
热门标签
热门文章
- 1零基础快速搭建Stable Diffusion(Mac版),小白也能学会!_stablediffusion mac安装硬件要求
- 22023年“中国高校计算机大赛-人工智能创意赛”初赛评审结果公示
- 3门控循环单元网络在图像处理中的颠覆性影响
- 4钉钉在MAKE 2024大会上宣布开放AI生态;NBC将用AI主播播报巴黎奥运会内容_钉钉生态大会2024回放
- 5【FISCO-BCOS】十四、使用Caliper进行压力测试fisco-bcos_caliper 压力测试
- 6玩comfyui踩过的坑之使用ComfyUI_Custom_NODES_ALEKPET翻译组件问题_comfyui翻译节点不能用
- 7yolov9 瑞芯微 rknn 部署 C++代码_yolov9 转rknn
- 8PermissionError: [Errno 13] Permission denied 解决方法_permissionerror: [errno 13] permission denied:
- 92024年河北省职业院校技能大赛(高职组) “云计算应用” 赛项样题_河北省python职业技能大赛2024
- 10探索设计模式的魅力:分布式模式让业务更高效、更安全、更稳定(1)_探索更高效便捷、更安全适用的技术成为必需
当前位置: article > 正文
用python实现KNN算法_python knn
作者:Cpp五条 | 2024-06-15 11:18:28
赞
踩
python knn
KNN简介
KNN(K-nearest neighbor),即K近邻算法。当需要表示一个样本(值)的时候,就使用于该样本最接近的K个邻居来决定。KNN即可以用于分类,也可以用于回归。
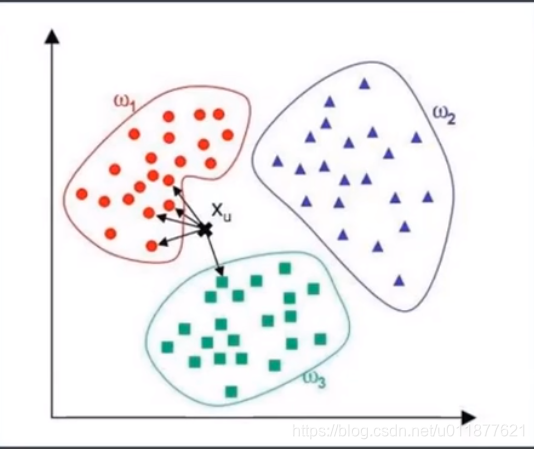
数据集地址
https://vincentarelbundock.github.io/Rdatasets/csv/datasets/iris.csv
KNN算法
KNN.py
# -*- coding:utf-8 -*- import numpy as np class KNN: def __init__(self,k): ''' :param k: 邻居的个数 ''' self.k=k def fit(self,X,y): ''' 训练方法 :param X: 类数组类型,形状为:(样本数量,特征数量),待训练的样本特征 :param y: 类数组类型,形状为:(样本数量),每个样本的目标值(标签) ''' self.X=np.asarray(X) self.y=np.asarray(y) def predict(self,X): ''' 根据参数传递的样本,对样本数据进行预测 :param X: 类数组类型,形状为:(样本数量,特征数量),待训练的样本特征 :return: result,数组类型,预测的结果 ''' X=np.asarray(X) result=[] # 对ndarray数组进行遍历,每次去数组中的一行 for x in X: # 对于测试集中的每一个样本,依次与训练集中的所有样本求距离 dis=np.sqrt(np.sum((x-self.X)**2,axis=1)) # 返回数组排序后,每个元素在原数组中的索引 index=dis.argsort() # 进行截断,只取前k个元素 【取距离最近的k个元素的索引】 index=index[:self.k] # 返回数组中每个元素出现的次数,元素必须是非负整数 count=np.bincount(self.y[index]) # 返回ndarray数组中,值最大的元素对应的索引。 result.append(count.argmax()) return np.asarray(result)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
训练与测试
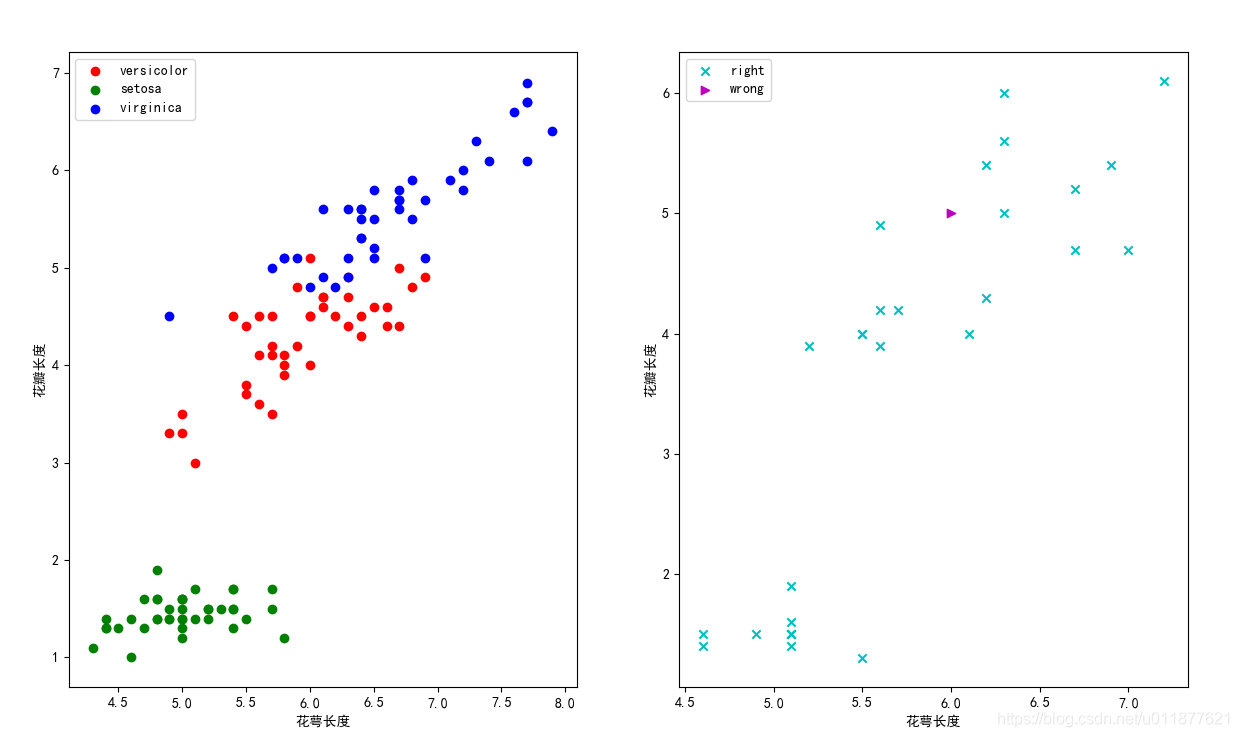
# -*- coding:utf-8 -*- import numpy as np import pandas as pd import KNN import matplotlib as mpl import matplotlib.pyplot as plt # header参数指定标题的行,默认为0.如果没有标题,则使用None data = pd.read_csv('iris.csv',header=0) # print(data.head()) # 将文本数据映射成数值类型 data['Species']=data['Species'].map({"versicolor":0,"setosa":1,"virginica":2}) data = data.drop("Id",axis=1) # 删除列 # print(data.duplicated().any()) data.drop_duplicates(inplace=True) print(data.shape) # 提取出每个类中鸢尾花数据 t0=data[data['Species']==0] t1=data[data['Species']==1] t2=data[data['Species']==2] # 打乱每个类别的数据 t0=t0.sample(len(t0),random_state=0) t1=t1.sample(len(t1),random_state=0) t2=t2.sample(len(t2),random_state=0) # 分配训练集和测试集 train_X=pd.concat([t0.iloc[:40,:-1],t1.iloc[:40,:-1],t2.iloc[:40,:-1]],axis=0) train_y=pd.concat([t0.iloc[:40,-1],t1.iloc[:40,-1],t2.iloc[:40,-1]],axis=0) test_X=pd.concat([t0.iloc[40:,:-1],t1.iloc[40:,:-1],t2.iloc[40:,:-1]],axis=0) test_y=pd.concat([t0.iloc[40:,-1],t1.iloc[40:,-1],t2.iloc[40:,-1]],axis=0) # 训练与测试 knn=KNN.KNN(k=3) knn.fit(train_X,train_y) result=knn.predict(test_X) print(result) print(np.sum(result==test_y)) print(np.sum(result==test_y)/len(result)) # 可视化 # 设置画布大小 plt.figure(figsize=(20,10)) # 设置字体为黑体,支持中文显示 mpl.rcParams['font.family']='SimHei' # 设置中文字体,可以正常显示负号 mpl.rcParams['axes.unicode_minus']=False # 绘制训练集数据 plt.subplot(121) plt.scatter(x=t0['Sepal.Length'][:40],y=t0['Petal.Length'][:40],color='r',label='versicolor') plt.scatter(x=t1['Sepal.Length'][:40],y=t1['Petal.Length'][:40],color='g',label='setosa') plt.scatter(x=t2['Sepal.Length'][:40],y=t2['Petal.Length'][:40],color='b',label='virginica') plt.xlabel('花萼长度') plt.ylabel('花瓣长度') plt.legend(loc='best') plt.subplot(122) right = test_X[result == test_y] wrong = test_X[result != test_y] plt.scatter(x=right['Sepal.Length'], y=right['Petal.Length'], color='c', label="right", marker="x") plt.scatter(x=wrong['Sepal.Length'], y=wrong['Petal.Length'], color='m', label="wrong", marker=">") plt.xlabel('花萼长度') plt.ylabel('花瓣长度') plt.legend(loc='best') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
可视化结果
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/722098
推荐阅读

相关标签

