
- 1关于GPT-4:GPT-4 Technical Report
- 2详解GloVe词向量模型
- 3国内首场高规格AIGC峰会盛况出圈!万字干货热聊GPT-4时代,浓缩21位大牛演讲_nolibox 汽车 合作
- 4浅谈Javascript虚拟列表(virtaul list)改造成虚拟表格(virtaul table)的技术
- 5数据中台之调度系统技术选型和调研_中台数据传输调度
- 6FreeRTOS_时间管理_freertos 时间
- 7Git统计个人提交代码行数 -- 转载_git 统计每人提交代码行数
- 8我的AS学习之路(Logcat)_as logcat 几个参数的意义
- 9如何在调用国内大模型(文心一言、chatglm等)第一篇_glm 模型 调用
- 10导入spring需要的相关依赖包_org.springframework.http 引入哪个依赖
2020-2023小样本学习(FSL)顶会论文及开源代码合集(已分类整理)_小样本鲁棒学习
赞
踩
这次分享的是近四年(2020-2023)各大顶会中的小样本学习(FSL)论文,有160+篇,涵盖了FSL三大类方法:数据、模型、算法,以及FSL的应用、技术、理论等领域。
由于论文数量太多,我就不一一分析总结了,建议大家收藏下慢慢研读。
全部160+篇论文原文及开源代码文末直接领取。
数据(12篇)
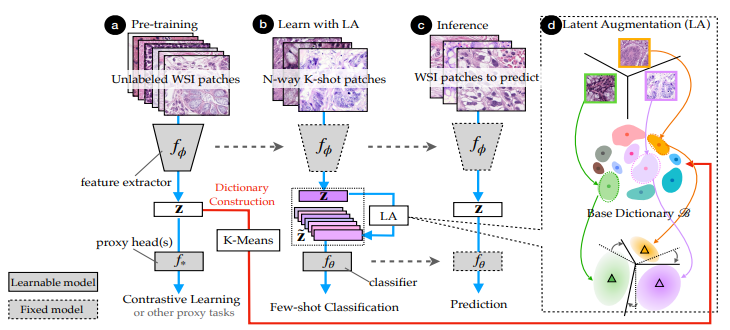
Towards better understanding and better generalization of low-shot classification in histology images with contrastive learning
标题:通过对比学习来更好地理解和提高组织病理图像中的小样本分类的泛化能力
方法介绍:本文通过设置三个跨域任务来推动组织病理图像的小样本学习研究,模拟实际临床问题。为实现高效标注和更好的泛化能力,作者提出结合对比学习和潜在增强来构建小样本系统。对比学习可以在无手动标注下学习有用表示,而潜在增强以非监督方式传递基数据集的语义变化。这两者可充分利用无标注训练数据,可扩展到其他数据饥渴问题。
-
FlipDA: Effective and robust data augmentation for few-shot learning
-
PromDA: Prompt-based data augmentation for low-resource NLU tasks
-
Generating representative samples for few-shot classification
-
FeLMi : Few shot learning with hard mixup
-
Understanding cross-domain few-shot learning based on domain similarity and few-shot difficulty
-
Label hallucination for few-shot classification
-
STUNT: Few-shot tabular learning with self-generated tasks from unlabeled tables
-
Unsupervised meta-learning via few-shot pseudo-supervised contrastive learning
-
Progressive mix-up for few-shot supervised multi-source domain transfer
-
Cross-level distillation and feature denoising for cross-domain few-shot classification
-
Tuning language models as training data generators for augmentation-enhanced few-shot learning
模型(35篇)
多任务学习
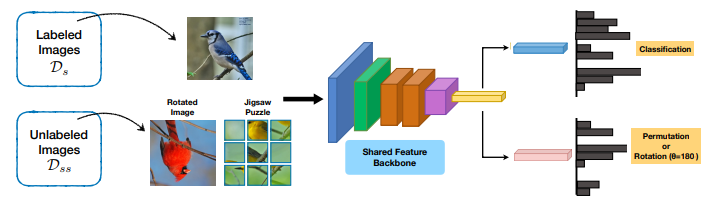
When does self-supervision improve few-shot learning?
标题:自监督学习在什么情况下可以改进小样本学习?
方法介绍:虽然自监督学习的收益可能随着更大的训练数据集而增加,但我们也观察到,当用于元学习和自监督的图像分布不同时,自监督学习实际上可能会损害性能。通过系统地变化域移度和在多个域上分析几种元学习算法的性能,作者进行了详细的分析研究。基于这一分析,作者提出了一种从大规模通用无标注图像池中自动选择适合特定数据集的自监督学习图像的技术,可以进一步改进性能。
-
Pareto self-supervised training for few-shot learning
-
Bridging multi-task learning and meta-learning: Towards efficient training and effective adaptation
-
Task-level self-supervision for cross-domain few-shot learning
嵌入/度量学习
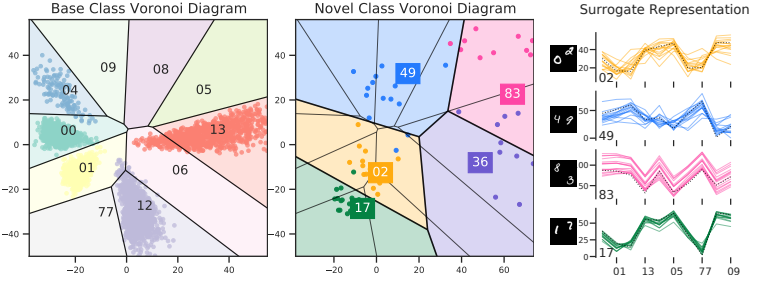
Few-shot learning as cluster-induced voronoi diagrams: A geometric approach
标题:将小样本学习视为由簇诱导的Voronoi图:一种几何方法
方法介绍:小样本学习仍面临泛化能力不足的挑战,本文从几何视角出发,发现流行的 ProtoNet 模型本质上是特征空间中的 Voronoi 图。通过利用“由簇诱导的 Voronoi 图”的技术,可以逐步改进空间分割,在小样本学习的多个阶段提升准确率和鲁棒性。这一基于该图的框架数学优雅、几何可解释,可以补偿极端数据不足,防止过拟合,并实现快速几何推理。
-
Few-shot learning with siamese networks and label tuning
-
Matching feature sets for few-shot image classification
-
EASE: Unsupervised discriminant subspace learning for transductive few-shot learning
-
Cross-domain few-shot learning with task-specific adapters
-
Rethinking generalization in few-shot classification
-
Hybrid graph neural networks for few-shot learning
-
Hubs and hyperspheres: Reducing hubness and improving transductive few-shot learning with hyperspherical embeddings
-
Revisiting prototypical network for cross domain few-shot learning
-
Transductive few-shot learning with prototype-based label propagation by iterative graph refinement
-
Few-sample feature selection via feature manifold learning
-
Interval bound interpolation for few-shot learning with few tasks
-
A closer look at few-shot classification again
-
TART: Improved few-shot text classification using task-adaptive reference transformation
外部存储器辅助学习
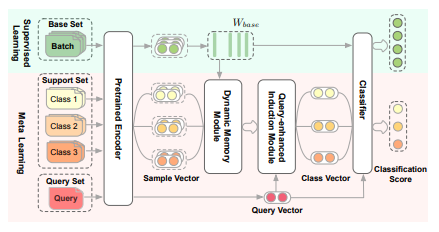
Dynamic memory induction networks for few-shot text classification
标题:动态记忆诱导网络用于短文本分类
方法介绍:本文提出了动态记忆诱导网络,用于短文本的少样本分类。该模型利用动态路由为基于记忆的少样本学习提供更大灵活性,以便更好地适应支持集,这是少样本分类模型的关键能力。在此基础上,作者进一步开发了包含查询信息的诱导模型,旨在增强元学习的泛化能力。
-
Few-shot visual learning with contextual memory and fine-grained calibration
-
Learn from concepts: Towards the purified memory for few-shot learning
-
Prototype memory and attention mechanisms for few shot image generation
-
Hierarchical variational memory for few-shot learning across domains
-
Remember the difference: Cross-domain few-shot semantic segmentation via meta-memory transfer
-
Consistent prototype learning for few-shot continual relation extraction
生成式建模
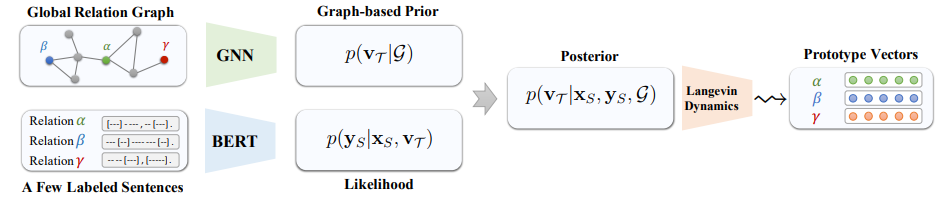
Few-shot relation extraction via bayesian meta-learning on relation graphs
标题:通过关系图上的贝叶斯元学习实现短文本关系提取
方法介绍:作者提出了一种新的贝叶斯元学习方法,用于有效学习关系原型向量的后验分布,其中关系原型向量的先验由定义在全局关系图上的图神经网络参数化。此外,为了有效优化原型向量的后验分布,作者使用了相关于MAML算法的随机梯度兰weibo乎动力学,它可以处理原型向量的不确定性,整个框架可以端到端高效优化。
-
Interventional few-shot learning
-
Modeling the probabilistic distribution of unlabeled data for one-shot medical image segmentation
-
SCHA-VAE: Hierarchical context aggregation for few-shot generation
-
Diversity vs. Recognizability: Human-like generalization in one-shot generative models
-
Generalized one-shot domain adaptation of generative adversarial networks
-
Towards diverse and faithful one-shot adaption of generative adversarial networks
-
Few-shot cross-domain image generation via inference-time latent-code learning
-
Adaptive IMLE for few-shot pretraining-free generative modelling
-
MetaModulation: Learning variational feature hierarchies for few-shot learning with fewer tasks
算法(24篇)
优化已有参数
-
Revisit finetuning strategy for few-shot learning to transfer the emdeddings
-
Prototypical calibration for few-shot learning of language models
-
Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners
-
Supervised masked knowledge distillation for few-shot transformers
-
Hint-Aug: Drawing hints from foundation vision transformers towards boosted few-shot parameter-efficient tuning
-
Few-shot learning with visual distribution calibration and cross-modal distribution alignment
-
MetricPrompt: Prompting model as a relevance metric for few-shot text classification
-
Multitask pre-training of modular prompt for chinese few-shot learning
-
Cold-start data selection for better few-shot language model fine-tuning: A prompt-based uncertainty propagation approach
-
Instruction induction: From few examples to natural language task descriptions
-
Hierarchical verbalizer for few-shot hierarchical text classification
优化元学习中的参数
-
How to train your MAML to excel in few-shot classification
-
Meta-learning with fewer tasks through task interpolation
-
Dynamic kernel selection for improved generalization and memory efficiency in meta-learning
-
What matters for meta-learning vision regression tasks?
-
Stochastic deep networks with linear competing units for model-agnostic meta-learning
-
Robust meta-learning with sampling noise and label noise via Eigen-Reptile
-
Attentional meta-learners for few-shot polythetic classification
-
PLATINUM: Semi-supervised model agnostic meta-learning using submodular mutual information
-
FAITH: Few-shot graph classification with hierarchical task graphs
-
A contrastive rule for meta-learning
-
Meta-ticket: Finding optimal subnetworks for few-shot learning within randomly initialized neural networks
学习搜索步骤
-
Optimization as a model for few-shot learning
-
Meta Navigator: Search for a good adaptation policy for few-shot learning
应用(57篇)
计算机视觉
-
Analogy-forming transformers for few-shot 3D parsing
-
Universal few-shot learning of dense prediction tasks with visual token matching
-
Meta learning to bridge vision and language models for multimodal few-shot learning
-
Few-shot geometry-aware keypoint localization
-
AsyFOD: An asymmetric adaptation paradigm for few-shot domain adaptive object detection
-
A strong baseline for generalized few-shot semantic segmentation
-
StyleAdv: Meta style adversarial training for cross-domain few-shot learning
-
DiGeo: Discriminative geometry-aware learning for generalized few-shot object detection
-
Hierarchical dense correlation distillation for few-shot segmentation
-
CF-Font: Content fusion for few-shot font generation
-
MoLo: Motion-augmented long-short contrastive learning for few-shot action recognition
-
MIANet: Aggregating unbiased instance and general information for few-shot semantic segmentation
-
FreeNeRF: Improving few-shot neural rendering with free frequency regularization
-
Exploring incompatible knowledge transfer in few-shot image generation
-
Where is my spot? few-shot image generation via latent subspace optimization
-
FGNet: Towards filling the intra-class and inter-class gaps for few-shot segmentation
-
GeCoNeRF: Few-shot neural radiance fields via geometric consistency
机器人技术
-
One solution is not all you need: Few-shot extrapolation via structured MaxEnt RL
-
Bowtie networks: Generative modeling for joint few-shot recognition and novel-view synthesis
-
Demonstration-conditioned reinforcement learning for few-shot imitation
-
Hierarchical few-shot imitation with skill transition models
-
Prompting decision transformer for few-shot policy generalization
-
Stage conscious attention network (SCAN): A demonstration-conditioned policy for few-shot imitation
-
Online prototype alignment for few-shot policy transfer
自然语言处理
-
A dual prompt learning framework for few-shot dialogue state tracking
-
CLUR: Uncertainty estimation for few-shot text classification with contrastive learning
-
Few-shot document-level event argument extraction
-
MetaAdapt: Domain adaptive few-shot misinformation detection via meta learning
-
Code4Struct: Code generation for few-shot event structure prediction
-
MANNER: A variational memory-augmented model for cross domain few-shot named entity recognition
-
Few-shot event detection: An empirical study and a unified view
-
CodeIE: Large code generation models are better few-shot information extractors
-
Few-shot in-context learning on knowledge base question answering
-
Linguistic representations for fewer-shot relation extraction across domains
-
Few-shot reranking for multi-hop QA via language model prompting
知识图谱
-
Adaptive attentional network for few-shot knowledge graph completion
-
Learning inter-entity-interaction for few-shot knowledge graph completion
-
Few-shot relational reasoning via connection subgraph pretraining
-
Hierarchical relational learning for few-shot knowledge graph completion
-
The unreasonable effectiveness of few-shot learning for machine translation
声音信号处理
-
Audio2Head: Audio-driven one-shot talking-head generation with natural head motion
-
Few-shot low-resource knowledge graph completion with multi-view task representation generation
-
Normalizing flow-based neural process for few-shot knowledge graph completion
推荐系统
-
Few-shot news recommendation via cross-lingual transfer
-
ColdNAS: Search to modulate for user cold-start recommendation
-
Contrastive collaborative filtering for cold-start item recommendation
-
SMINet: State-aware multi-aspect interests representation network for cold-start users recommendation
-
Multimodality helps unimodality: Cross-modal few-shot learning with multimodal models
-
M2EU: Meta learning for cold-start recommendation via enhancing user preference estimation
-
Aligning distillation for cold-start item recommendation
其他
-
Context-enriched molecule representations improve few-shot drug discovery
-
Sequential latent variable models for few-shot high-dimensional time-series forecasting
-
Transfer NAS with meta-learned Bayesian surrogates
-
Few-shot domain adaptation for end-to-end communication
-
Contrastive meta-learning for few-shot node classification
-
Task-equivariant graph few-shot learning
-
Leveraging transferable knowledge concept graph embedding for cold-start cognitive diagnosis
理论(7篇)
-
Bridging the gap between practice and PAC-Bayes theory in few-shot meta-learning
-
bounds for meta-learning: An information-theoretic analysis
-
Generalization bounds for meta-learning via PAC-Bayes and uniform stability
-
Unraveling model-agnostic meta-learning via the adaptation learning rate
-
On the importance of firth bias reduction in few-shot classification
-
Global convergence of MAML and theory-inspired neural architecture search for few-shot learning
-
Smoothed embeddings for certified few-shot learning
小样本/零样本学习(15篇)
-
Finetuned language models are zero-shot learners
-
Zero-shot stance detection via contrastive learning
-
JointCL: A joint contrastive learning framework for zero-shot stance detection
-
Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification
-
Nearest neighbor zero-shot inference
-
Continued pretraining for better zero- and few-shot promptability
-
InstructDial: Improving zero and few-shot generalization in dialogue through instruction tuning
-
Prompt-and-Rerank: A method for zero-shot and few-shot arbitrary textual style transfer with small language models
-
Learning instructions with unlabeled data for zero-shot cross-task generalization
-
Zero-shot cross-lingual transfer of prompt-based tuning with a unified multilingual prompt
-
Finetune like you pretrain: Improved finetuning of zero-shot vision models
-
SemSup-XC: Semantic supervision for zero and few-shot extreme classification
-
Zero- and few-shot event detection via prompt-based meta learning
-
HINT: Hypernetwork instruction tuning for efficient zero- and few-shot generalisation
-
What does the failure to reason with "respectively" in zero/few-shot settings tell us about language models? acl 2023
小样本学习变体(12篇)
-
FiT: Parameter efficient few-shot transfer learning for personalized and federated image classification
-
Towards addressing label skews in one-shot federated learning
-
Data-free one-shot federated learning under very high statistical heterogeneity
-
Contrastive meta-learning for partially observable few-shot learning
-
On the soft-subnetwork for few-shot class incremental learning
-
Warping the space: Weight space rotation for class-incremental few-shot learning
-
Neural collapse inspired feature-classifier alignment for few-shot class-incremental learning
-
Learning with fantasy: Semantic-aware virtual contrastive constraint for few-shot class-incremental learning
-
Few-shot class-incremental learning via class-aware bilateral distillation
-
Glocal energy-based learning for few-shot open-set recognition
-
Open-set likelihood maximization for few-shot learning
-
Federated few-shot learning
数据集/基准(5篇)
-
FewNLU: Benchmarking state-of-the-art methods for few-shot natural language understanding
-
Bongard-HOI: Benchmarking few-shot visual reasoning for human-object interactions
-
Hard-Meta-Dataset++: Towards understanding few-shot performance on difficult tasks
-
MEWL: Few-shot multimodal word learning with referential uncertainty
-
UNISUMM and SUMMZOO: Unified model and diverse benchmark for few-shot summarization
关注下方【学姐带你玩AI】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

