
热门标签
热门文章
- 1python解释器安装手把手指南_python翻译器安装教程
- 2使用批处理批量复制文件并重命名_1个文件复制100分并命名
- 3JMeter学习(三十五)使用jmeter来发送json/gzip格式数据_jmeter 发送 json.stringify
- 4windows 批处理命令大全
- 5如何实现ubuntu每天定时关机
- 6残差网络的搭建_torch.nn.sequential torch.nn.conv2d torch.nn.cross
- 7SpringMVC源码解读 --- 处理器适配器 - 3 源码解读前置知识WebDataBinder的父子结构及源码分析_checkfieldmarkers()
- 87-22 龟兔赛跑_乌龟与兔子进行赛跑,跑场是一个矩型跑道,跑道边可以随地进行休息。乌龟每分钟可以
- 9云计算基础(云计算概述)
- 10FFMPEG数据结构_ffopgtg
当前位置: article > 正文
机器学习1一knn算法
作者:AllinToyou | 2024-02-16 05:25:58
赞
踩
机器学习1一knn算法
1.基础知识点介绍



曼哈顿距离一般是比欧式距离长的除非在一维空间
拐弯的就是曼哈顿距离

Knn查看前5行数据head(),info看空非空
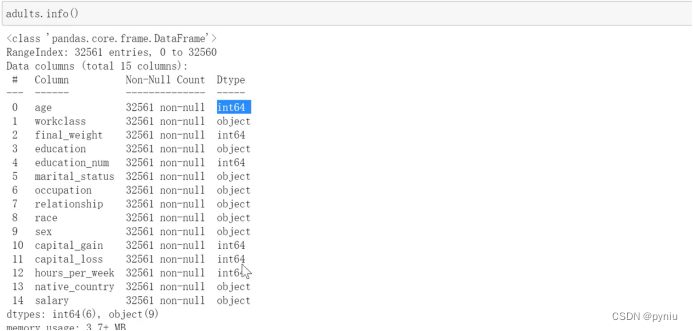
查看特征对应的类型

Head()默认前5行,head(3)就是前3行数据
Unique()可以查看分类后的结果
csv的数据应该是逗号分隔,但也不确定,要去查看数据不要只看拓展名要点进去看一下
这个删掉没有把原数据删掉

如果把原数据删掉加上inplace=true
- #练习1 导入数据分析三剑客
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- #导入KNN算法
- #sklearn机器学习库,KNeighborsClassifier :KNN分类器
- from sklearn.neighbors import KNeighborsClassifier
-
- ### 1. k-近邻算法原理
- #简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(K-Nearest Neighbor,KNN)
- ##### 工作原理 **欧几里得距离(Euclidean Distance)**欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。
- knn优缺点
-
- #- 优点:精度高、对异常值不敏感。
- #- 缺点:时间复杂度高、空间复杂度高。
- #### 2. 在scikit-learn库中使用k-近邻算法
- #- 分类问题:from sklearn.neighbors import KNeighborsClassifier
-
- #- 回归问题:from sklearn.neighbors import KNeighborsRegressor
- #导入电影数据
- movie=pd.read_excel('../data/movies.xlsx',sheet_name=1)
- movie
- #中文不可以训练,电影名称从业务的角度也不能拿来训练
- data=movie[['武大镜头','接吻镜头']].copy()
- data #必须是二维数据
- # target (label) 标签,标记,目标结果
- target=movie.分类情况
- target
- data.shape,target.shape
- # 使用KNN算法
-
- # 1. 创建KNN对象
- # n_neighbors=5 : K=5,会找最近的5个近邻
- # p=2:默认值,表示使用欧式距离,p=1表示曼哈顿距离
- knn=KNeighborsClassifier(n_neighbors=5,p=2)
- knn
- # 2. 训练 : 训练历史数据
- # 数据:
- # 训练数据: 用来训练
- # 测试数据:或验证数据,用来测试或验证模型的好坏
-
- # X :必须是二维数据
- # y :结果,一般是一维
- knn.fit(X=data,y=target)
- data
- # 3. 预测新数据
- # 提供测试数据
- X_test=np.arry([[50, 1], [1, 20], [30, 1], [2, 10], [20, 10]])
- X_test=pd.DataFrame(X_test,columns=data.columns)
- y_test=np.array(['动作片', '爱情片', '动作片', '爱情片', '动作片'])
- # 预测:predict
- y_pred=knn.predict(X_test)
- y_pred
- # 4. 计算得分: 准确率
- knn.score(X_test,y_test)
- 总结:# 数据
- # data, target : 一般表示全部数据
-
- # 训练数据
- # X_train : 训练集中的数据
- # y_train :训练集中的数据对应的结果
- #
- # 预测数据
- # X_test : 测试集中的数据
- # y_test : 测试集中的数据对应的真实结果
- # y_pred : 测试集中的数据对应的预测结果

- #from sklearn.datasets:提供现成的数据集,主要用来学习和测试
-
- #导入数据
- import pandas as pd
- import numpy as np
- from sklearn.datasets import load_iris
- from sklearn.neighbors import KNeighborsClassifier
- iris=load_iris()
- iris
- data=iris['data']
- target=iris['target']
- target_names=iris['target_names']
- feature_names=iris['feature_names']
- data.shape,target.shape
- target
- target_names
- feature_names
- pd.DataFrame(data,columns=feature_names)
- #拆分数据集
- from sklearn.model_selection import train_test_split
-
- # test_size 有2种写法:
- # 1. int整数,那么就表示使用这么多的数据作为测试数据
- # 2. float小数,0-1之间,测试数据占所有数据的比重, 比如:0.2 = 150*20% = 20
-
- # 训练数据: X_train, y_train
- # 测试数据: X_test, y_test
- x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.2)
- display(x_train.shape,x_test.shape)
- #使用knn算法knn = KNeighborsClassifier()
- #1.创建knn
- knn=KNeighborsClassifier()
- #2.训练
- knn.fit(x_train,y_train)
- #3.预测
- y_pred=knn.predict(x_test)
- y_pred
- #得分
- knn.score(x_test,y_test)
- #4. 拆分数据集:训练数据和预测数据
- # - train_test_split
- import numpy as np
- import pandas as pd
- #import matplotlib.pyplot as plt
- from sklearn.neighbors import KNeighborsClassifier
- x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.2)
- x_train.shape,x_test.shape
- #使用knn算法
- knn=KNeighborsClassifier()
- knn.fit(x_train,y_train)
- #预测
- knn = KNeighborsClassifier()
- knn.fit(x_train,y_train)
- #预测
- knn.predict(x_test)
- #得分
- knn.score(x_test,y_test)
- #6. 保存训练模型
- # - import joblib
- # - 保存模型: joblib.dump(knn, 'knn.plk')
- # - 导入模型: joblib.load('knn.plk')
- import joblib
- joblib.dump(knn,'knn.plk')
- #导入模型
- new_knn=joblib.load('knn.plk')
- new_knn
- #预测
- new_knn.predict(x_test)
-
- #### 3、癌症预测
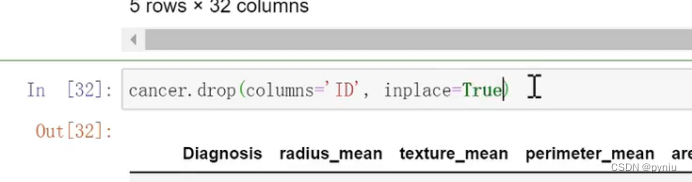
- #- 读取cancer.csv文件
- #- 删除列: 'ID'
- #- Diagnosis 是target
- #- 使用train_test_split
- #- 使用KNN训练,并预测
- #- 交叉表查看结果pd.crosstab( )
- import pandas as pd
- import numpy as np
- from sklearn.model_selection import train_test_split
- from sklearn.neighbors import KNeighborsClassifier
- cancer=pd.read_table('../data/cancer.csv')
- cancer.shape
- cancer.head()
- cancer.drop(columns='ID',inplace=True)
- cancer.head(3)
- data=cancer.iloc[:,1:].copy()
- target.unique()
- x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.2)
- #knn
- knn=KNeighborsClassifier()
- knn.fit(x_train,y_train)
- #预测
- y_pred=knn.predict(x_test)
- y_pred
- #得分
- knn.score(x_test,y_test)
- pd.crosstab(
- index=y_pred, #预测结果
- columns=y_test,
- rownames=['预测'],
- colnames=['真实'],
- margins=True
- )
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/91066
推荐阅读
- 相关标签
![[Github] Github 如何发布(release)_github release在哪里](https://img-blog.csdnimg.cn/img_convert/4a1ab8c050264b68b823fdf04301d802.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

