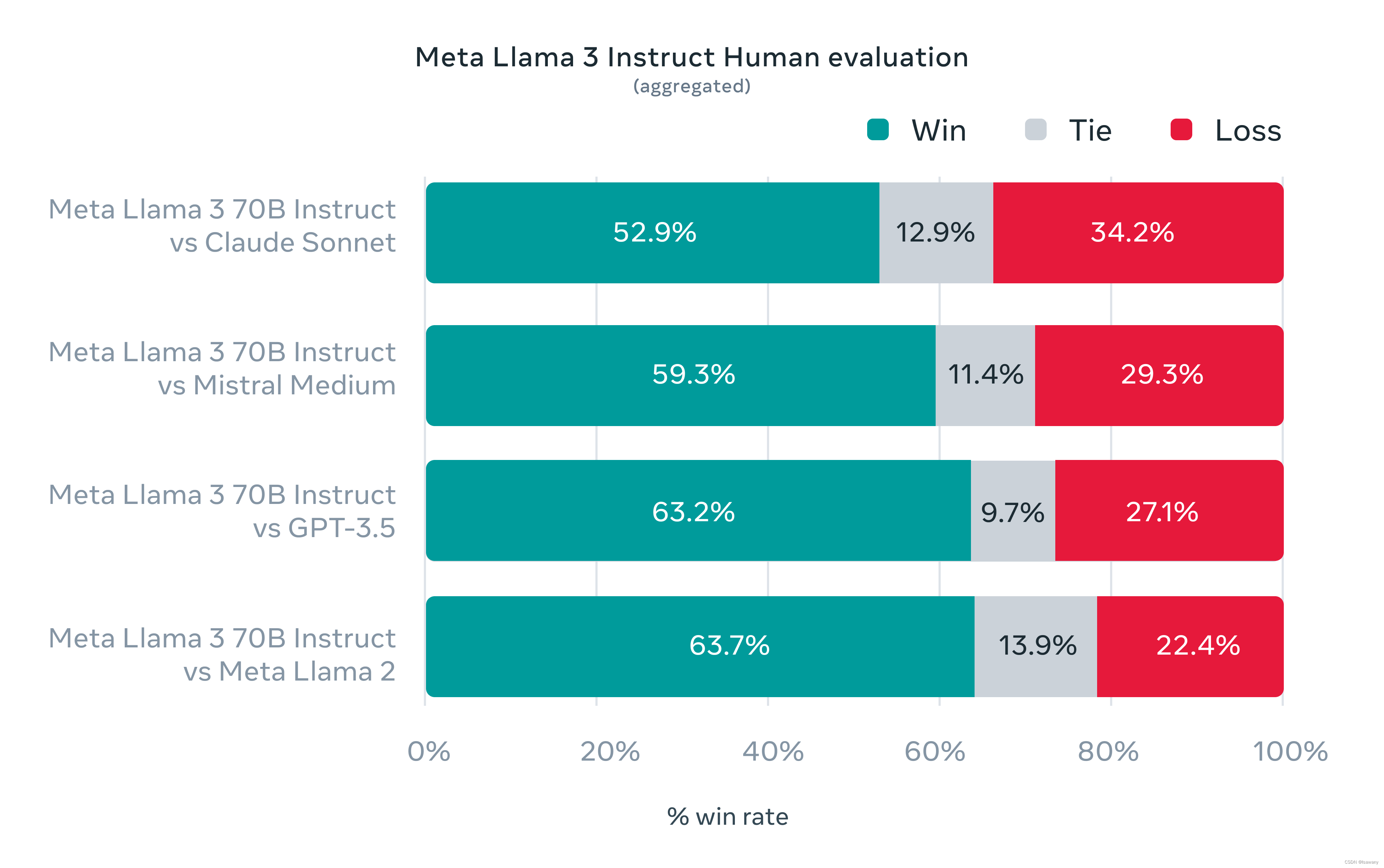
Llama3系列本次开源了8B和70B模型,在多个benchmarks上取得了SOTA表现。具体评估细节可以参见github

本次验证增加了高质量的人工评估集,涵盖12种场景(寻求建议、头脑风暴、分类、闭源QA、编码、创意写作、信息抽取、角色扮演、开放QA、推理、重写、摘要)共计1800个prompts。Llama3在这些prompts上表现超过GPT-3.5等模型:
3. 模型升级
3.1 模型架构升级
相比于Llama2[1],Llama3在模型架构上没有明显改变,仍采用transformer的decoder架构,模型架构升级如下
- 词表大小由32K升级为128K
- 采用GQA编码(Llama2也采用了GQA)
- 上下文长度从4K增加为8k(8192)个tokens,并使用mask保证self-attention不跨文章

3.2 数据升级
相比于Llama2,Llama3的数据也进行了升级,主要升级如下
- 总tokens数从2T增加到15T
- 包含更多的代码
- 包含超过5%的非英文语料
为了保障数据质量,Llama3构建了数据清洗pipelines,包含启发式规则,NSFW(不安全内容过滤)、语义去重。此外,Meta基于Llama2的高质量内容生成能力,通过Llama2生成数据来训练文本质量分类器。
3.3 指令微调
Llama3采用了SFT、PPO、DPO组合的方式进行后训练(Post-training),Meta精心筛选了prompts的质量,从而大幅提高了模型表现。Meta发现模型有时候知道如何产生正确答案但不知道如何选择它,而通过PPO和DPO可提高模型的选择能力,从而提高在推理和编码任务上的表现。
4. 原文传送门
Meta Llama3 report
Meta Llama3 Model
6. References
[1] 论文笔记–Llama 2: Open Foundation and Fine-Tuned Chat Models
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/731541
推荐阅读
相关标签

