
- 1mmediting工具包中cycleGAN的使用以及训练自己的数据_openmmlab 训练cyclegan
- 2图像处理Python库--图片裁剪、缩放、灰度图、圆角等
- 3Lenovo ThinkStation P710_thinkstation p510叹号灯
- 4HBase基础条件
- 5AttributeError: ‘str‘ object has no attribute ‘json‘ 问题解决_attributeerror: 'str' object has no attribute 'jso
- 6websocket 点解发送 连接已关闭..._an unrecoverable ioexception occurred so the conne
- 7signature=8b42938f09e2cf752303c59298e18eae,yarn.lock
- 8教你一点点掌握视觉三维重建-colmap 重要代码逐行解析(大纲-预热阶段)_colmap 代码 中文注释
- 9excel下载两种方式(axios和window.open)_window.open 下载excel
- 10sharding-jdbc行分片策略默认不支持按分片键的范围查询_inline strategy cannot support this type sharding:
爬虫学习心得_python爬虫心得体会
赞
踩
在python环境中对小说进行爬取,一般需要安装爬虫所需的第三方库,目前我所使用的为BS4和Requests。
BS4库安装
Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解,因此可以快速地学习并掌握它。
安装命令为:
pip install beautifulsoup4==4.11.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
由于 BS4 解析页面时需要依赖文档解析器,所以还需要安装 lxml 作为解析库:
pip install lxml
- 1
- 2
首先进行一个简单的,编码操作
from bs4 import BeautifulSoup
soup = BeautifulSoup("<html>data</html>", 'lxml')
print(soup)
- 1
- 2
- 3
- 4
试验BS4与lxml能否正常运行,data表示要解析的内容,而lxml则是解析文档内容所使用的解析器。
最后得到的结果是

随后安装Requests库
Requests是一个优雅而简单的Python HTTP库,是为人类构建的。
Requests可以完成,Keep-Alive,带Cookie的持久化session,SSL认证,文件上传下载等诸多功能.
安装
pip install requests==2.27.1
- 1
- 2
检查Requests库能否正常使用,以疫情数据为例,爬取代码为:
import requests
response = requests.get('http://ncov.dxy.cn/ncovh5/view/pneumonia')
print(response.content.decode())
- 1
- 2
- 3
- 4
- 5
得到结果
由于爬取的数据过多,这里不做赘述,由此requests库正常运行。
在爬取过程中首先进行UA伪装,将爬取引擎伪装成一个浏览器。
接下来是爬取小说的章节和内容具体实操
1.F12键打开需要爬取页面的控制台。
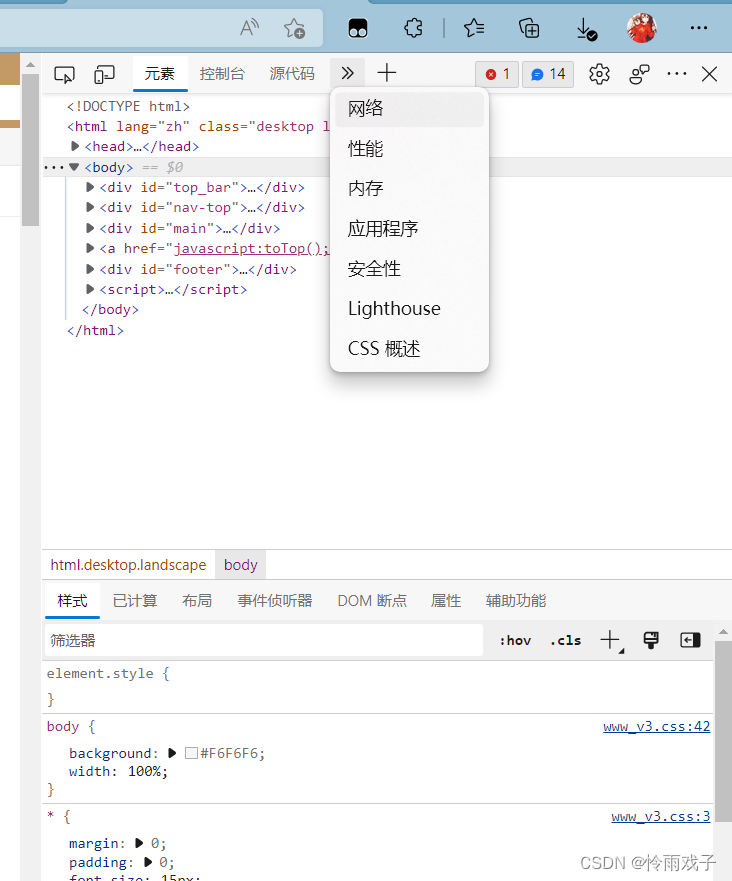
点击“网络”,如果左上角是红圈,刷新页面。
2.向下查找,最下面的user-agent值则是我们所需的。
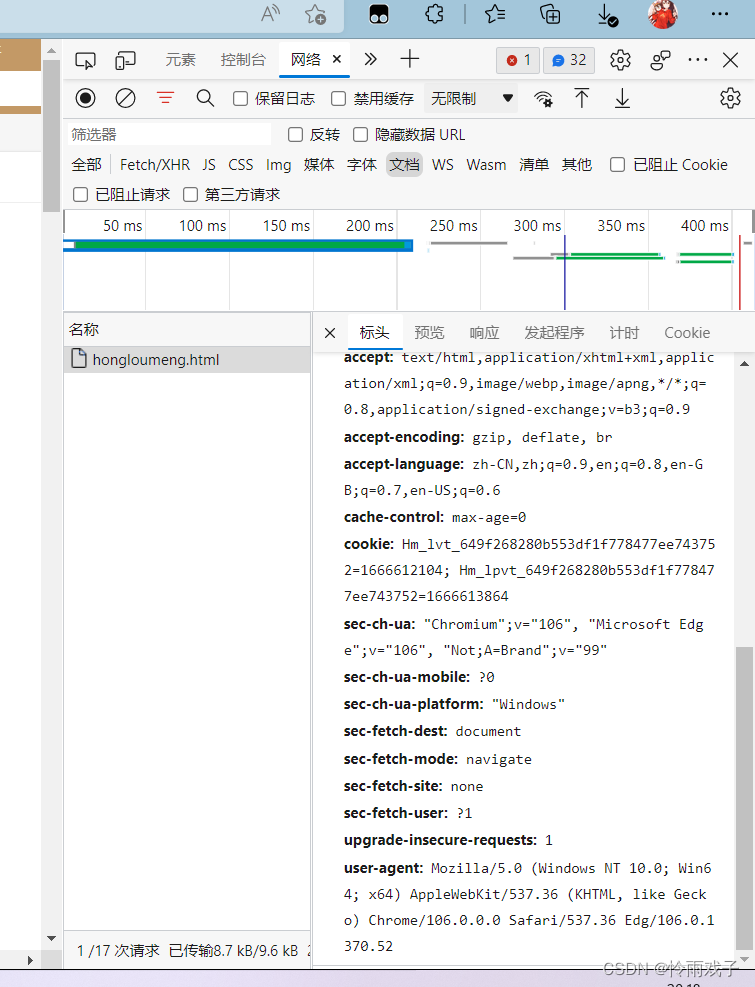
3.利用request的get方法对首页页面进行爬取,在首页中解析出章节的标题和详情页的url。
4.实例化BeautifulSoup对象,用解析器进行解析。
5.章节标题和详情页的url通控制台的元素进行查找。
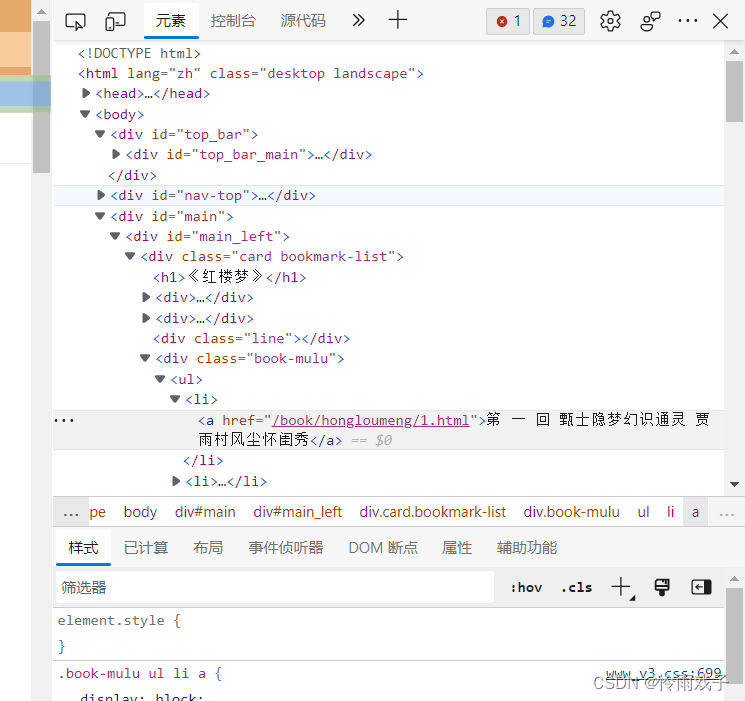
6.检查不同章节href标签的相似之处,通过循环遍历的方式,来自定义想要爬取的章节数量。
最后,具体代码如下:
import requests from bs4 import BeautifulSoup #需求:爬取红楼梦的所有章节和内容 if __name__ == '__main__': #UA伪装:将对应的User-Agent封装到一个字典中 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52'} #对首页的页面进行爬取 url = 'https://www.shicimingju.com/book/hongloumeng.html' # page_text = requests.get(url=url,headers=headers).text page_text = requests.get(url=url,headers=headers).content #在首页中解析出章节的标题和详情页的url #1、实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中 soup = BeautifulSoup(page_text,'html.parser') #解析章节标题和详情页的url li_list = soup.select('.book-mulu > ul > li') #将爬取的章节内容保存在sang。txt文档中 fp = open('./sang.txt','w',encoding='utf-8') num = 0 #查找需要的章节数量 for li in li_list: num += 1 if num >10: break title = li.a.string #详情页面的url detail_url = 'http://www.shicimingju.com'+li.a['href'] #对详情页发起请求,解析出章节内容 detail_page_text = requests.get(url=detail_url,headers=headers).content #解析出相关章节内容 detail_soup = BeautifulSoup(detail_page_text,'html.parser') div_tag = detail_soup.find('div',class_='chapter_content') #解析到了章节的内容 content = div_tag.text fp.write(title+':'+content+'\n') print(title,'successful!')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
运行成功的截图
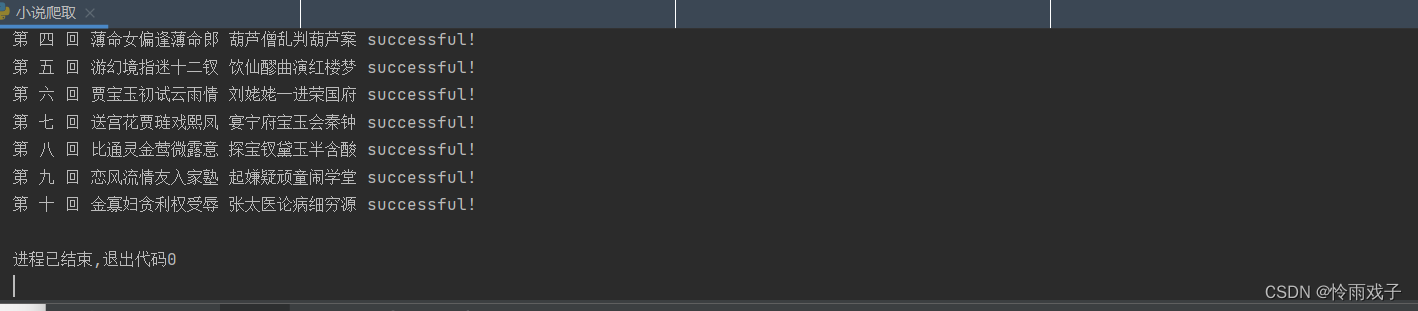
爬虫的学习让我对python的理解更上一层,下一目标,购物数据的爬取。


