
热门标签
热门文章
- 1人工智能大模型原理与应用实战:自然语言处理技术_基于大模型的自然语言处理技术
- 2Genius-X:智能编码助手,你的编程利器
- 3网络安全设备概念的熟悉和学习_脆弱性、基线、主机、web应用、安全
- 4数据湖:数据集成工具Kettle_etl metadata injection
- 5Revisiting Domain Generalized Stereo Matching Networks from a FeatureConsistency Perspective
- 6Elasticsearch(中文分词)安装、基本操作使用_elasticsearch 中文分词
- 7利用neo4j创建知识图谱_disease.csv
- 8【大数据处理】消费者行为与购物习惯数据分析及可视化_客户购物偏好数据集 kaggle
- 9Ubuntu20.04安装步骤详细指导_ubuntu20.04安装教程
- 10Appium入门安装搭建环境完整教程加实现过程经验总结_appium安装
当前位置: article > 正文
LDA主题模型Python实现_lda主题模型python代码
作者:Cpp五条 | 2024-04-04 13:15:02
赞
踩
lda主题模型python代码
如果你有一个文本文件,那么以下这段代码可以帮助你实现LDA主题模型。
- import jieba
-
- # from nltk.corpus import stopwords
- import pyLDAvis.gensim_models
- import wordcloud
- from gensim.models.coherencemodel import CoherenceModel
- from gensim.models.ldamodel import LdaModel
- from gensim.corpora.dictionary import Dictionary
-
- text_h = ""
- with open("temp.txt", "r", encoding="utf-8") as f:
- for ann in f.readlines():
- ann = ann.strip("\n") # 去除文本中的换行符
- print(ann)
- text_h += ann
- # text_h = word_tokenize(text_h)
- text_h = jieba.cut(text_h, cut_all=True)
- """
- for i in range(len(text_h)):
- text_h[i] = text_h[i].lower()
- text_h = list(filter(lambda x: not str(x).isdigit(), text_h))
- print(text_h)
- """
- interpunctuations = [
- ",",
- "。",
- ":",
- ";",
- "?",
- "(",
- ")",
- "【",
- "】",
- "&",
- "!",
- "、",
- "*",
- "@",
- "#",
- "$",
- "%",
- ".",
- ",",
- ":",
- ":",
- ";",
- "!",
- '"',
- "“",
- "”",
- "[",
- "]",
- "‘",
- "’",
- "。”",
- "",
- ] # 定义标点符号列表
- text_h = [word for word in text_h if word not in interpunctuations]
- # text_h = [word for word in text_h if word not in stopwords.words("english")]
-
- # text_h = jieba.cut(text_h, cut_all=True)
-
- s = " ".join(text_h) # 连接成字符串
-
-
- wc = wordcloud.WordCloud(
- font_path="msyh.ttc",
- width=1000,
- height=700,
- background_color="white",
- max_words=100,
- stopwords=s,
- )
-
- wc.generate(s) # 加载词云文本
- wc.to_file("XXXXX.png") # 保存词云文件
-
-
- # 构造词典
- dictionary = Dictionary([text_h])
- # 基于词典,使【词】→【稀疏向量】,并将向量放入列表,形成【稀疏向量集】
- corpus = [dictionary.doc2bow(words) for words in [text_h]]
- # lda模型,num_topics设置主题的个数
- lda = LdaModel(
- corpus=corpus, id2word=dictionary, num_topics=2, random_state=123, iterations=50
- )
- # U_Mass Coherence
- ldaCM = CoherenceModel(
- model=lda, corpus=corpus, dictionary=dictionary, coherence="u_mass"
- )
-
- # 打印所有主题,每个主题显示15个词
- for topic in lda.print_topics(num_words=15):
- print(topic)
-
- # 用pyLDAvis将LDA模式可视化
- # plot = pyLDAvis.gensim_models.prepare(lda, corpus, dictionary)
- # 保存到本地html
- # pyLDAvis.save_html(plot, "./XXXXX.html")
- """
- """

运行过后,你可以得到一个html文件,如下所示。
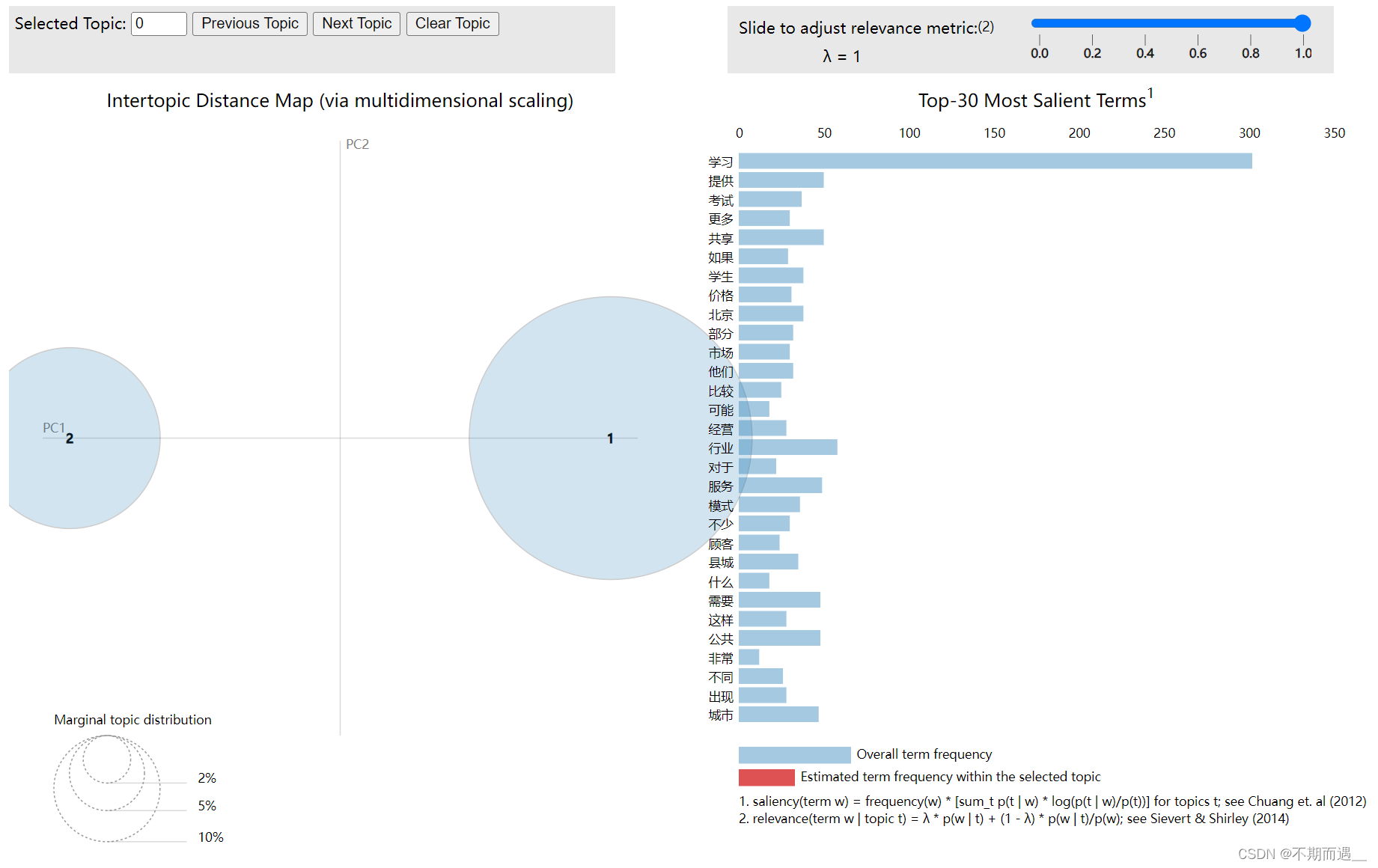
大家可以根据自己不同的需求进行自定义修改,模型主体是不变的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/358834
推荐阅读

相关标签

