
- 1通过修改ipa文件包修改文件名的方法_sideloadly改名
- 2常用的数据统计Sql 总结(转)
- 3vue 将base64 的文件流转换成pdf 并预览、下载, 兼容 IE10+_vue下载base64的pdf到本地
- 4[android开发中使用的小技巧]修改FileSystem权限_filesystem “vdo” on device
- 5优化器介绍—SGD、Adam、Adagrad_adam和sgd
- 6自然语言处理文本分析_通过自然语言处理释放文本分析的力量
- 7第三方录像机添加宇视摄像机配置指导_vsd摄像机加入宇视录像机
- 8BERTopic详细安装教程_bertopic安装
- 9对接kafka_kafka-connect 架构组成
- 10用Python玩转办公室小技巧
基于生成对抗网络GAN的应用:超分辨率网络SRGAN【简洁清晰!】_srgan原理
赞
踩
超分辨率网络SRGAN
一、SRGAN原理
SRGAN是一种深度学习模型,旨在从低分辨率图像中生成高分辨率图像。它是通过将生成对抗网络(GAN)与残差网络(Residual Network)结合而成的。GAN的生成器网络负责将低分辨率图像映射到高分辨率图像空间,而鉴别器网络则试图区分生成的高分辨率图像和真实高分辨率图像之间的区别。通过这种对抗训练的方式,生成器网络逐渐学会生成更加逼真的高分辨率图像。
关于GAN的简单原理介绍以及基于Pytorch的代码实现,可见我上一篇博客:GAN生成对抗网络原理分析以及Pytorch的代码实现【简单配置环境,直接拷贝代码即可运行!!】
二、网络结构
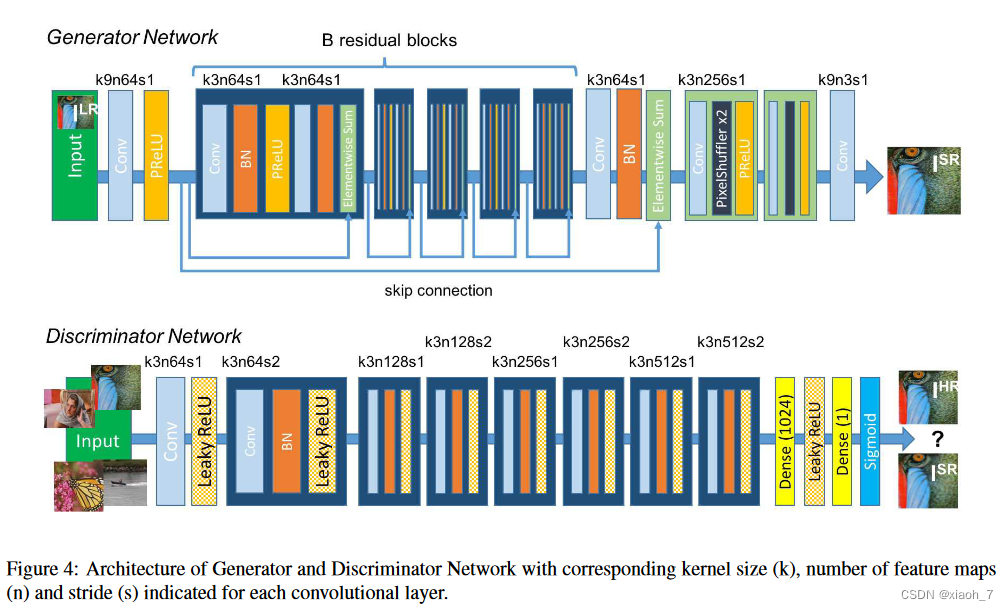
上面为生成器,backbone是residual blocks(Resnet),LR(也就是低分辨率图像)输入之后,先通过一个卷积进行粗级特征提取,然后通过一系列的residual blocks进行细节特征的学习,有一个long skit connnection,最后对得到的特征图进行亚像素卷积操作、卷积重建,图像分辨率提高,G网络输出的也就是SR。下面为判别器。
三、公式
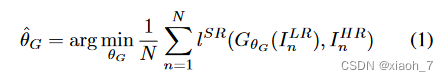
网络的优化方向就是找到一个合适的网络权重(也就是模型参数),使得生成的超分辨率图像跟原始的高分辨率直接的差异尽可能小。
网络的损失主要由三部分组成
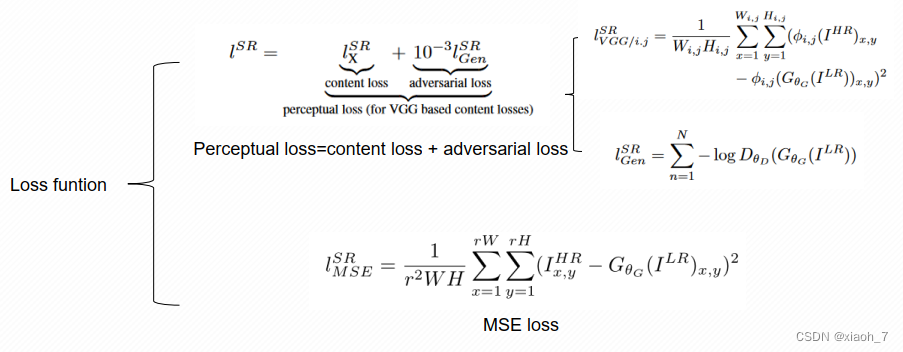
1. 生成器损失
生成器的损失由两部分组成:对抗损失和感知损失。
-
对抗损失(Adversarial Loss):鼓励生成的高分辨率图像与真实高分辨率图像之间的分布尽可能接近。
[ L_{adv}(G, D) = \mathbb{E}{x\sim p{\text{data}}(x)}[\log(D(x))] + \mathbb{E}_{z\sim p_z(z)}[\log(1 - D(G(z)))] ]
-
感知损失(Perceptual Loss):通过预训练的特征提取器(如VGG网络)来衡量生成的高分辨率图像与真实高分辨率图像之间的感知差异。
[ L_{\text{perceptual}}(G) = \mathbb{E}_{x,y}[| \phi(y) - \phi(G(x)) |_1] ]
其中,( \phi ) 是预训练的特征提取器,( x ) 是低分辨率输入图像,( y ) 是真实高分辨率图像,( G(x) ) 是生成器生成的高分辨率图像。
生成器的总损失为对抗损失和感知损失的加权和。
[ L_{G}(G, D) = \lambda_{adv} L_{adv}(G, D) + \lambda_{\text{perceptual}} L_{\text{perceptual}}(G) ]
2. 鉴别器损失
鉴别器的损失旨在区分生成的高分辨率图像和真实高分辨率图像之间的差异。
[ L_{D}(G, D) = -L_{adv}(G, D) ]
四、结论
通过训练生成器和鉴别器网络,SRGAN可以生成更加逼真的高分辨率图像,以改善图像的视觉质量和细节。


