
热门标签
热门文章
- 1人工智能基础知识:计算机视觉、自然语言处理、机器学习、强化学习等技术简介_计算机视觉、自然语言处理、其他
- 2MTCNN RetinaFace YoloFace_loss_kps
- 32022 年 前40道 ReactJS 面试问题和答案_jsx的面试题
- 4基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
- 5读锁和写锁(共享锁和排他锁)介绍 以及相关类 ReentrantReadWriteLock 学习总结,使用场景
- 6uniapp安卓手机无线真机调试教程_uniapp无线真机调试
- 7【AI大模型应用开发】【LangChain系列】7. LangServe:轻松将你的LangChain程序部署成服务
- 8大数据毕业设计hadoop+spark+hive+nlp知识图谱课程推荐系统 慕课在线教育课程数据分析可视化大屏 课程爬虫 文本分类 LSTM情感分析 计算机毕业设计 机器学习 深度学习 人工智能_spark、hadoop课程
- 9基于ISO13209(OTX)实现EOL下线序列_dts odx
- 10BP神经网络算法学习_bp神经网络神经元层数影响
当前位置: article > 正文
可视化pytorch网络特征图_pytorch打印特征图
作者:Cpp五条 | 2024-03-30 13:43:47
赞
踩
pytorch打印特征图
0. 背景
在目标检测任务中,我们会使用多尺度的特征图进行预测,背后的常识是:浅层特征图包含丰富的边缘信息有利于定位小目标,高层特征图中包含大量的语义信息有利于大目标的定位和识别。为了进一步了解特征图包含的信息,可以通过可视化特征图直观的认识到神经网络学习得到的东西。此外,对于分析网络为什么有效和改进网络也有些许帮助。
1. pytorch提供的函数
1.1. register_forward_hook

利用register_forward_hook在特定的module上添加一个hook函数,对该module的输入和输出特征图进行分析。
1.2 save_image
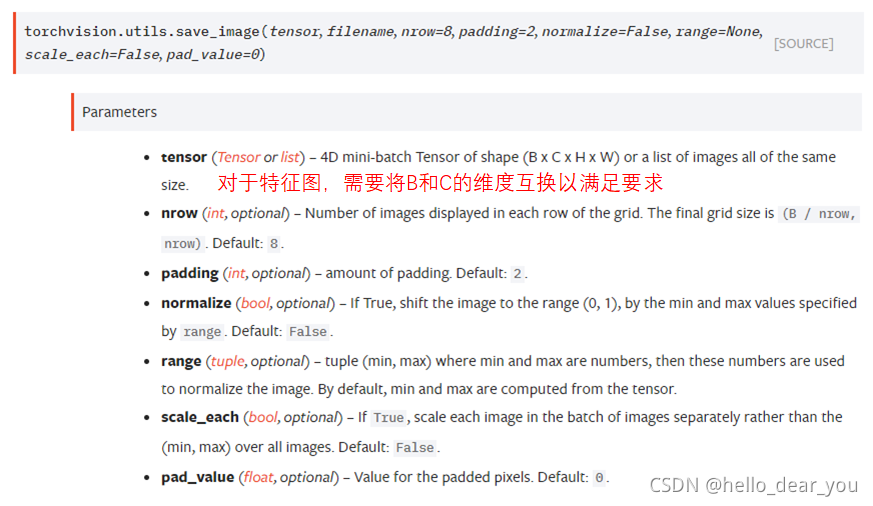
利用save_image可以将单个通道的特征图拼接,并直接保存到磁盘上。
2. VGG可视化特征图示例
- 输入图像example.jpg

- 代码
- import torch
- from torch import nn
- from torchvision import models, transforms
- from PIL import Image
- from torchvision.utils import make_grid, save_image
- import os
- # model
- net = models.vgg16_bn(pretrained=True).cuda()
- # image pre-process
- transforms_input = transforms.Compose([transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
-
- fImg = Image.open("input_image.jpg").convert('RGB')
- data = transforms_input(fImg).unsqueeze(0).cuda()
- # feature image save path
- FEATURE_FOLDER = "./outputs/features"
- if not os.path.exists(FEATURE_FOLDER):
- os.mkdir(FEATURE_FOLDER)
- # three global vatiable for feature image name
- feature_list = list()
- count = 0
- idx = 0
-
- def get_image_path_for_hook(module):
- global count
- image_name = feature_list[count] + ".png"
- count += 1
- image_path = os.path.join(FEATURE_FOLDER, image_name)
- return image_path
-
- def hook_func(module, input, output):
- image_path = get_image_path_for_hook(module)
- data = output.clone().detach()
- global idx
- print(idx, "->", data.shape)
- idx+=1
- data = data.data.permute(1, 0, 2, 3)
- save_image(data, image_path, normalize=False)
-
- for name, module in net.named_modules():
-
- if isinstance(module, torch.nn.Conv2d):
- print(name)
- feature_list.append(name)
- module.register_forward_hook(hook_func)
-
- out = net(data)

- 输出log
通过输出的log可以了解到哪些符合要求的特征图以及它们的大小被打印出来了。
通过下面两行代码可以得到VGG网络中的所有module以及它们的name,可用于后续的对比验证保存得到的特征图结果时候正确。
- for name, layer in net.named_modules():
- print(name, '->', layer)
- features.0 -> Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.1 -> BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.2 -> ReLU(inplace=True)
- features.3 -> Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.4 -> BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.5 -> ReLU(inplace=True)
- features.6 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- features.7 -> Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.8 -> BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.9 -> ReLU(inplace=True)
- features.10 -> Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.11 -> BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.12 -> ReLU(inplace=True)
- features.13 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- features.14 -> Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.15 -> BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.16 -> ReLU(inplace=True)
- features.17 -> Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.18 -> BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.19 -> ReLU(inplace=True)
- features.20 -> Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.21 -> BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.22 -> ReLU(inplace=True)
- features.23 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- features.24 -> Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.25 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.26 -> ReLU(inplace=True)
- features.27 -> Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.28 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.29 -> ReLU(inplace=True)
- features.30 -> Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.31 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.32 -> ReLU(inplace=True)
- features.33 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- features.34 -> Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.35 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.36 -> ReLU(inplace=True)
- features.37 -> Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.38 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.39 -> ReLU(inplace=True)
- features.40 -> Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- features.41 -> BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- features.42 -> ReLU(inplace=True)
- features.43 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
输出特征图的结果
- features.3.png
- feature.17.png


通过上述的分析过程,可以得到VGG网络中不同卷积层输出的特征图,同时可以修改module的匹配原则得到其他类型层的输出,也即在合适的module后面添加本文的hook_func函数就可以对其特征图进行可视化。
参考链接
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/340879
推荐阅读
相关标签

